Top 8 Alternatives to the Open AI CLIP Model

Multimodal deep learning is a recent trend in artificial intelligence (AI) that is revolutionizing how machines understand the real world using multiple data modalities, such as images, text, video, and audio.
In particular, multiple machine learning frameworks are emerging that exploit visual representations to infer textual descriptions following Open AI’s introduction of the Contrastive Language-Image Pre-Training (CLIP) model.
The improved models use more complex datasets to change the CLIP framework for domain-specific use cases. They also have better state-of-the-art (SoTA) generalization performance than the models that came before them.
This article discusses the benefits, challenges, and alternatives of Open AI CLIP to help you choose a model for your specific domain. The list below mentions the architectures covered:
- Pubmed CLIP
- PLIP
- SigLIP
- Street CLIP
- Fashion CLIP
- CLIP-Rscid
- BioCLIP
- CLIPBert
Open AI CLIP Model
CLIP is an open-source vision-language AI model by OpenAI trained using image and natural language data to perform zero-shot classification tasks. Users can provide textual captions and use the model to assign a relevant label to the query image.
Open AI CLIP Model: Architecture and Development
The training data consists of images from the internet and 32,768 text snippets assigned to each image as its label. The training task involves using natural language processing (NLP) to predict which label goes with which image by understanding visual concepts and relating them to the textual data.
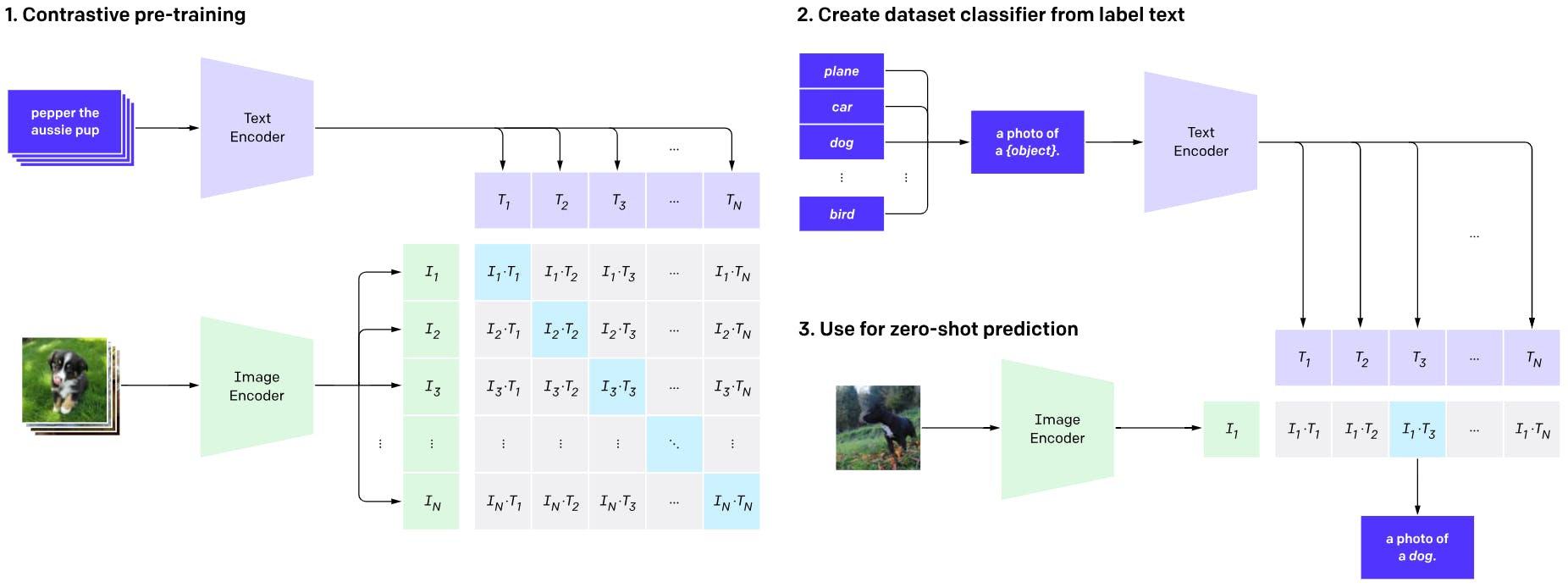
The model primarily uses an image and a text encoder that convert images and labels into embeddings. Optimization involves minimizing a contrastive loss function by computing similarity scores between these embeddings and associating the correct label with an image.
