What is Continuous Validation?

Imagine a self-driving car system that flawlessly navigates test tracks but falters on busy streets due to unanticipated real-world scenarios. This failure demonstrates the critical need for continuous validation in machine learning (ML).
Continuous validation, derived from DevOps, ensures the integrity, performance, and security of ML models throughout their lifecycle.
By incorporating continuous testing and monitoring within CI/CD pipelines, you can ensure models remain effective even as data shifts and real-world conditions change.
This article examines continuous validation in machine learning, its implementation strategies, and best practices. Exploring real-world applications, challenges, and future trends will equip you with the knowledge to optimize and innovate your ML projects.
Let’s get right into it! 🚀

Understanding Continuous Validation and Its Importance
Continuous validation in machine learning is an extensive process that ensures the accuracy, performance, and reliability of ML models, not only upon their initial deployment but also throughout their operational lifecycle.
This approach is critical for consistently maintaining model performance and accuracy over time. It is seamlessly integrated into both the deployment and post-deployment phases of model development as a core component of the CI/CD pipeline for ML.
Deployment Phase
During this phase, detailed testing is conducted as part of the continuous integration and delivery processes. This includes:
- Data Validation: Ensuring the quality and integrity of input data.
- Model Behavior Testing: Examining the model's performance under varied scenarios and datasets.
- Core Functionality Tests: Verifying that all model components and their interactions operate as designed.
These tests ensure that each model component functions correctly before fully deploying.
Post-Deployment Monitoring
After deployment, the focus shifts to:
- Continuous Monitoring: This involves tracking the model's performance in real-time to detect any issues promptly.
- Performance Validation: Regular assessments check for signs of data drift or performance degradation.
This ongoing monitoring and validation ensures the model adapts effectively to new data and changing conditions. This helps maintain model robustness and performance without needing constant manual adjustments.

Different stages of evaluation
Continuous validation helps ML operations be agile and reliable by proactively managing models. It ensures that models deliver consistent, high-quality outputs.
The Mechanisms of Continuous Validation in Machine Learning
There are three mechanisms of continuous validation that are essential components that facilitate the continuous integration, delivery, and validation of ML models and workflows:
- Automated pipelines.
- Feedback loops.
- Continuous verification and testing post-deployment.
Automated Pipelines
Automated pipelines in MLOps streamline various stages of the ML lifecycle, including data collection, model training, evaluation, and deployment. This mechanism may include data preprocessing, feature selection, model training, and evaluation, all triggered by new data or model code changes.
This automation reduces manual errors and accelerates the process from development to deployment, ensuring that models are consistently evaluated and updated in response to new data or feedback.
Feedback Loops
Feedback loops allow ML applications to dynamically adjust models based on real-world performance and data changes, maintaining accuracy and effectiveness. These feedback loops can be implemented at various stages of the ML lifecycle, such as during model training (e.g., using techniques like cross-validation) or post-deployment (e.g., by monitoring model performance and updating the model based on new data).
Continuous Verification and Testing Post-Deployment
Post-deployment, continuous verification is key to maintaining the integrity and accuracy of ML models during their operational phase. This involves:
- Continuous Monitoring: Tracking performance through key indicators such as accuracy, precision, recall, and F1-score to detect poor model performance. Using real-time dashboards to visualize model health allows for the early detection of issues such as drift or shifts in data patterns.
- Anomaly Detection: Using advanced algorithms to identify and address concept drift or unusual data points, thus ensuring the model remains relevant and accurate over time.
However, implementing continuous validation mechanisms also presents challenges. The computational resources required for continuous monitoring and testing can be substantial, particularly for large-scale ML applications. False positives in anomaly detection can also lead to unnecessary alerts and investigations, requiring careful tuning of detection thresholds and parameters.
Despite these challenges, the benefits of continuous validation in ML are clear. By implementing these mechanisms, organizations can ensure that their ML models remain robust, accurate, and effective throughout their lifecycle, adapting to new challenges and data as needed.
