Data Curation in Computer Vision

In recent years, the explosion in data volume, which soared to around 97 zettabytes globally in 2022 and is projected to reach over 181 zettabytes by 2025, has been a boon for the fields of artificial intelligence (AI) and machine learning (ML). These fields thrive on large datasets to generate more accurate results. Extracting value from such vast amounts of data, however, is often challenging.
High-quality data is necessary to produce good results, particularly for AI systems powered by sophisticated computer vision (CV) algorithms and foundation models. Since CV models typically process unstructured data consisting of thousands of images, managing datasets effectively becomes crucial.
One aspect of data management that’s essential is data curation. When you incorporate data curation as part of your workflow, you can check for data quality issues, missing values, data distribution drift, and inconsistencies across your datasets that could impact the performance of downstream computer vision and machine learning models.

Data curation also helps you efficiently select edge cases, scenarios that are unlikely but could have significant implications if overlooked. For instance, a model for self-driving cars trained on images of roads and alleys under normal weather conditions may fail to recognize critical objects under extreme weather. Therefore, curating a dataset to include images across a spectrum of weather conditions is essential to account for such edge cases.
In this article, you will learn about data curation in detail, explore its challenges, and understand how it helps improve CV model performance. We’ll also specifically discuss the role of data annotation in curating computer vision datasets and how you can use the Encord platform for data curation.
Ready? Let’s dive right in! 🏊
What is Data Curation?
When you “curate data,” it simply means collecting, cleaning, selecting, and organizing data for your ML models so downstream consumers can get complete, accurate, relevant, and unbiased data for training and validating models. It’s an iterative process that you must follow even after model deployment to ensure the incoming data matches the data in the production environment.
Data curation differs from data management—management is a much broader concept involving the development of policies and standards to maintain data integrity throughout the data lifecycle.

What are the steps involved in data curation? Let’s explore them below!
Data Collection
The data curation phase starts with collecting data from disparate sources, public or proprietary databases, data warehouses, or web scraping.

Data Validation
After collection, you can validate your data using automated pipelines to check for accuracy, completeness, relevance, and consistency.
Data Cleaning
Then, clean the data to remove corrupted data points, outliers, incorrect formats, duplicates, and other redundancies to maintain data quality.
Normalization
Next is normalization, which involves re-scaling data values to a standard range and distribution that aid algorithms that are sensitive to input scales, thus preventing skews in learned weights and coefficients.
De-identification
It is a standard method of removing personally identifiable information from datasets, such as names, social security numbers (SSNs), and contact information.
Data Transformation
You can build automated pipelines to transform data into meaningful features for better model training. Feature engineering is a crucial element in this process. It allows data teams to find relevant relationships between different columns and turn them into features that help explain the target variable.
Data Augmentation
Data augmentation introduces slight dataset variations to expand data volume and scenario coverage. You can use image operations like crop, flip, zoom, rotate, pan, and scale to enhance computer vision datasets.

Note that augmented data differs from synthetic data. Synthetic data is computer-generated fake data that resembles real-world data. Typically, it is generated using state-of-the-art generative algorithms. On the other hand, augmented data refers to variations in training data, regardless of how it is generated.
Data Sampling
Data sampling refers to using a subset of data to train AI models. However, this may introduce bias during model training since we select only a specific part of the dataset. Such issues can be avoided through probabilistic sampling techniques like random, stratified, weighted, and importance sampling.
Data Partitioning
The final step in data curation is data partitioning. This involves dividing data into training, validation, and test sets. The model uses the training datasets to learn patterns and compute coefficients or weights. During training, the model’s performance is tested on a validation set. If the model performs poorly during validation, it can be adjusted by fine-tuning its hyper-parameters. Once you have satisfactory performance on the validation set, the test set is used to assess critical performance metrics, such as accuracy, precision, F1 score, etc., to see if the model is ready for deployment.
While there’s no one fixed way of splitting data into train, test, and validation sets, you can use the sampling methods described in the previous section to ensure that each dataset represents the population in a balanced manner. Doing so ensures your model doesn’t suffer from underfitting or overfitting.
Data Curation in Computer Vision
While the above data curation steps generally apply to machine learning, the curation process involves more complexity when preparing data for computer vision tasks.
First, let’s list the common types of computer vision tasks and then discuss annotation, a critical data curation step.
Common Types of Computer Vision Tasks
Object Detection
Object Detection is when you want to identify specific objects within your images. Below is an example of a butterfly detected with bounding boxes around the object, including a classification of the species of the butterfly “Ringlet.”
