The Complete Guide to Data Annotation [2024 Review]

Co-Founder & CEO at Encord
Data annotation is integral to the process of training a machine learning (ML) or computer vision model (CV). Datasets often include many thousands of images, videos, or both, and before an algorithmic-based model can be trained, these images or videos need to be labeled and annotated accurately.
Creating training datasets is a widely used process across dozens of sectors, from healthcare to manufacturing, to smart cities and national defense projects.
In the medical sector, annotation teams are labeling and annotating medical images (usually delivered as X-rays, DICOM, or NIfTI files) to accurately identify diseases and other medical issues. With satellite images (usually delivered in the Synthetic Aperture Radar format), annotators could be spending time identifying coastal erosion and other signs of human damage to the planet.
In every use case, data labeling and annotation are designed to ensure images and videos are labeled according to the project outcome, goals, objectives, and what the training model needs to learn before it can be put into production.
In this article, we cover the complete guide to data annotation, including the different types of data annotation, use cases, and how to annotate images and videos.
What is Data Annotation?
Data annotation is the process of taking raw images and videos within datasets and applying labels and annotations to describe the content of the datasets. Machine learning algorithms can’t see. It doesn’t matter how smart they are.
We, human annotators and annotation teams, need to show AI models (artificial intelligence) what’s in the images and videos within a dataset.
Annotations and labels are the methods that are used to show, explain, and describe the content of image and video-based datasets. This is the way models are trained for an AI project; how they learn to extrapolate and interpret the content of images and videos across an entire dataset.
With enough iterations of the training process (where more data is fed into the model until it starts generating the sort of results, at the level of accuracy required), accuracy increases, and a model gets closer to achieving the project outcomes when it goes into the production phase.
At the start, the first group of annotated images and videos might produce an accuracy score of around 70%. Naturally, the aim is to increase and improve that, and therefore more training data is required to further train the model. Another key consideration is data-quality - the data has to be labeled as clearly and accurately as possible to get the best results out of the model.
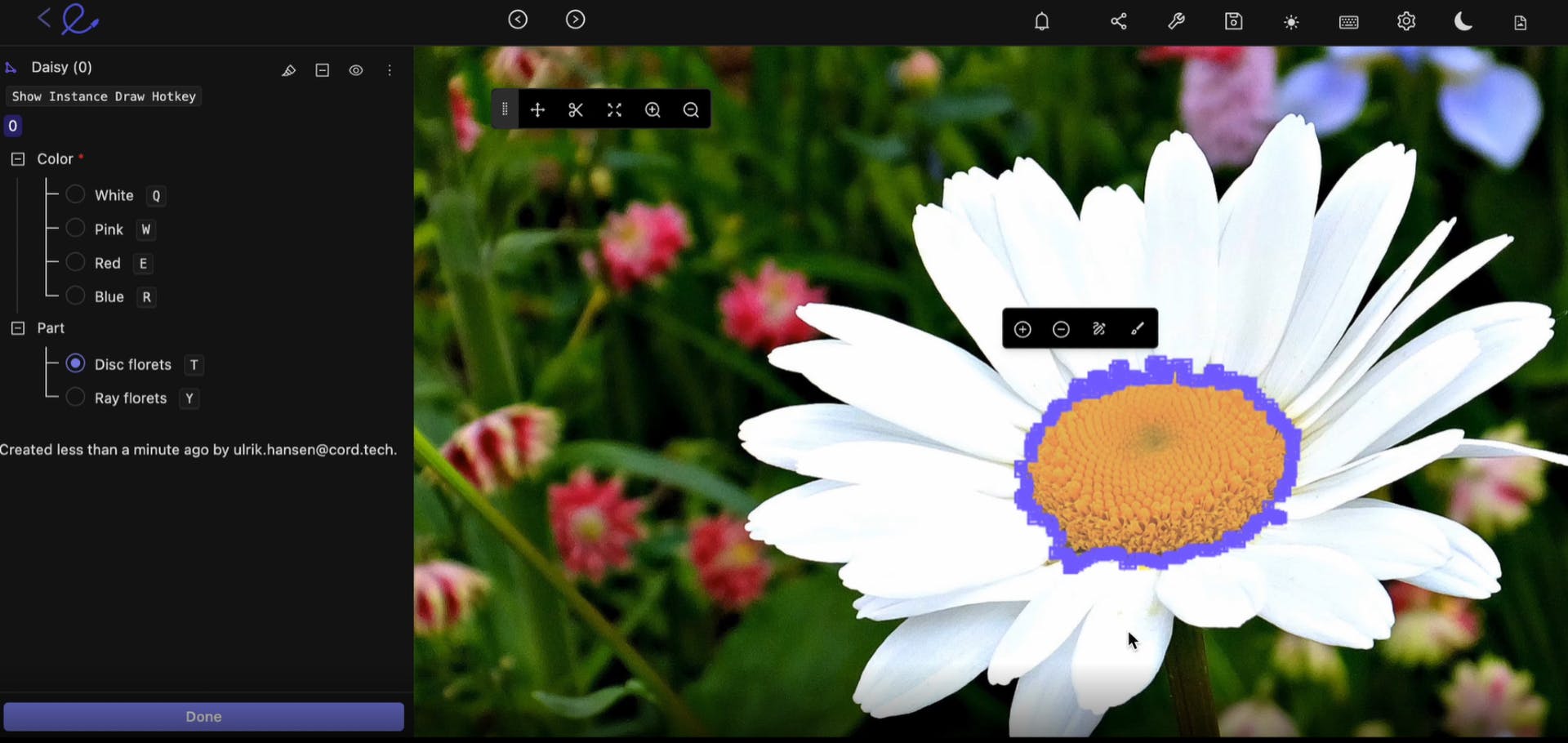
Image segementation in Encord
What’s AI-assisted Annotation?