Once trained, the user can provide an unseen image as input with multiple captions to the image and text encoders. CLIP will then predict the correct label that goes with the image.
Benefits of OpenAI CLIP
OpenAI CLIP has multiple benefits over traditional vision models. The list below mentions the most prominent advantages:
- Zero-shot Learning (ZSL): CLIP’s training approach allows it to label unseen images without requiring expensive training on new datasets. Like Generative Pre-trained Transformer - 3 (GPT-3) and GPT-4, CLIP can perform zero-shot classification tasks using natural language data with minimal training overhead. The property also helps users fine-tune CLIP more quickly to adapt to new tasks.
- Better Real-World Performance: CLIP demonstrates better real-world performance than traditional vision models, which only work well with benchmark datasets.
Limitations of OpenAI CLIP
Although CLIP is a robust framework, it has a few limitations, as highlighted below:
- Poor Performance on Fine-grained Tasks: CLIP needs to improve its classification performance for fine-grained tasks such as distinguishing between car models, animal species, flower types, etc.
- Out-of-Distribution Data: While CLIP performs well on data with distributions similar to its training set, performance drops when it encounters out-of-distribution data. The model requires more diverse image pre-training to generalize to entirely novel tasks.
- Inherent Social Bias: The training data used for CLIP consists of randomly curated images with labels from the internet. The approach implies the model learns intrinsic biases present in image captions as the image-text pairs do not undergo filtration.
Due to these limitations, the following section will discuss a few alternatives for domain-specific tasks.
Alternatives to CLIP
Since CLIP’s introduction, multiple vision-language algorithms have emerged with unique capabilities for solving problems in healthcare, fashion, retail, etc.
We will discuss a few alternative models that use the CLIP framework as their base. We will also briefly mention their architecture, development approaches, performance results, and use cases.
1. PubmedCLIP
PubmedCLIP is a fine-tuned version of CLIP for medical visual question-answering (MedVQA), which involves answering natural language questions about an image containing medical information.
PubmedCLIP: Architecture and Development
The model is pre-trained on the Radiology Objects in Context (ROCO) dataset, which consists of 80,000 samples with multiple image modalities, such as X-ray, fluoroscopy, mammography, etc. The image-text pairs come from Pubmed articles; each text snippet briefly describes the image’s content.
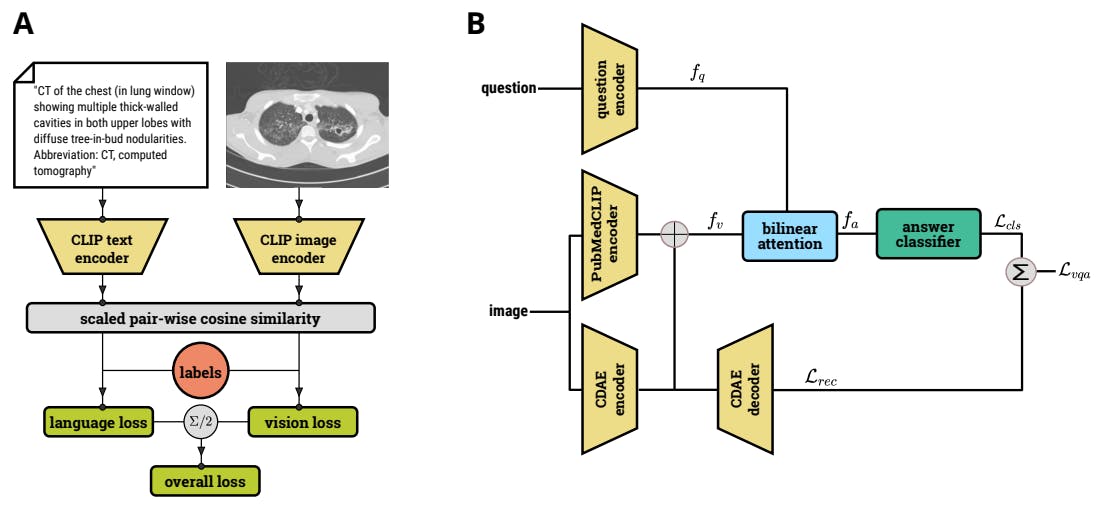
Pre-training includes fine-tuning CLIP’s image and text encoders to minimize contrastive language and vision loss.