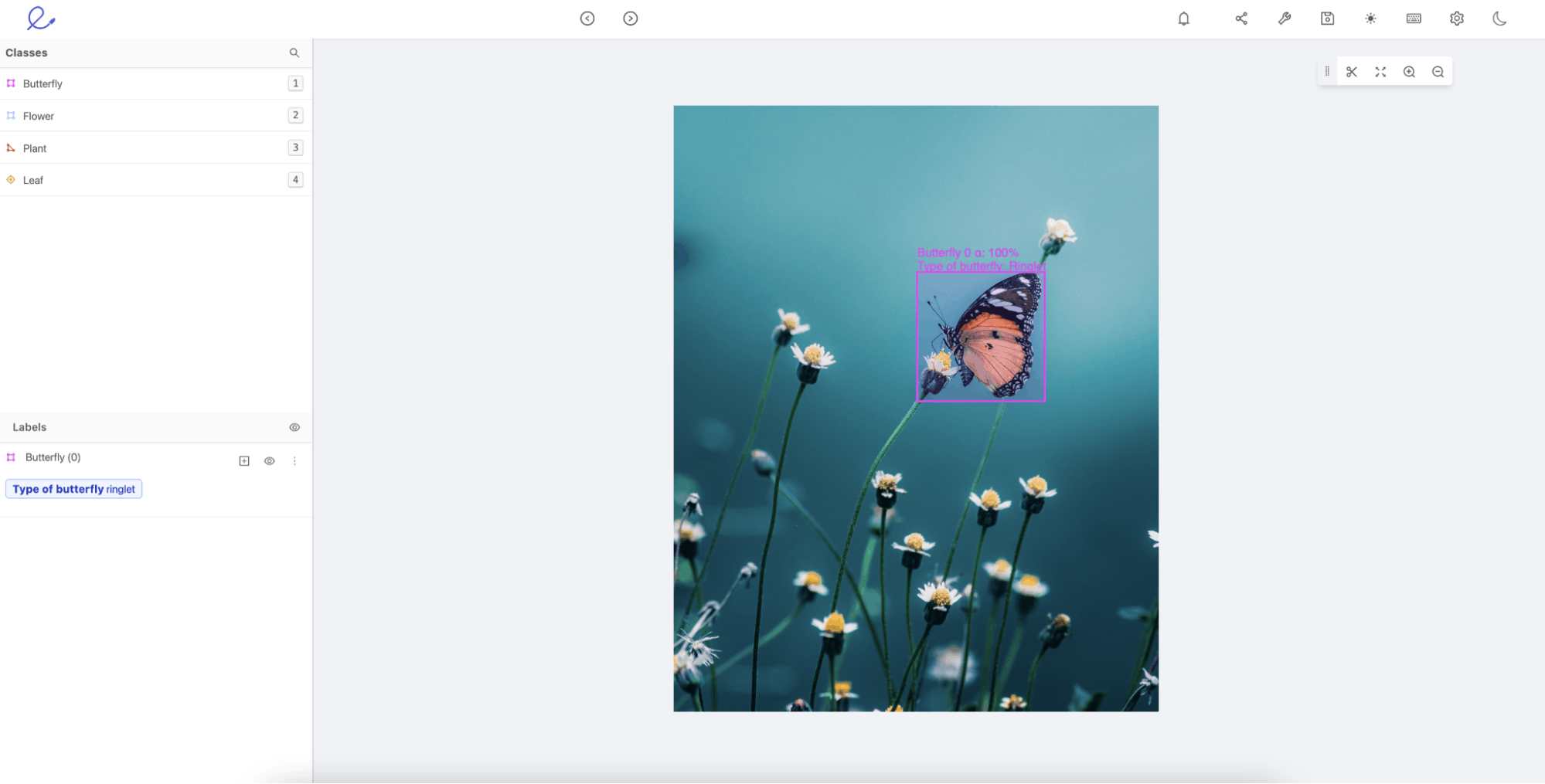
Object detection example in Encord Annotate.
Image Classification
Image classification models predict whether an object exists in a given image based on the patterns they learn from the training data. For instance, an animal classifier would label the below image as “Crab” if the classifier had been trained on a good sample of crab images.
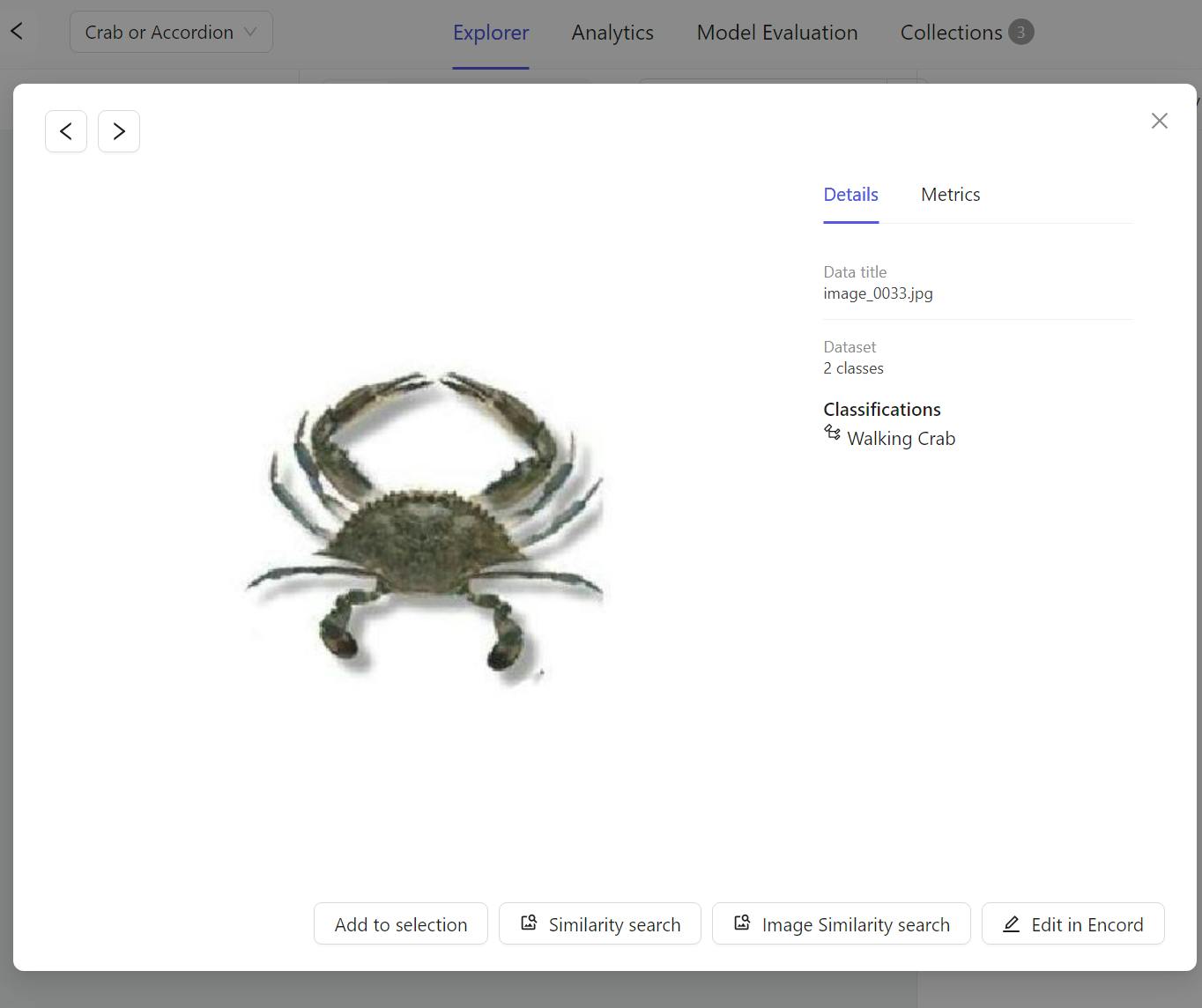
“Walking Crab” classification in Encord Active.