This continuous validation process is crucial for leveraging the full potential of ML in dynamic and evolving operational environments.

Implementing Continuous Validation: Automating the Process
Here's a breakdown of key steps to integrate ML-specific continuous integration and delivery (CI/CD) with testing and monitoring for ongoing model accuracy:
- Version Control: Set up Git (or similar) to manage code, data, and model files for tracking and versioning.
- Infrastructure as Code (IaC): Use Terraform, CloudFormation, etc., to define computing resources for consistent environments across development, testing, and production.
- Selecting CI/CD Tools: Choose a platform supporting ML pipeline automation (e.g., Jenkins, GitLab CI/CD, Azure DevOps).
- Automated Testing: Implement unit tests, data validation, and model performance tests to run before deployment.
- Continuous Integration and Deployment: Configure your CI/CD pipeline to automatically build, test, and deploy ML models. This setup should include stages for:
- Environment build and dependencies setup.
- Model training and evaluation.
- Packaging models as deployable artifacts.
- Deployment to production/staging.
- Monitoring and Feedback: Use Encord Active, Arize AI, and WhyLabs (or similar) to monitor model performance and alert on data drift or degradation.
- Recommended Read: ML Observability Tools: Arize AI Alternatives.
- Continuous Retraining: Set up strategies to automate model retraining with new data for adaptation to change.
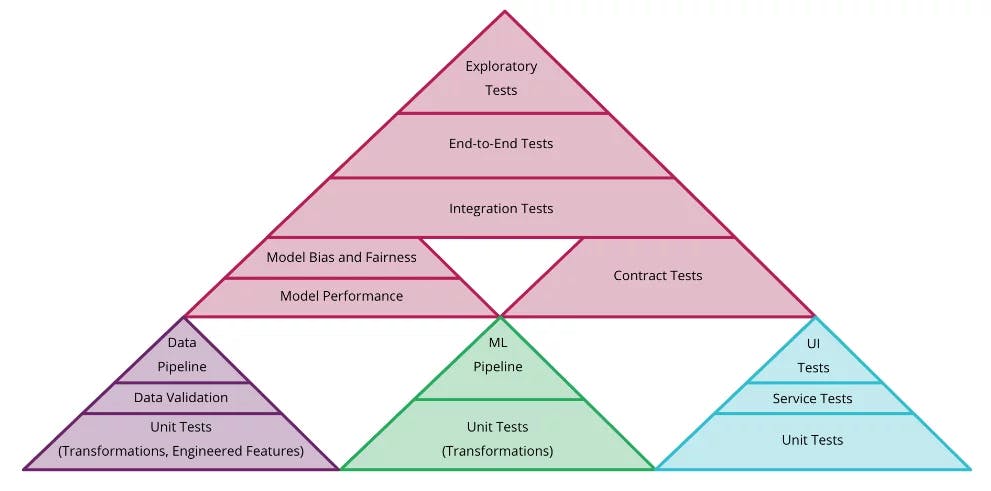
Continuous Tests in Machine Learning
With these steps and tools, you can ensure efficient ML model deployment and ongoing effectiveness in production. This approach supports reliable ML applications and quicker responses to new challenges.
Machine Learning (ML) Model Validation
Deployment Performance
Validating an ML model after deployment involves assessing its performance in a real-world operational environment. This ensures smooth integration without disruptions or excessive latency (i.e., delays in response time). Verifying the deployed model's accuracy and efficiency with real-time data is crucial.
Metrics and Monitoring
Continuous monitoring of key performance indicators (KPIs) is essential. Track accuracy, precision, recall, and F1-score to assess model performance. Additionally, monitor system-specific metrics like inference latency, memory usage, and throughput for operational efficiency.
Drift Detection and Mitigation
Model drift occurs when performance degrades over time due to changes in the underlying data. Detecting drift (e.g., using the Page-Hinkley test) is vital for reliable ML models. Recalibration or retraining may be necessary to restore accuracy when drift is detected. This highlights the connection between drift detection and the feedback loops discussed earlier.