The pretrained module, PubMedCLIP, and a Convolutional Denoising Image Autoencoder (CDAE) encode images. A question encoder converts natural language questions into embeddings and combines them with the encoded image through a bilinear attention network (BAN).
The training objective is to map the embeddings with the correct answer by minimizing answer classification and image reconstruction loss using a CDAE decoder.
Performance Results of PubmedCLIP
The accuracy metric shows an improvement of 1% compared to CLIP on the VQA-RAD dataset, while PubMedCLIP with the vision transform ViT-32 as the backend shows an improvement of 3% on the SLAKE dataset.
PubmedCLIP: Use Case
Healthcare professionals can use PubMedCLIP to interpret complex medical images for better diagnosis and patient care.
2. PLIP
The Pathology Language-Image Pre-Training (PLIP) model is a CLIP-based framework trained on extensive, high-quality pathological data curated from open social media platforms such as medical Twitter.
PLIP: Architecture and Development
Researchers used 32 pathology hashtags according to the recommendations of the United States Canadian Academy for Pathology (USCAP) and the Pathology Hashtag Ontology project. The hashtags helped them retrieve relevant tweets containing de-identified pathology images and natural descriptions.
The final dataset - OpenPath - comprises 116,504 image-text pairs from Twitter posts, 59,869 image-text pairs from the corresponding replies with the highest likes, and 32,041 additional image-text pairs from the internet and the LAION dataset.
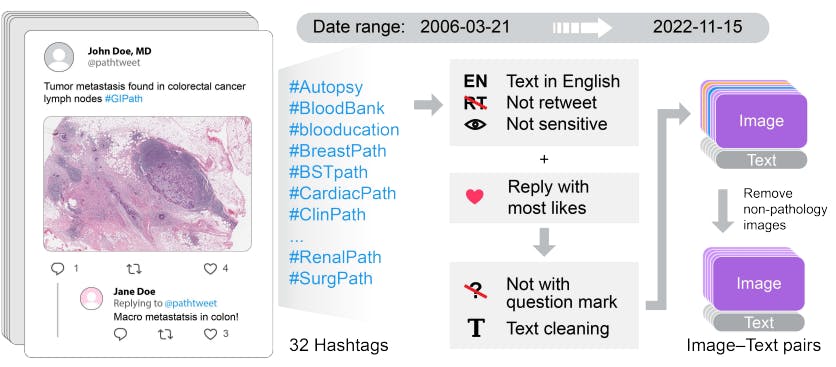
Experts use OpenPath to fine-tune CLIP through an image preprocessing pipeline that involves image down-sampling, augmentations, and random cropping.
Performance Results of PLIP
PLIP achieved state-of-the-art (SoTA) performance across four benchmark datasets. On average, PLIP achieved an F1 score of 0.891, while CLIP scored 0.813.
PLIP: Use Case
PLIP aims to classify pathological images for multiple medical diagnostic tasks and help retrieve unique pathological cases through image or natural language search.
3. SigLip
SigLip uses a more straightforward sigmoid loss function to optimize the training process instead of a softmax contrastive loss as traditionally used in CLIP. The method boosts training efficiency and allows users to scale the process when developing models using more extensive datasets.
SigLip: Architecture and Development
Optimizing the contrastive loss function implies maximizing the distance between non-matching image-text pairs while minimizing the distance between matching pairs.
However, the method requires text-to-image and image-to-text permutations across all images and text captions. It also involves computing normalization factors to calculate a softmax loss.
The approach is computationally expensive and memory-inefficient. Instead, the sigmoid loss simplifies the technique by converting the loss into a binary classification problem by assigning a positive label to matching pairs and negative labels to non-matching combinations.