Face Recognition
Facial recognition tasks involve complex convolutional neural nets (CNNs) to learn intricate facial patterns and recognize faces in images.
Semantic Segmentation
You can identify each pixel of a given object within an image through semantic segmentation. For instance, the image below illustrates how semantic segmentation distinguishes between several elements in a given image on a pixel level.
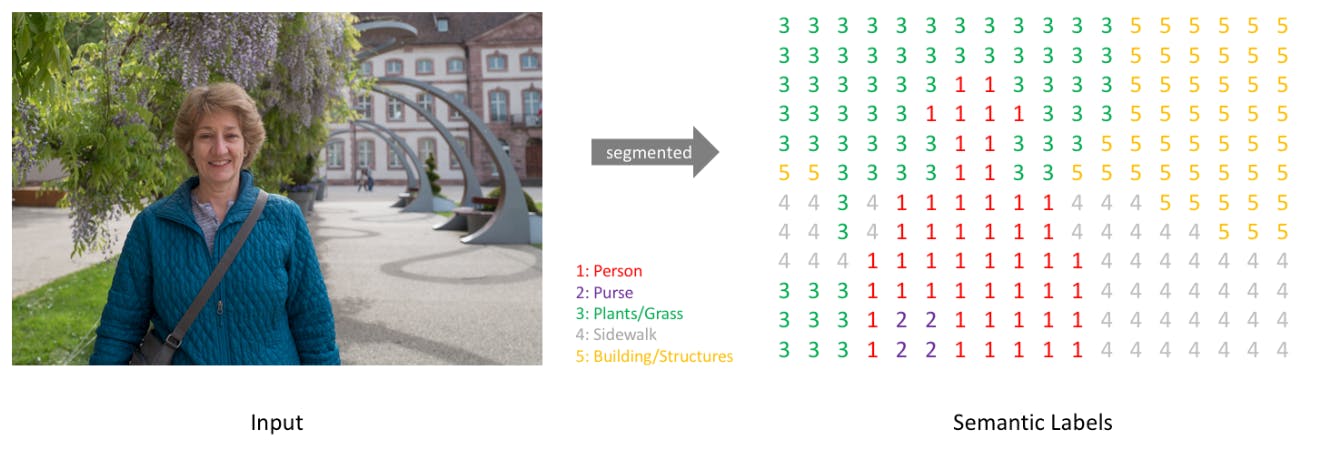
Text-to-Image Generative Models
Generating images from text is a new development in the generative AI space that involves writing text-based input prompts to describe the type of image you want. The generative model processes the prompt and produces suitable images that match the textual description.
Several proprietary and open-source models, such as Midjourney, Stable Diffusion, Craiyon, DeepFloyd, etc., are recent examples that can create realistic photos and artwork in seconds.
Role of Data Annotation In Curating Computer Vision Data
Computer vision tasks require careful data annotation as part of the data curation process to ensure that models work as expected.
Data annotation refers to labeling images (typically in the training data) so the model knows the ground truth for accurate predictions.
Let’s explore a few annotation techniques below.
- Bounding Box: The technique annotates a bounding box around the object of interest for image classification and object detection tasks.