Data Drift in Machine Learning
Key Metrics and System Recalibration
To manage model drift and system performance effectively, periodic recalibration of the model is necessary. This process involves:
- Adjusting the Model: Based on new data and recalculating performance metrics.
- Retraining: Potentially retraining the model entirely with updated datasets.
Continuous validation processes must include robust mechanisms for tracking data quality, model accuracy, and the impact of external factors on model behavior.
By closely monitoring these aspects and adjusting strategies as needed, organizations can ensure their ML models remain effective and accurate, providing reliable outputs despite the dynamic nature of real-world data and conditions.
Continuous Validation: Advantages
Improved Model Performance
Continuous validation significantly improves model performance by frequently testing models against new and diverse datasets. This allows for early identification of degradation, ensuring models are always tuned for optimal outcomes.
Minimizes Downtime by Early Detection
A significant benefit of continuous validation is its ability to reduce system downtime. Timely interventions can be made by identifying potential issues early, such as model drift, data anomalies, or integration challenges. This proactive detection prevents minor issues from escalating into major disruptions, ensuring smooth operational continuity.
Enhanced Model Reliability
Regular checks and balances ensure models operate as expected under various conditions, increasing the consistency of model outputs. This is crucial in applications demanding high reliability (e.g., healthcare decision support).
Proactive Model Performance Validation
Continuous validation goes beyond reactions to current conditions. By regularly updating models based on predictions and potential data shifts, they remain robust and adaptable to new challenges.
These advantages—improved performance, reduced downtime, enhanced reliability, and proactive validation—collectively ensure that machine learning models remain accurate, dependable, and efficient over time.
Continuous validation is therefore an indispensable practice for sustaining the effectiveness of ML models in dynamic environments.
Tools and Technologies for Continuous Validation
Overview of Tools
A range of tools from the MLOps domain supports the implementation of continuous validation in machine learning:
- MLOps Platforms: Databricks, etc., provide frameworks for managing the entire ML lifecycle, including model training, deployment, monitoring, and retraining.
- ML Monitoring Solutions: Encord Active tracks model performance metrics and detects anomalies or drift. This article provides a comprehensive overview of best practices for improving model drift.
- Data Validation Tools: Great Expectations, etc., help ensure data quality and consistency before it reaches the model.
- Testing Frameworks: pytest, etc., are used to create automated tests for different stages of the ML pipeline.
- Experiment Tracking Tools: neptune.ai, Weights & Biases, etc., help organize, compare, and reproduce ML experiments with different model versions, data, and parameters.
These tools collectively enhance organizations' ability to implement continuous validation practices effectively, ensuring that ML models are deployed in production.
Continuous Validation in Action: Real-World Applications and Case Studies
Continuous validation ensures that machine learning models maintain accuracy and efficiency across various industries. Below are examples and case studies illustrating the impact of continuous validation:
Customer Service (Active Learning)
ML models predict customer inquiry categories. By continuously retraining on new data, they improve predictions, efficiency, and the customer experience.
Medical Imaging (Active Learning)
In medical imaging, active learning prioritizes the most uncertain or informative images for expert labeling. This targeted approach reduces the need to label vast datasets while ensuring the ML model learns from the most valuable data, which is crucial for accurate diagnoses.
Financial Services (Continuous Monitoring)
Continuous validation adjusts algorithmic trading models based on new market data, preventing losses and improving predictive accuracy.
Automotive Industry (Active Learning & Monitoring)
In autonomous vehicles, continuous validation ensures navigation and obstacle detection systems are always updated. Active learning allows adaptation to new driving conditions, while monitoring tracks system health.
These case studies demonstrate how continuous validation, particularly through active learning pipelines, is crucial for adapting and improving ML models based on new data and feedback loops.
Continuous Validation: Common Challenges
Implementing continuous validation in machine learning projects often involves navigating these hurdles:
- Complex Dependencies: Managing dependencies on data formats, libraries, and hardware can be challenging. For example, a library update might break compatibility with a model's trained environment.