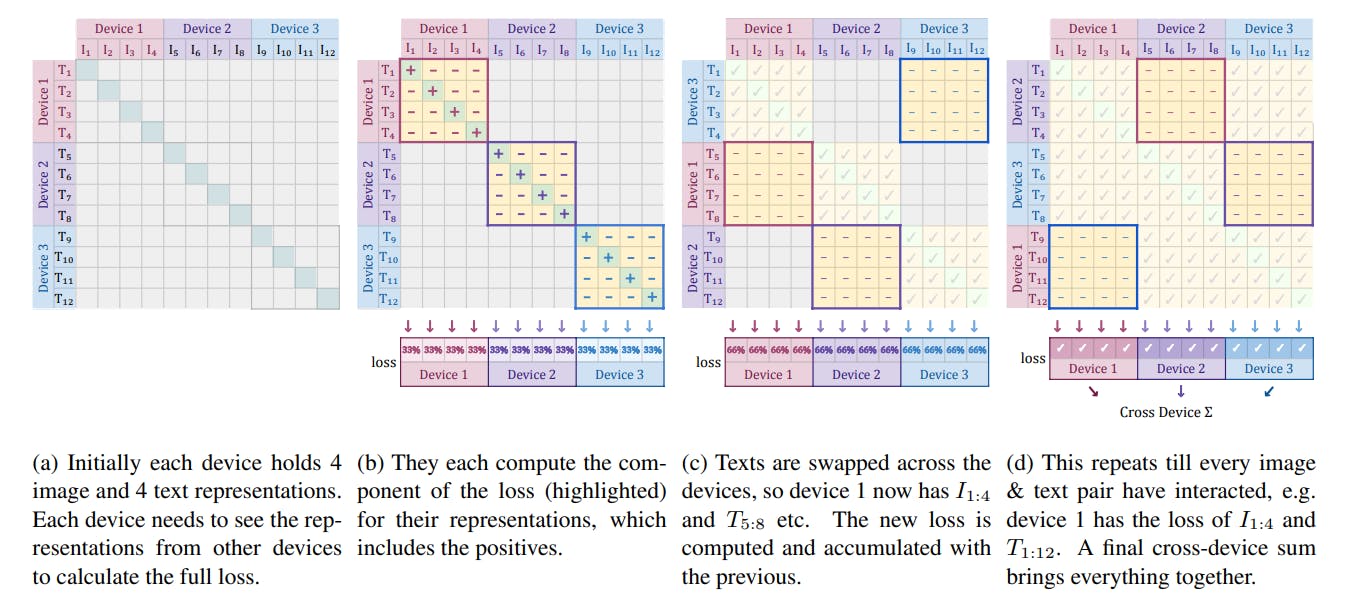
In addition, permutations occur on multiple devices, with each device predicting positive and negative labels for each image-text pair. Later, the devices swap the text snippets to re-compute the loss with corresponding images.
Performance Results of SigLip
Based on the accuracy metric, the sigmoid loss outperforms the softmax loss for smaller batch sizes on the ImageNet dataset.
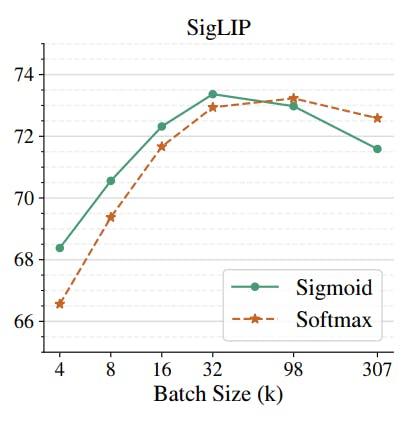
Both losses deteriorate after a specific batch size, with Softmax performing slightly better at substantial batch sizes.
SigLip: Use Case
SigLip is suitable for training tasks involving extensive datasets. Users can fine-tune SigLip using smaller batch sizes for faster training.
4. StreetCLIP
StreetCLIP is an image geolocalization algorithm that fine-tunes CLIP on geolocation data to predict the locations of particular images. The model is available on Hugging Face for further research.