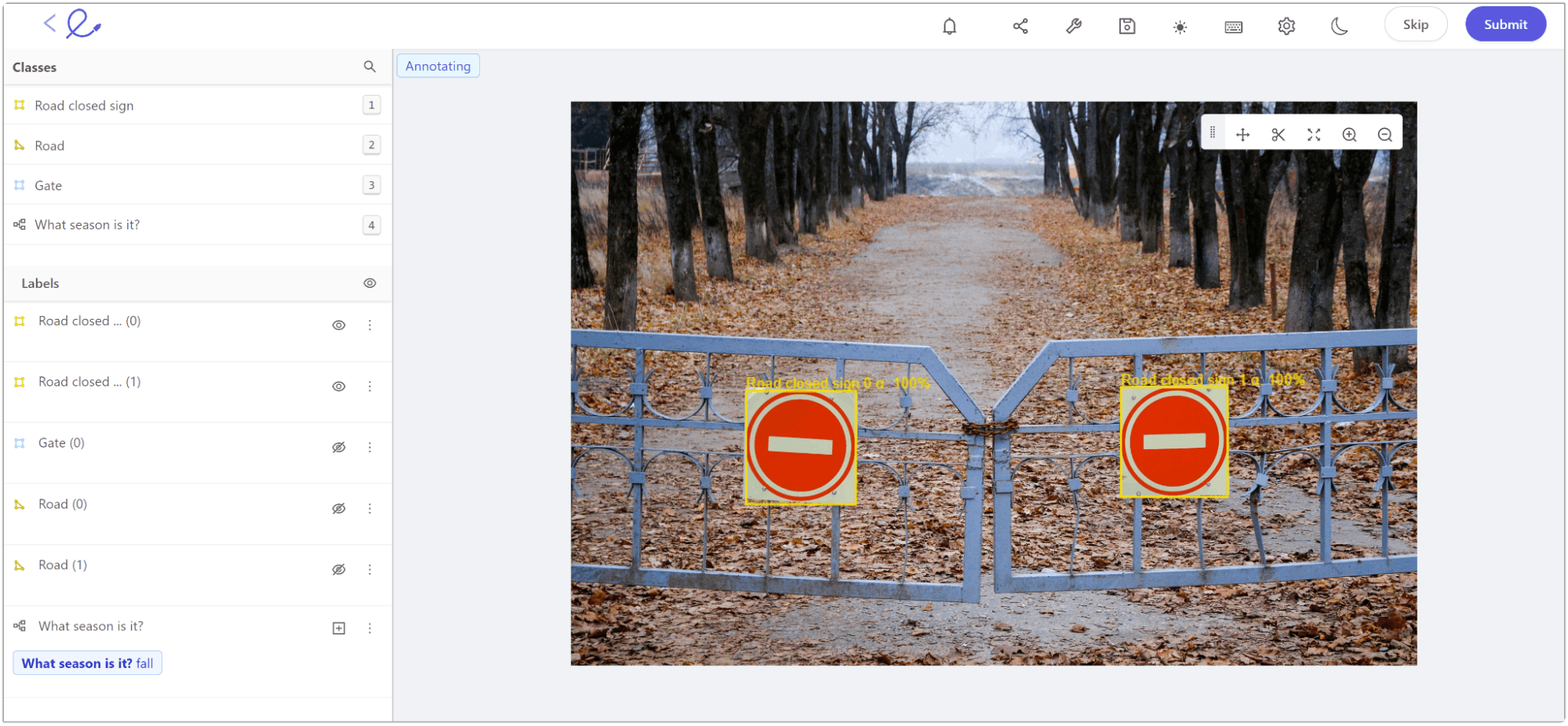
An example of bounding box annotation within Encord Annotate.
- Landmarking: In landmarking, the objective is to annotate individual features within an image. It’s suitable for facial recognition tasks.

An example of landmarking to label different facial features
- Tracking: Tracking is useful for annotating moving objects across multiple images.
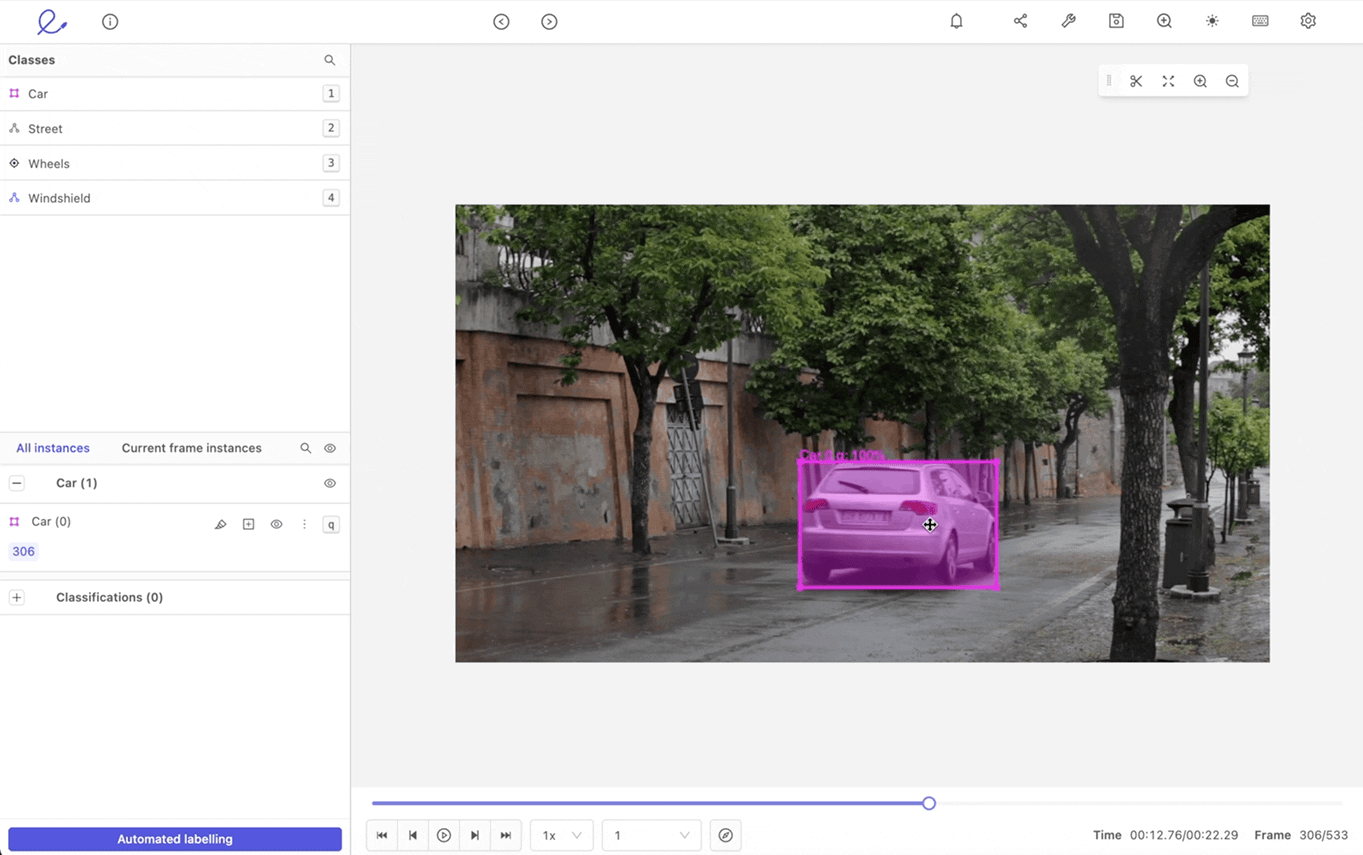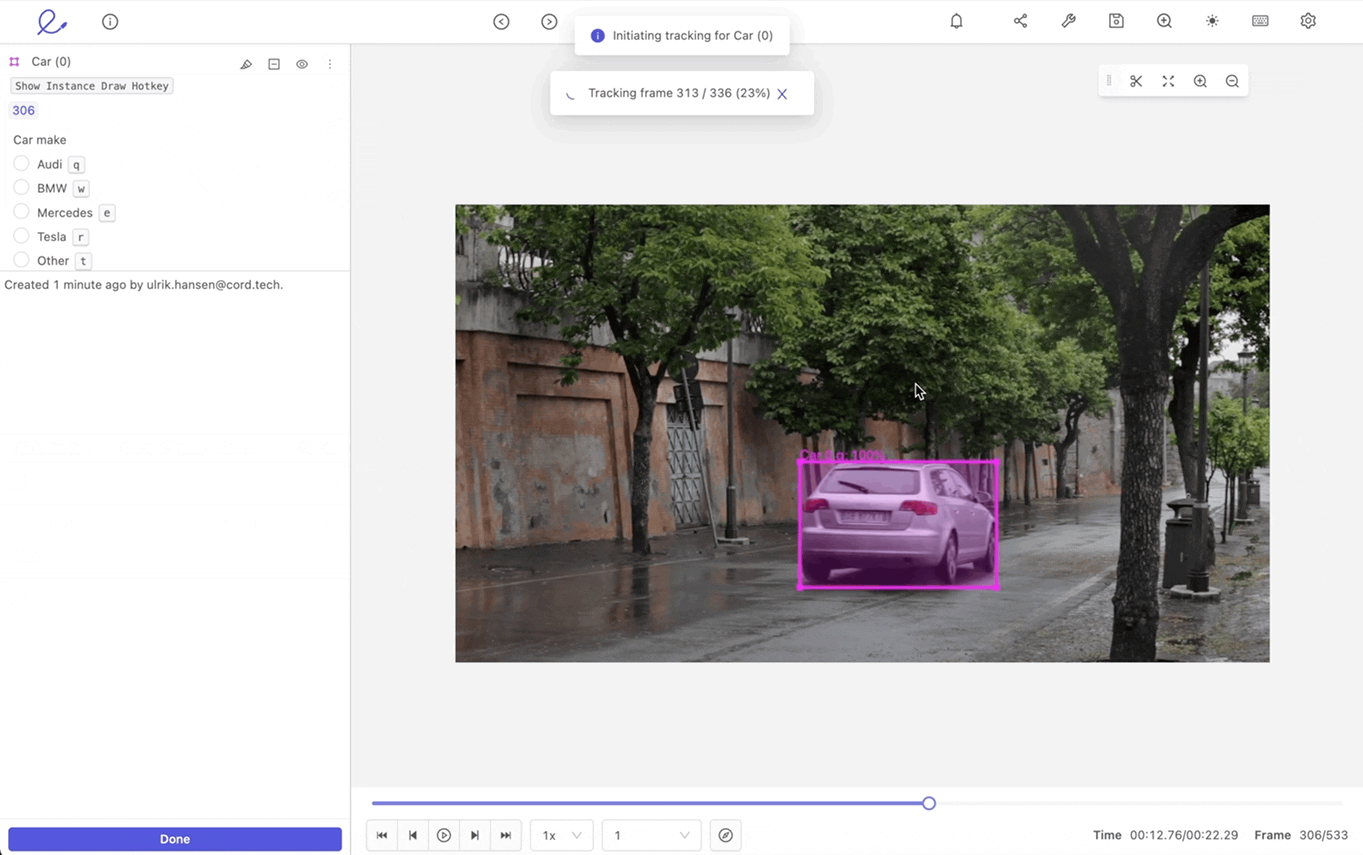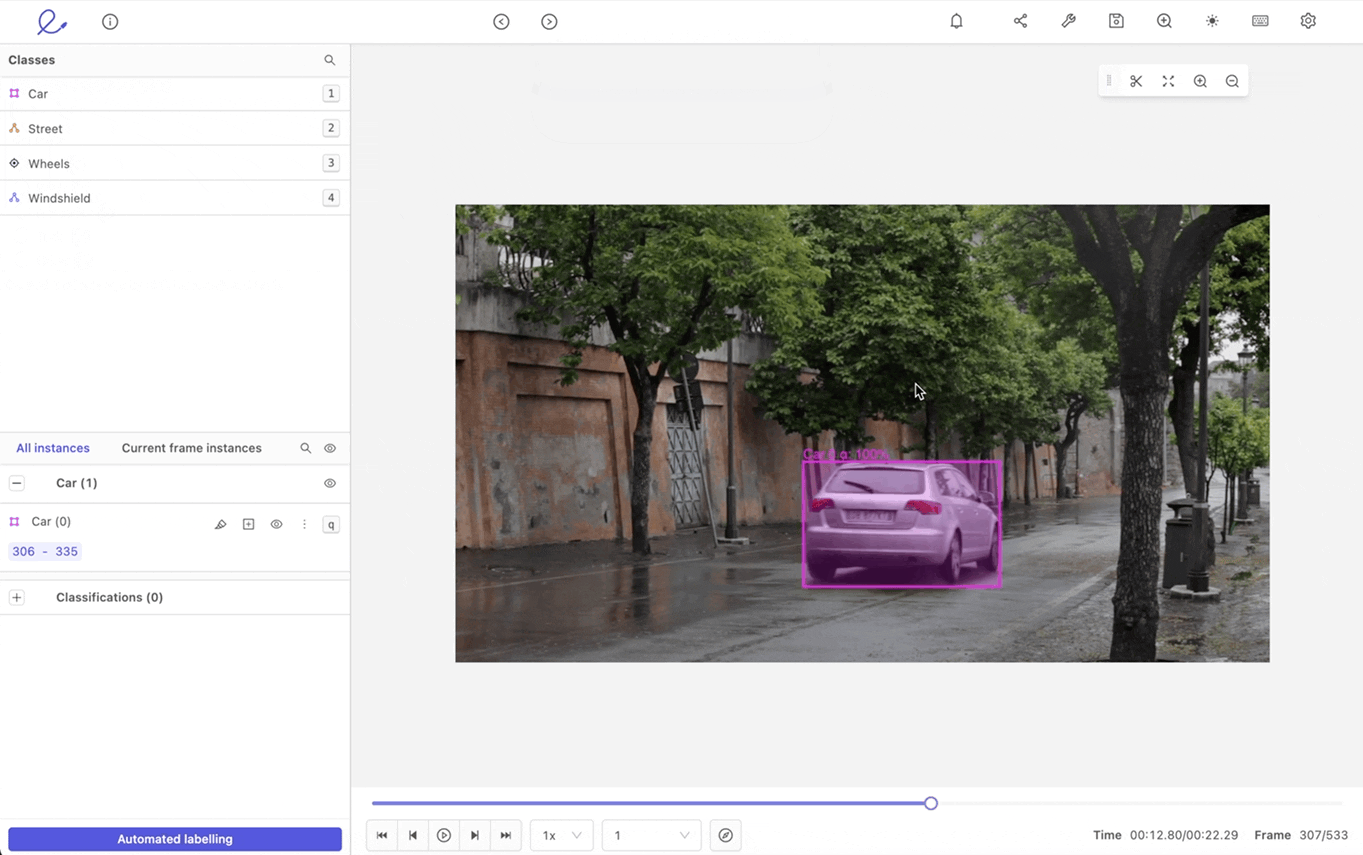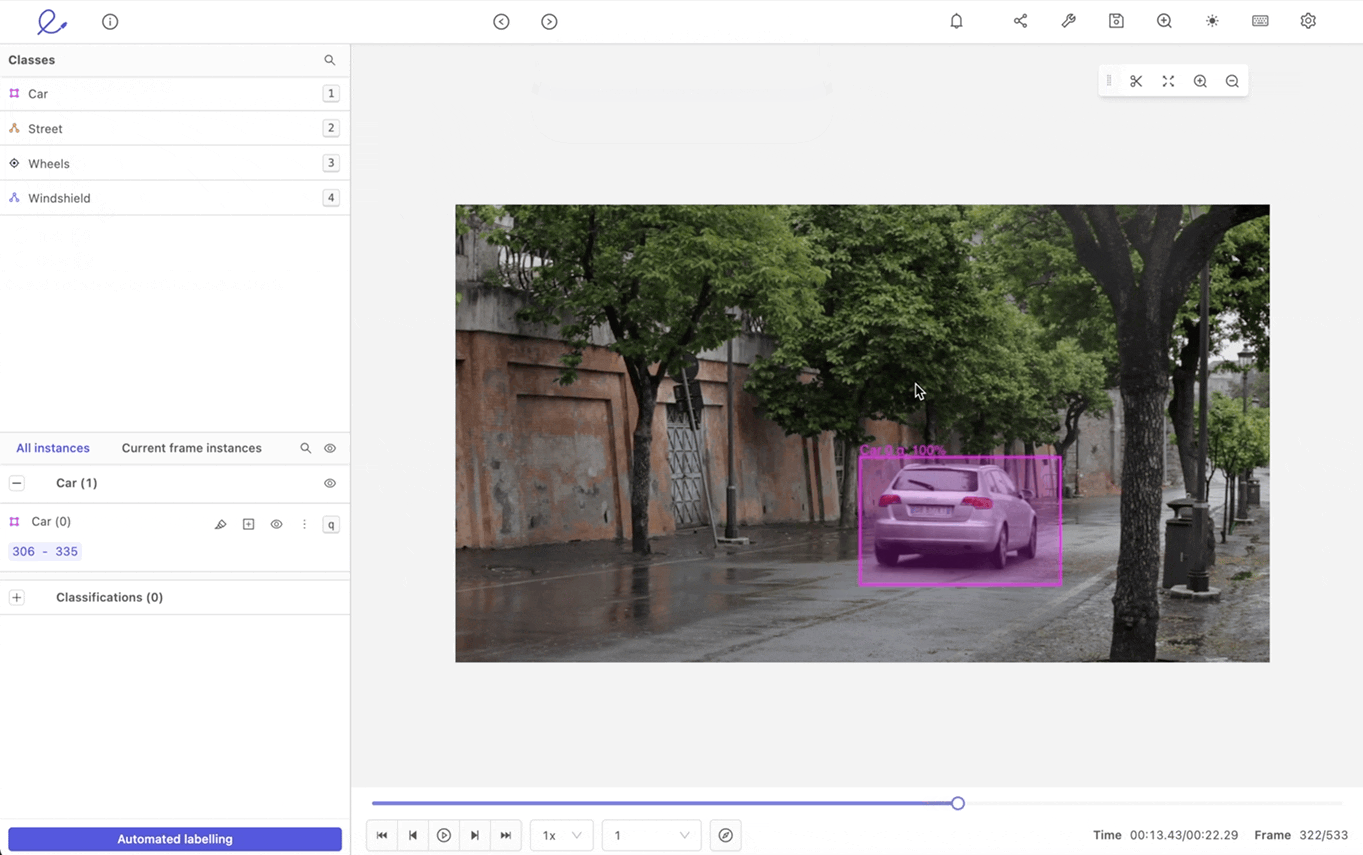
