Back
on demand
on demand
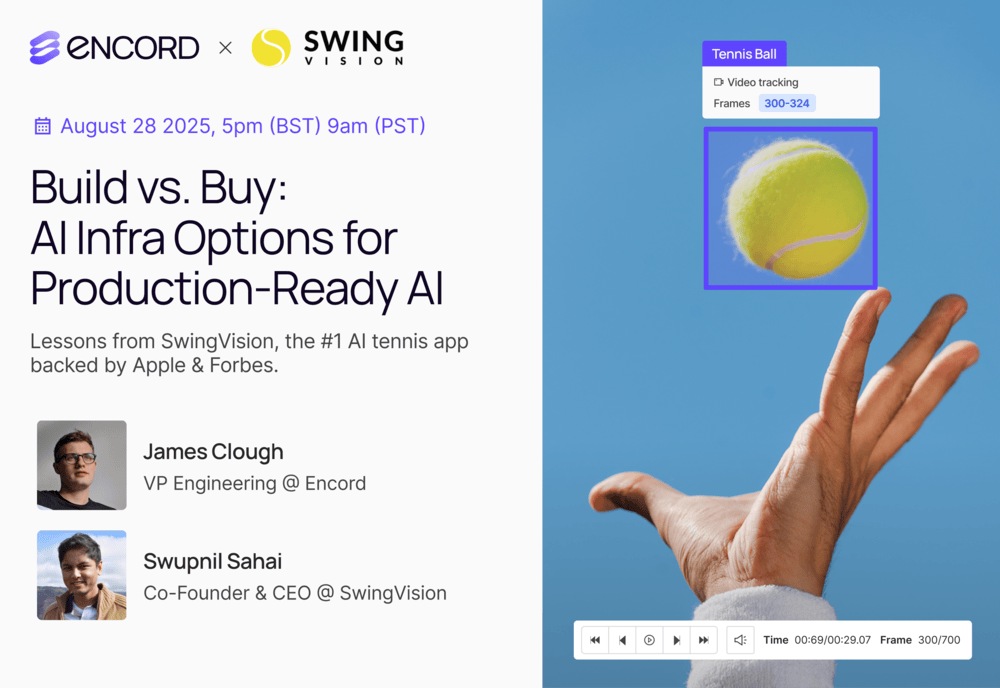
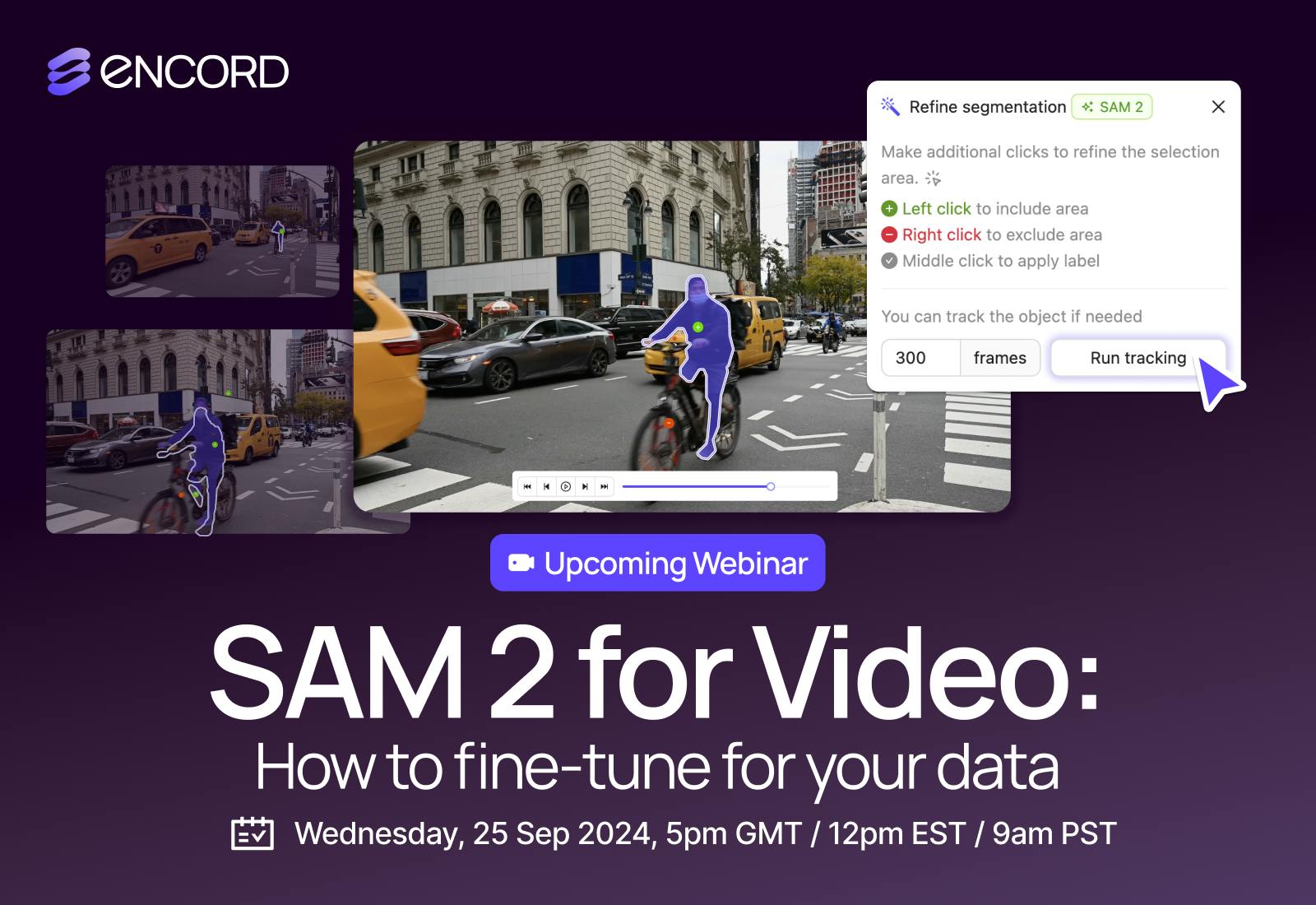
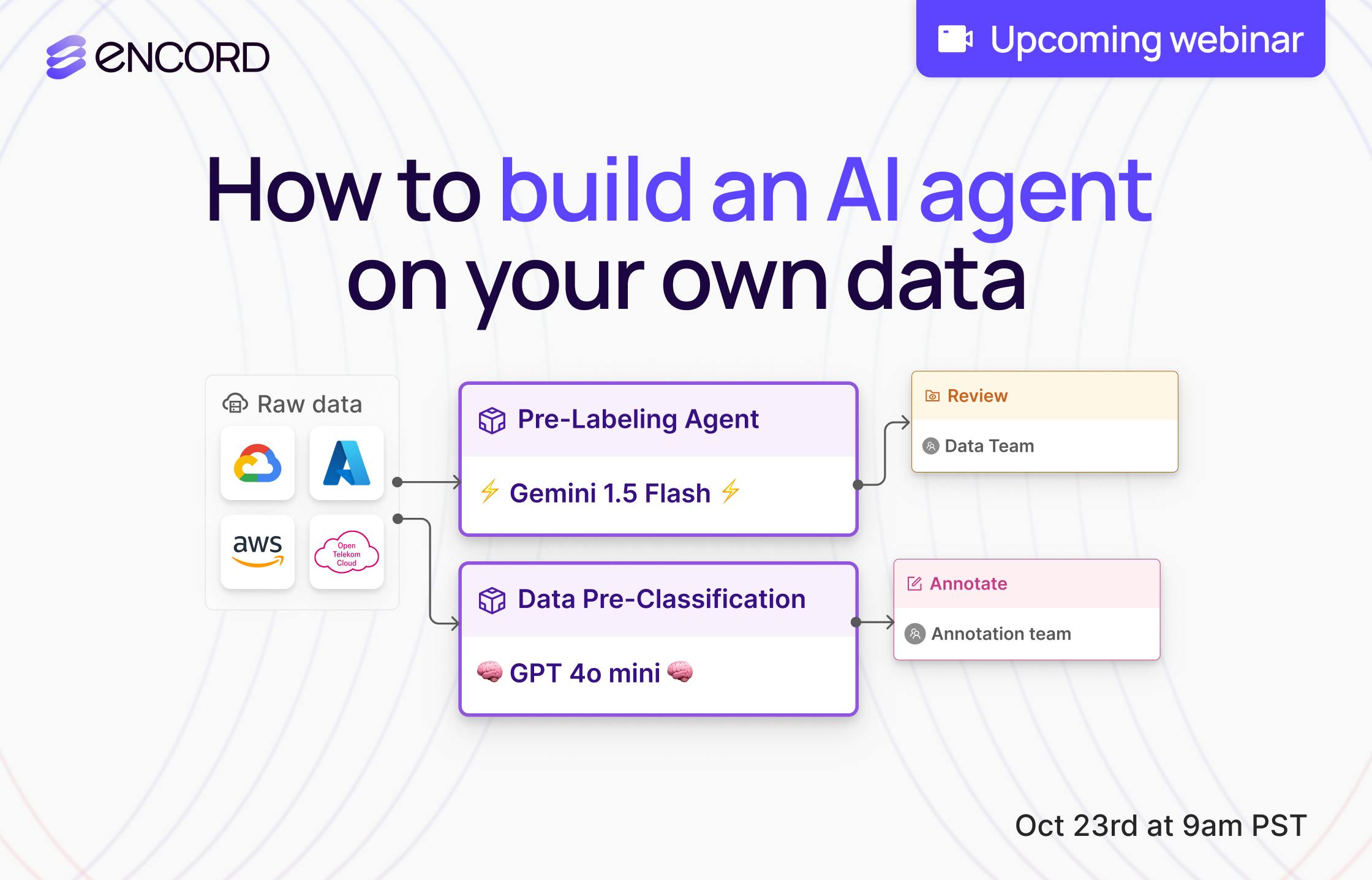
How To Use Agents To Build A Multimodal Data Pipeline
Mon, Dec 16, 05:00 PM - 05:45 PM UTC
About this webinar
Great multimodal models require great multimodal data. Yet, preparing multimodal datasets comes with a variety of challenges and a large amount of manual work.
New Agentic capabilities give AI teams the freedom to automate large quantities of previously manual work.
Join our Machine Learning team to learn how to use AI Agents to automate your multimodal data pipeline
Key Highlights:
- Understand why multimodal AI and AI Agents are shaping the future of technology.
- Learn how to streamline multiple modalities with seamless, automated workflows powered by 'agents-in-the-loop.'
- Watch a live demo showcasing AI Agents creating multimodal training datasets.
Spots are limited to first 250 so don't miss out!
Speakers

Frederik Hvilshøj
ML Lead
Encord

Oscar Evans
ML Solutions Engineer
Encord