StreetCLIP: Architecture and Development
The model improves CLIP zero-shot learning capabilities by training a generalized zero-shot learning (GZSL) classifier that classifies seen and unseen images simultaneously during the training process.
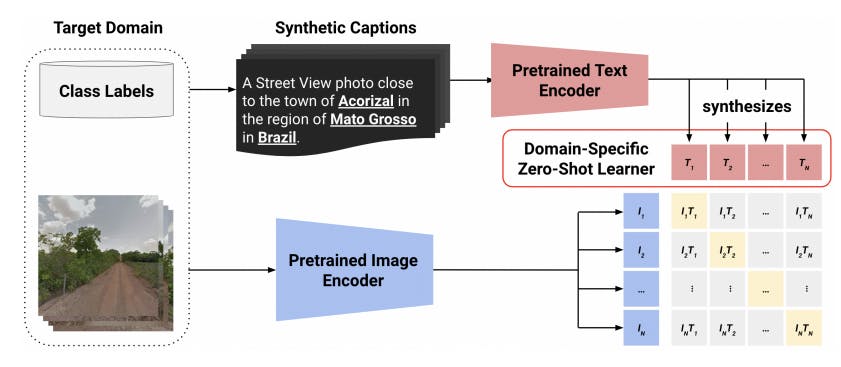
Fine-tuning involves generating synthetic captions for each image, specifying the city, country, and region. The training objective is to correctly predict these three labels for seen and unseen photos by optimizing a GZSL and a vision representation loss.
Performance Results of StreetCLIP
Compared to CLIP, StreetCLIP has better geolocation prediction accuracy. It outperforms CLIP by 0.3 to 2.4 percentage points on the IM2GPS and IM2GPS3K benchmarks.
StreetCLIP: Use Case
StreetCLIP is suitable for navigational purposes where users require information on weather, seasons, climate patterns, etc.
It will also help intelligence agencies and journalists extract geographical information from crime scenes.
5. FashionCLIP
FashionCLIP (F-CLIP) fine-tunes the CLIP model using fashion datasets consisting of apparel images and textual descriptions. The model is available on GitHub and HuggingFace.
FashionCLIP: Architecture and Development
The researchers trained the model on 700k image-text pairs in the Farfetch inventory dataset and evaluated it on image retrieval and classification tasks.
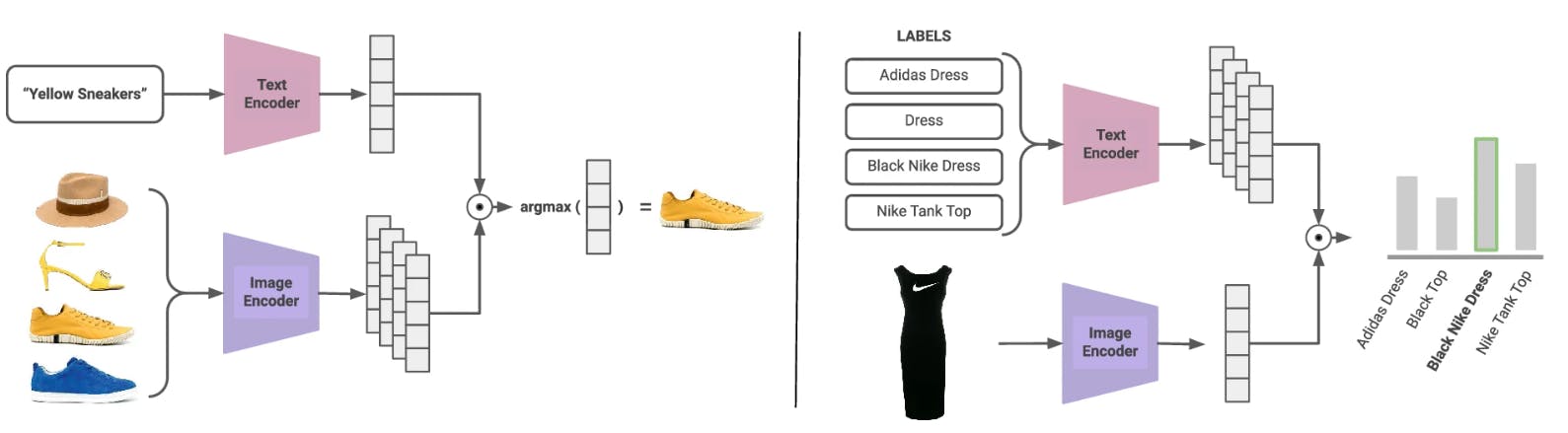
The evaluation also involved testing for grounding capability. For instance, zero-shot segmentation assessed whether the model understood fashion concepts such as sleeve length, brands, textures, and colors.