An example of tracking a moving car label within Encord.
General Considerations for Annotating Image Data
Data annotation can be time-consuming as it requires considerable effort to label each image or object within an image. It’s advisable to clearly define standard naming conventions for labeling to ensure consistency across all images.
You can use labeled data from large datasets, such as ImageNet, which contains over a million training images across 1,000 object classes. It is ideal for building a general-purpose image classification model.
Also, it’s important to develop a robust review process to identify annotation errors before feeding the data to a CV model. Leveraging automation in the annotation workflow reduces the time to identify those errors, as manual review processes are often error-prone and costly.
Moreover, your team can employ innovative methods like active learning and image embeddings to improve data annotation accuracy. Let’s look at them briefly below.
Active Learning
Instead of labeling all the images in a dataset, an active learning workflow allows you to annotate only a few valuable images and use them for training. It uses an informativeness score that helps decide which image will be most beneficial to improving performance.
For example, in a given dataset containing 1,500 images, the active learning method identifies the most valuable data samples (let’s say 100 images) for annotation, allowing you to train your ML model on a subset of labeled images and validate it on the remaining unlabeled 1,400 images.
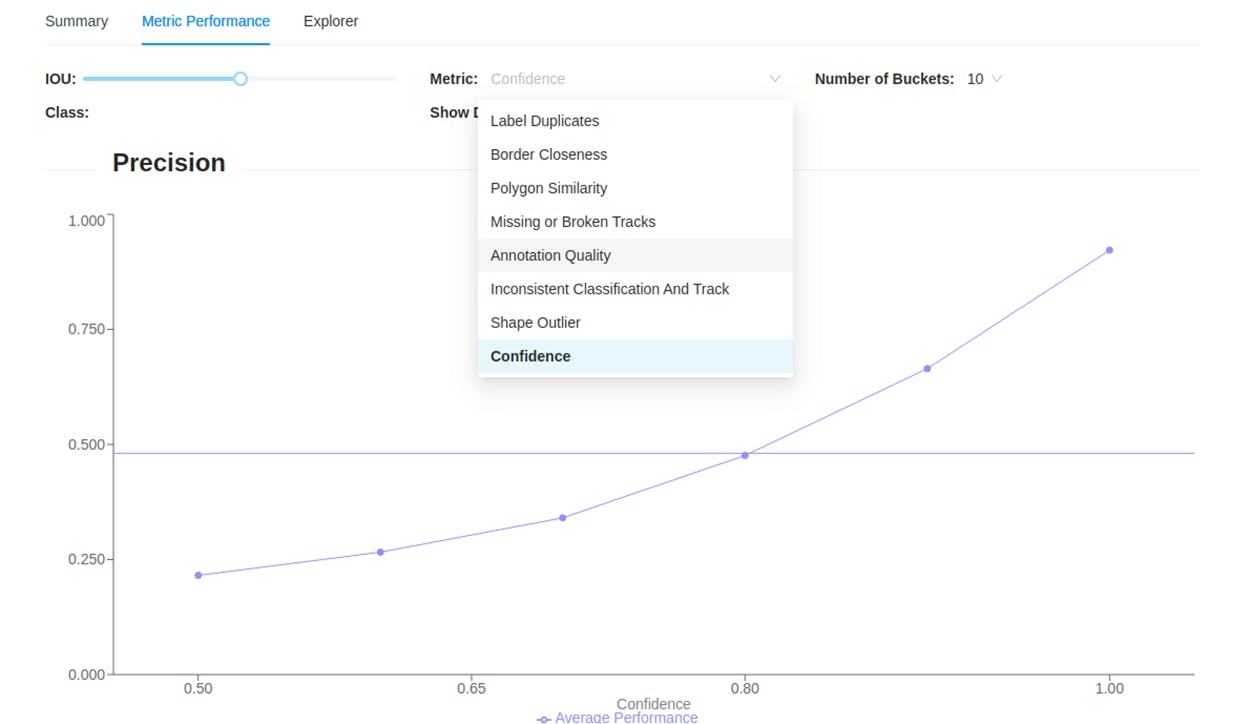
Metric performance explorer in Encord Active.
