Back
on demand
on demand
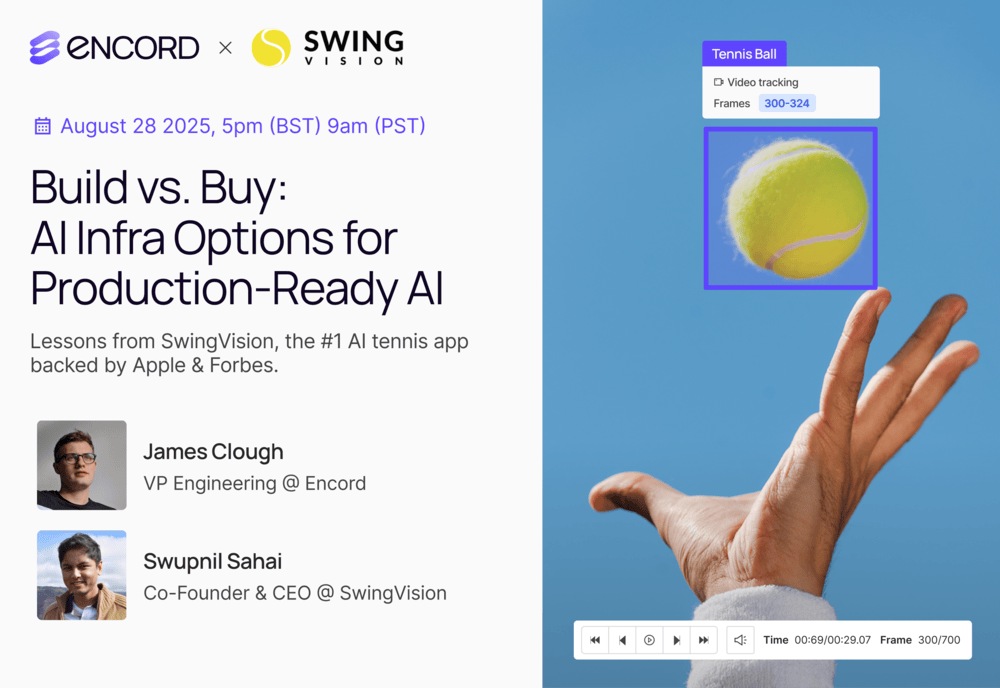
Accelerate VLA Segmentation for Robotics with SAM 3
Tue, Dec 9, 05:00 PM - 05:45 PM UTC
VLA Segmentation for Robotics with SAM 3
Training robots to see and act often requires overcoming messy video data, inconsistent masks, and time-intensive labeling.
In this hands-on masterclass, our ML team will show you how to use SAM 3, the most advanced unified model from Meta, to automate video segmentation, cut annotation time, improve temporal consistency, and scale high-quality perception datasets for VLA and embodied-AI models.
You’ll learn how to:
- Eliminate manual labeling pain by segmenting and tracking moving robots, tools, and objects with automated video workflows.
- Use SAM 3 to boost annotation speed and accuracy using a simple text or visual prompt to generate multiple segmentation masks in an image or video, and track this mask across time.
- Label over time for richer, temporally aware VLA datasets.
- Integrate outputs directly into your robotics or simulation pipeline to fine-tune and evaluate VLA models faster.
Who it’s for:
Robotics engineers, perception teams, and data ops professionals working on autonomous vehicles, warehouse automation, and humanoid robotics who want to streamline their VLA training workflows.
Speakers

Diarmuid McGonagle
Lead Customer Support Engineer
Encord

David Babuschkin
ML Expert & Technical Writer
Encord