Manual annotation is time-consuming. Especially when tens of thousands of images and videos need to be annotated and labeled within a dataset. As we’ve mentioned in this article, annotation in computer vision models always involves human teams.
Fortunately, there are now tools with AI-labeling functionality to assist with the annotation process. Software and algorithms can dramatically accelerate annotation tasks, supporting the work of human annotation teams. You can use open-source tools, or premium customizable AI-based annotation tools that run on proprietary software, depending on your needs, budget, goals, and nature of the project.
Human annotators are often still needed to draw bounding boxes or polygons and label objects within images. However, once that input and expertise is provided in the early stages of a project, annotation tools can take over the heavy lifting and apply those same labels and annotations throughout the dataset.
Expert reviewers and quality assurance workflows are then required to check the work of these annotators to ensure they’re performing as expected and producing the results needed. Once enough of a dataset has been annotated and labeled, these images or videos can be fed into the CV or ML model to start training it on the data provided.
What Are The Different Types of Data Annotation?
There are numerous different ways to approach data annotation for images and videos.
Before going into more detail on the different types of image and video annotation projects, we also need to consider image classification and the difference between that and annotation. Although classification and annotation are both used to organize and label images to create high-quality image data, the processes and applications involved are somewhat different.
Classification is the act of automatically classifying objects in images or videos based on the groupings of pixels. Classification can either be “supervised” — with the support of human annotators, or “unsupervised” — done almost entirely with image labeling tools.
Alongside classification, there is a range of approaches that can be used to annotate images and videos:
- Multi-Object Tracking (MOT) in video annotation for computer vision models, is a way to track multiple objects from frame to frame in videos once an object has been labeled. For example, it could be a series of cars moving from one frame to the next in a video dataset. Using MOT, an automated annotation feature, it’s easier to keep track of objects, even if they change speed, direction, or light levels change.
- Interpolation in automated video annotation is a way of filling in the gaps between keyframes in a video. Once labels and annotations have been applied at the start and end of a series of videos, interpolation is an automation tool that applies those labels throughout the rest of the video(s) to accelerate the process.
- Auto Object Segmentation and detection is another type of automated data annotation tool. You can use this for recognizing and localizing objects in images or videos with vector labels. Types of segmentation include instance segmentation and semantic segmentation.
- Model-assisted labeling (MAL) or AI-assisted labeling (AAL) is another way of saying that automated tools are used in the labeling process. It’s far more complex than applying ML to spreadsheets or other data sources, as the content itself is either moving, multi-layered (in the case of various medical imaging datasets) or involves numerous complex objects, increasing the volume of labels and annotations required.
- Human Pose Estimation (HPE) and tracking is another automation tool that improves human pose and movement tracking in videos for computer vision models.
- Bounding Boxes: A way to draw a box around an object in an image or video, and then label that object so that automation tools can track it and similar objects throughout a dataset.
- Polygons and Polylines: These are ways of drawing lines and labeling either static or moving objects within videos and images, such as a road or railway line.
- Keypoints and Primitives (aka skeleton templates): Keypoints are useful for pinpointing and identifying features of countless shapes and objects, such as the human face. Whereas, primitives, also known as skeleton templates are for specialized annotations to templatize specific shapes, e.g. 3D cuboids, or the human body.
Of course, there are numerous other types of data annotations and labels that can be applied. However, these are amongst some of the most popular and widely used CV and ML models.

How Do I Annotate an Image Dataset For Machine Learning?
Annotation work is time-consuming, labor intensive, and often doesn’t require a huge amount of expertise. In most cases, manual image annotation tasks are implemented in developing countries and regions, with oversight from in-house expert teams in developed economies. Data operations and ML teams ensure annotation workflows are producing high-quality outputs.
To ensure annotation tasks are complete on time and to the quality and accuracy standards required, automation tools often play a useful role in the process. Automation software ensures a much larger volume of images can be labeled and annotated, while also helping managers oversee the work of image annotation teams.