- Timely Feedback Loops: Establishing efficient feedback loops to gather insights from model performance and iteratively improve models can be time-consuming. E.g., In customer service chatbots, model performance must be monitored and validated against user feedback and satisfaction scores.
- Integration with Existing Systems: Integrating continuous validation into development pipelines without disrupting operations can require significant changes to infrastructure and workflows. For instance, adding a new validation tool or framework to a CI/CD pipeline may require changes to build, deployment, monitoring, and alerting scripts.
- Scalability: It is crucial to ensure that validation processes scale effectively as models and data grow. As data volume and velocity increase, the validation pipeline must process and analyze it quickly. Scalability issues can lead to bottlenecks, delays, and increased costs.
Best Practices for Continuous Validation
To effectively implement continuous validation in machine learning projects, consider the following best practices:
Automation & Testing
- Automate Where Possible: Leverage tools for automating data validation, model testing, and deployment to reduce manual errors and speed up the process.
- Implement Robust Testing Frameworks: Use unit, integration, and regression tests to ensure the robustness and reliability of all pipeline components.
Monitoring & Data
- Monitor Model Performance Continuously: Track model accuracy, performance metrics, and signs of drift or degradation with robust monitoring systems.
- Ensure Data Quality: Implement processes for continuous data quality checks to maintain model integrity.
Governance & Control
- Use Version Control: Version control allows you to manage data sets, model parameters, and algorithms with tracking and rollback capabilities.
- Focus on Model Governance: Establish policies for model development, deployment, access controls, versioning, and regulatory compliance. This is crucial for ensuring the responsible and ethical use of ML models.
These challenges and best practices can help teams improve continuous validation and create more reliable and performant machine learning models.
Continuous Validation: Conclusion
Continuous validation is critical for ensuring the accuracy, reliability, and performance of AI models. Organizations can protect application integrity, foster innovation, and stay competitive by proactively integrating continuous validation practices into ML workflows.
To successfully implement continuous validation, organizations must address challenges such as managing complex dependencies, establishing timely feedback loops, and ensuring scalability.
Automation, robust testing, version control, data quality assurance, and model governance can help organizations overcome these challenges and maximize continuous validation benefits.
New tools, frameworks, and industry standards will make continuous validation part of the ML development lifecycle as the AI industry matures.
Organizations that embrace this approach will be well-positioned to harness the power of machine learning and stay ahead of the curve in an ever-evolving technological landscape.

Frequently asked questions
Continuous validation involves ongoing testing and adjustment of ML models throughout their lifecycle, unlike traditional validation, which often occurs at set points, such as pre-deployment.
It continuously monitors and adjusts models in response to new data and changing conditions, ensuring sustained performance and reliability.
Tools like MLflow, Kubeflow, and platforms such as Encord support continuous validation by integrating with existing ML workflows.
Continuous validation is integrated as part of the CI/CD pipeline through automated testing and monitoring stages that continuously evaluate the performance and integrity of ML models.
Metrics like accuracy, precision, recall, model drift, and runtime performance are crucial for assessing continuous validation success.
Key tools include continuous integration services like Jenkins or CircleCI, model monitoring tools like Prometheus, and ML-specific testing frameworks like TensorFlow Extended (TFX)
Challenges include managing complex dependencies and ensuring timely feedback loops; these can be addressed by using automated tools and fostering close collaboration between data scientists and DevOps teams.
Continuous validation efforts commonly detect anomalies such as unexpected data drift, sudden drops in model performance, or operational glitches like data pipeline failures.
Validating annotation accuracy in Encord involves testing the platform's tracking capabilities on various data types, such as tissue structures. During project discussions, users can explore real-time validation to ensure that the annotations meet the expected quality standards.
Encord enables continuous learning by allowing users to integrate problematic images back into the labeling pipeline. This helps improve model performance over time by ensuring that the model learns from its mistakes and adapts to new data.
Encord addresses the challenges of data validation by providing tools that help teams validate and establish ground truths. This is crucial as models can produce unreliable outputs, making human oversight essential in many scenarios.