Query Synthesis Methods
Encord Computer Vision Glossary
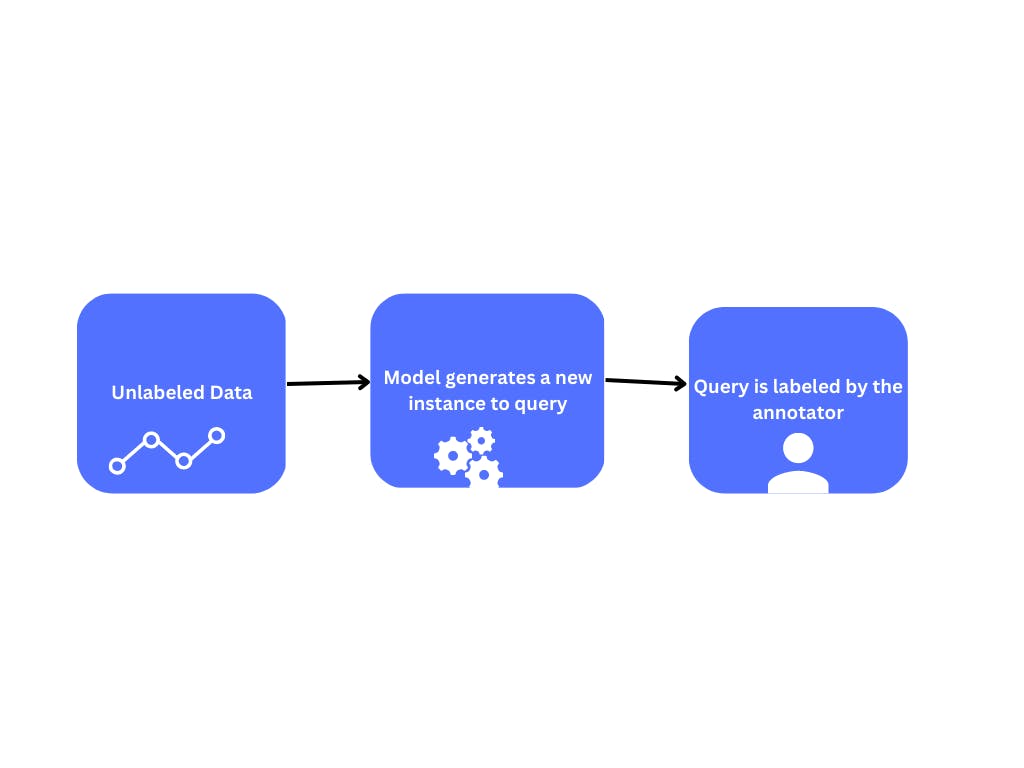
Query synthesis methods are used in active learning to generate informative queries that are presented to a human annotator for labeling. These methods use the current state of the model and the unlabeled data to generate queries that are expected to improve the model's performance.

Some common query synthesis methods include uncertainty sampling, query-by-committee, and expected model change. In uncertainty sampling, the algorithm selects examples that are the most uncertain or ambiguous to the model. In query-by-committee, a group of models is created, and queries are generated based on the disagreement among the models. In expected model change, the algorithm selects examples that are expected to cause the most significant change in the model's predictions.
Query synthesis methods play a crucial role in active learning, allowing for efficient labeling of the most informative examples to improve the model's accuracy while minimizing labeling costs.
Advantages
- Increased data diversity: Query synthesis methods can help increase the diversity of the training data, which can improve the model's performance by reducing overfitting and improving generalization.
- Reduced labeling cost: Like the other query strategies discussed above, query synthesis methods also reduce the need for manual labeling and hence lower the overall labeling cost. These methods achieve this by generating new unlabeled samples.
- Improved model performance: The synthetic samples generated using query synthesis methods can be more representative of the data, which can improve the model’s performance by providing it with more informative and diverse training data.

Disadvantages
- Computational cost: Query synthesis methods can be computationally expensive, especially for complex data types like images or videos. Generating synthetic examples can require significant computational resources, which can limit their applicability in practice.
- Limited quality of the synthetic data: The quality of the synthetic data generated using query synthesis methods depends on the selection of the method and the parameters used. Poor selection of the method or parameters can lead to the generation of synthetic examples that are not representative of the data, which can negatively impact the model's performance.
- Overfitting: Generating too many synthetic examples can lead to overfitting, where the model learns to classify the synthetic examples instead of the actual data. This can reduce the model's performance on new, unseen data.