Different Use Cases for Annotated Images
Annotated images and image-based datasets are widely used in dozens of sectors, in computer vision and machine learning models, for everything from cancer detection to coastal erosion, to finding faults in manufacturing production lines.
Annotated images are the raw material of any CV, ML, or AI-based model. How and why they’re used and the outcomes these images generate depends on the model being used, and the project goals and objectives.
How Do I Annotate a Video Dataset For Machine Learning?
Video annotation is somewhat more complicated. Images are static, even when there’s a layer of images and data, as is often the case with medical imaging files.
However, videos are made up of thousands of frames, and within those moving frames are thousands of objects, most of which are moving. Light levels, backgrounds, and numerous other factors change within videos.
Within that context, human annotators and automated tools are deployed to annotate and label objects within videos to train a machine learning model on the outputs of that annotation work.
Different Use Cases for Annotated Videos
Similar to annotated images, videos are the raw materials that train algorithmic models (AI, CV, ML, etc.) to interpret, understand, and analyze the content and context of video-based datasets.
Annotated videos are used in dozens of sectors with thousands of practical commercial use cases, such as disease detection, smart cities, manufacturing, retail, and numerous others.
At Encord, our active learning platform for computer vision is used by a wide range of sectors - including healthcare, manufacturing, utilities, and smart cities - to annotate 1000s of images and accelerate their computer vision model development.
Experience Encord in action. Dramatically reduce manual video annotation tasks, generating massive savings and efficiencies.
Sign-up for an Encord Free Trial: The Active Learning Platform for Computer Vision, used by the world’s leading computer vision teams.
AI-assisted labeling, model training & diagnostics, find & fix dataset errors and biases, all in one collaborative active learning platform, to get to production AI faster. Try Encord for Free Today.
Want to stay updated?
Follow us on Twitter and LinkedIn for more content on computer vision, training data, and active learning.
Join our Discord channel to chat and connect.
FAQs: How to Annotate and Label Different Image and Video Datasets for Machine Learning
How are DICOM and NIfTI Images Annotated for Machine Learning?
DICOM and NIfTI images are two of the most widely used medical imaging formats. Both are annotated using human teams, supported by automated annotation tools and software. In the case of DICOM files, labels and annotations need to be applied across numerous layers of the images, to ensure the right level of accuracy is achieved.
How are Medical Images Used in Machine Learning?
In most cases, medical images are used in machine learning models to more accurately identify diseases, and viruses, and to further the medical professions' (and researchers') understanding of the human body and more complex edge cases.
How are SAR (Synthetic Aperture Radar) Images Annotated for Machine Learning?
SAR images (Synthetic Aperture Radar) come from satellites, such as the Copernicus Sentinel-1 mission of the European Space Agency (ESA) and the EU Copernicus Constellation. Private satellite providers also sell images, giving projects that need them a wide variety of sources of imaging datasets of the Earth from orbit.
SAR images are labeled and annotated in the same way as other images before these datasets are fed into ML-based models to train them.
What Are The Uses of SAR Images for Machine Learning?
SAR images are used in machine learning models to advance our understanding of the human impact of climate change, human damage to the environment, and other environmental fields of research. SAR images also play a role in the shipping, logistics, and military sectors.
Frequently asked questions
Encord facilitates various types of data annotation tailored to specific use cases, including object detection and classification. The platform allows for both physical annotation through offshore teams and internal tooling, ensuring that teams can efficiently manage the annotation process for diverse applications.
The annotation workflow in Encord consists of three key components: curated data (either from Encord's extracted metrics or user-provided data), an ontology that defines the classes to be labeled, and a workflow that incorporates quality assurance processes for the annotation pipeline.
With Encord, the annotation process is flexible and can be conducted through pre-labeling with models or manual annotation by humans. The platform provides full visibility and control over the annotation process, allowing for effective management of data quality.
Encord offers extensive support for teams new to annotation tools, including onboarding resources, customer support, and training materials. We aim to ensure that users can quickly become proficient in using our platform to maximize their productivity.
Encord features three main modules: Encord Index, Annotate, and Active. The Annotate module includes tools for workflows, label editing, project management, and analytics, all designed to enhance collaboration and efficiency in data annotation.
Ontologies in Encord are used to define labeling classes for different projects. They help categorize and organize the annotations based on the metadata provided, allowing for structured and efficient labeling during the annotation process.
Encord's annotation interface is designed for ease of use, enabling collaborative input and real-time feedback. Users can tailor the interface to their specific needs, ensuring that it aligns with their unique annotation workflows.
Encord provides flexibility in defining mandatory fields during annotation. You can set fields to be optional or required based on your project�’s needs, allowing for more tailored data collection according to specific criteria.
Encord supports various annotation types, including bounding boxes and segmentation maps. This flexibility allows users to cater to different project requirements while maintaining a streamlined annotation workflow.
Yes, Encord allows users to engage external annotators, providing flexibility in managing the annotation process. This can help streamline workflows and meet tight deadlines for data labeling.