They also evaluated compositional understanding by creating improbable objects to see if F-CLIP generated appropriate captions. For instance, they see if F-CLIP can generate a caption—a Nike dress—when seeing a picture of a long dress with the Nike symbol.
Performance Results of FashionCLIP
F-CLIP outperforms CLIP on multiple benchmark datasets for multi-modal retrieval and product classification tasks. For instance, F-CLIP's F1 score for product classification is 0.71 on the F-MNIST dataset, while it is 0.66 for CLIP.
FashionCLIP: Use Case
Retailers can use F-CLIP to build chatbots for their e-commerce sites to help customers find relevant products based on specific text prompts.
The model can also help users build image-generation applications for visualizing new product designs based on textual descriptions.
6. CLIP-RSICD
CLIP-RSICD is a fine-tuned version of CLIP trained on the Remote Sensing Image Caption Dataset (RSICD). It is based on Flax, a neural network library for JAX (a Python package for high-end computing). Users can implement the model on a CPU. The model is available on GitHub.
CLIP-RSICD: Architecture and Development
The RSICD consists of 10,000 images from Google Earth, Baidu Map, MapABC, and Tianditu. Each image has multiple resolutions with five captions.

Due to the small dataset, the developers implemented augmentation techniques using transforms in Pytorch’s Torchvision package. Transformations included random cropping, random resizing and cropping, color jitter, and random horizontal and vertical flipping.
Performance Results of CLIP-RSICD
On the RSICD test set, the regular CLIP model had an accuracy of 0.572, while CLIP-RSICD had a 0.883 accuracy score.
CLIP-RSICD: Use Case
CLIP-RSICD is best for extracting information from satellite images and drone footage. It can also help identify red flags in specific regions to predict natural disasters due to climate change.
7. BioCLIP
BioCLIP is a foundation model for the tree of life trained on an extensive biology image dataset to classify biological organisms according to their taxonomy.
BioCLIP: Architecture and Development
BioCLIP fine-tunes the CLIP framework on a custom-curated dataset—TreeOfLife-10M—comprising 10 million images with 454 thousand taxa in the tree of life. Each taxon corresponds to a single image and describes its kingdom, phylum, class, order, family, genus, and species.

The CLIP model takes the taxonomy as a flattened string and matches the description with the correct image by optimizing the contrastive loss function.
Researchers also enhance the training process by providing scientific and common names for a particular species to improve generalization performance. This method helps the model recognize a species through a general name used in a common language.
Performance Results of BioCLIP
On average, BioCLIP boosts accuracy by 18% on zero-shot classification tasks compared to CLIP on ten different biological datasets.
BioCLIP: Use Case
BioCLIP is ideal for biological research involving VQA tasks where experts quickly want information about specific species.
8. CLIPBert
CLIPBert is a video and language model that uses the sparse sampling strategy to classify video clips belonging to diverse domains quickly. It uses Bi-directional Encoder Representations from Transformers (BERT) - a large language model (LLM), as its text encoder and ResNet-50 as the visual encoder.
CLIPBert: Architecture and Development
The model’s sparse sampling method uses only a few sampled clips from a video in each training step to extract visual features through a convolutional neural network (CNN). The strategy improves training speed compared to methods that use full video streams to extract dense features.
The model initializes the BERT with weights pre-trained on BookCorpus and English Wikipedia to get word embeddings from textual descriptions of corresponding video clips.
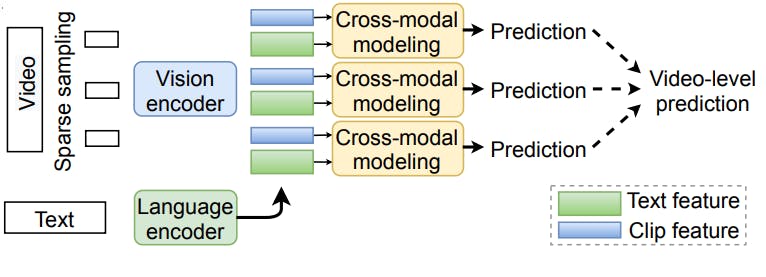
Training involves correctly predicting a video’s description by combining each clip’s predictions and comparing them with the ground truth. The researchers used 8 NVIDIA V100 GPUs to train the model on 40 epochs for four days.
During inference, the model samples multiple clips and aggregates the prediction for each clip to give a final video-level prediction.
Performance Results of CLIPBert
CLIPBert outperforms multiple SoTA models on video retrieval and question-answering tasks. For instance, CLIPBert shows a 4% improvement over HERO on video retrieval tasks.
CLIPBert: Use Case
CLIPBert can help users analyze complex videos and allow them to develop generative AI tools for video content creation.
.Alternatives to Open AI CLIP: Key Takeaways
With frameworks like CLIP and ChatGPT, combining computer vision with NLP is becoming the new norm for developing advanced multi-modal models to solve modern industrial problems.
Below are a few critical points to remember regarding CLIP and its alternatives.
- OpenAI CLIP Benefits: OpenAI CLIP is an excellent choice for general vision-language tasks requiring low domain-specific expertise.
- Limitations: While CLIP’s zero-shot capability helps users adapt the model to new tasks, it underperforms on fine-grained tasks and out-of-distribution data.
- Alternatives: Multiple CLIP-based options are suitable for medical image analysis, biological research, geo-localization, fashion, and video understanding.
Frequently asked questions
Yes. Open AI CLIP is open-source and available on GitHub.
Zero-shot learning (ZSL) is a method where users train a model to classify unseen data classes without any training samples for those classes.
A transformer is a neural network architecture that uses self-attention mechanisms to understand context and data attributes.
Image retrieval, visual question-answering, and image captioning are a few popular use cases of CLIP.
Contrastive loss is an optimization function that maximizes the distance between dissimilar data points and minimizes the distance between similar samples.
Encord provides a comprehensive annotation suite that streamlines the process of training AI models. Unlike other platforms, it focuses on user-friendly tools that enhance collaboration and efficiency, allowing teams to annotate data seamlessly and manage workflows more effectively.
Encord offers a range of data annotation services tailored for AI projects, including video and audio data annotation. Our services encompass basic classification tasks, object detection, and more complex labeling needs, ensuring that we can accommodate various project requirements.
Encord is designed to integrate seamlessly with various AI and cloud tools, allowing teams to enhance their existing workflows without disruption. This flexibility ensures that organizations can leverage Encord's capabilities while maintaining their preferred tools and processes.
Yes, Encord is designed to integrate seamlessly with other tools and systems in your AI compliance ecosystem. This flexibility allows organizations to build a tailored solution that meets their specific compliance needs while ensuring a robust evaluation process for AI models.
Encord offers robust automation capabilities for annotation pipelines, significantly reducing the manual effort required. Users can automate a large portion of their annotation processes while still retaining the option to handle more complex tasks manually or semi-manually.
Encord addresses the challenge of disparate tools in the AI pipeline by offering seamless integrations that enhance collaboration and data management. This capability minimizes the time spent moving data between systems and helps streamline the overall workflow for AI teams.
Encord provides a comprehensive platform for the management, curation, and annotation of AI data. This includes various features tailored for multimodal AI companies, enabling efficient workflows for data preparation that are essential for training robust AI models.
Encord provides robust features for segmenting motion data into action-specific sequences, allowing users to label actions like walking, jumping, and running. This can be accomplished through dynamic classifications, enabling efficient and accurate annotations.
Encord's platform supports end-to-end development by providing tools for data annotation, model training, and inference. This holistic approach ensures that teams can efficiently manage their AI projects from initial data collection through to deployment.
Encord supports a variety of annotation types, including standard labeling and complex tasks like segmentation, which involves masking images. This versatility is crucial for training AI models across different domains, including computer vision.