You can use a data and model evaluation tool like Encord Active to assign confidence scores to the 1,400 images and send them upstream for data annotators on Encord Annotate to cross-check images with the lowest scores and re-label them manually. Through this, active learning reduces data annotation time and can significantly improve the performance of your computer vision models.
Image Embeddings
Image embeddings are vectorized versions of image data where similar images have similar numerical vector representations.
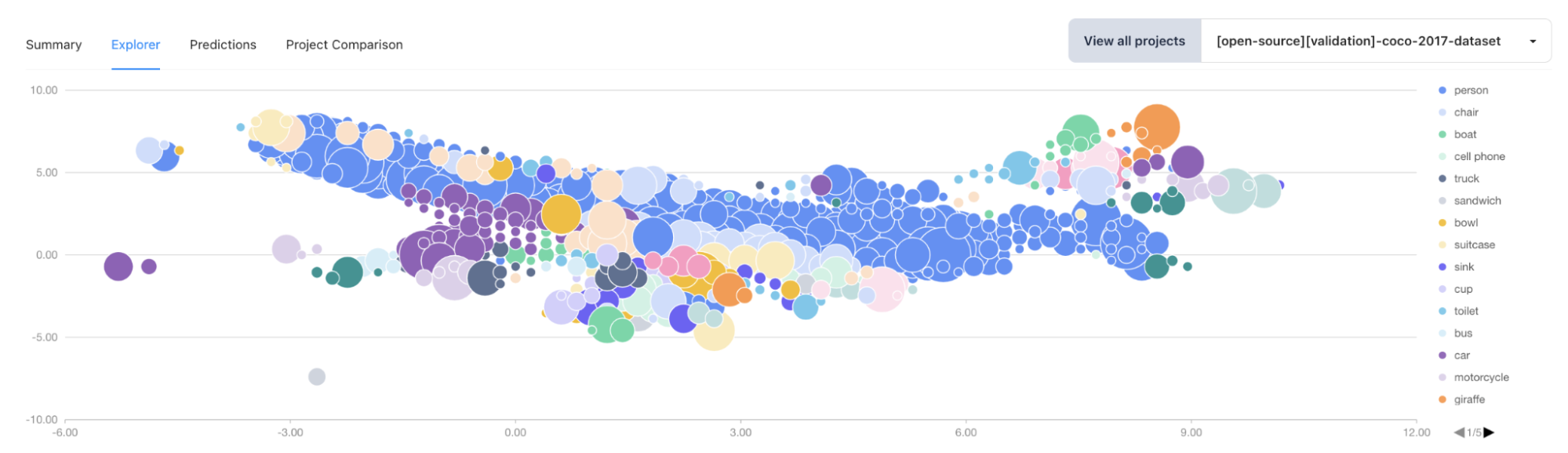
Data embeddings plot in Encord Active.
Typically, image embeddings are helpful for semantic segmentation tasks as they break down an image into relevant vectors, allowing computer vision models to classify pixels more accurately.
They also help with facial recognition tasks by representing each facial feature as a number in the vector. The model can better use the vectorized form to distinguish between several facial structures.
Embeddings make it easier for algorithms to compute how similar two or more images are numerically. It helps practitioners annotate images more accurately.
Lastly, image embeddings are the backbone of generative text-to-image models, where practitioners can convert text-image pairs into embeddings. For example, you can have the text “image of a dog” and an actual dog’s image paired together and converted into an embedding. You can pass such embeddings as input to a generative model so it learns to create a dog’s image when it identifies the word “Dog” in a textual prompt.
Challenges in Data Curation
Data provides the foundation for building high-quality machine learning models. However, collecting relevant data comes with several challenges.
- Evolving Data Landscape: With the rapid rise of big data, maintaining consistent and accurate data across time and platforms is challenging. Data distributions can change quickly as more data comes in, making data curation more difficult.
- Data Security Concerns: Edge computing is giving rise to security issues as organizations must ensure data collection from several sources is secure. It calls for robust encryption and de-identification strategies to protect private information and maintain data integrity throughout curation.
- Data Infrastructure and Scalability: It’s difficult for organizations to develop infrastructure for handling the ever-increasing scale of data and ML applications. The exponential rise in data volume is causing experts to shift from code-based strategies to data-centric AI, primarily focusing on building models that help with data exploration and analysis.
- Data Scarcity: Mission-critical domains like healthcare often need more high-quality data sources. This makes it difficult for you to curate data and build accurate models. Models built using low-quality data can more likely give false positives, which is why expert human supervision is required to monitor the outcomes of such models.
Using Encord Index for Data Curation
Encord’s end-to-end training data platform enables you to curate and manage data. The platform you can quickly identify and rectify data quality issues, manage metadata, and leverage automated workflows to streamline the curation process. Features such as vector embeddings, AI-assisted metrics, and model predictions help in finding labeling errors quickly, ensuring high-quality datasets for training.

In this section, you will see how the different stages of the data curation workflow work in Encord.
Data Annotation and Validation
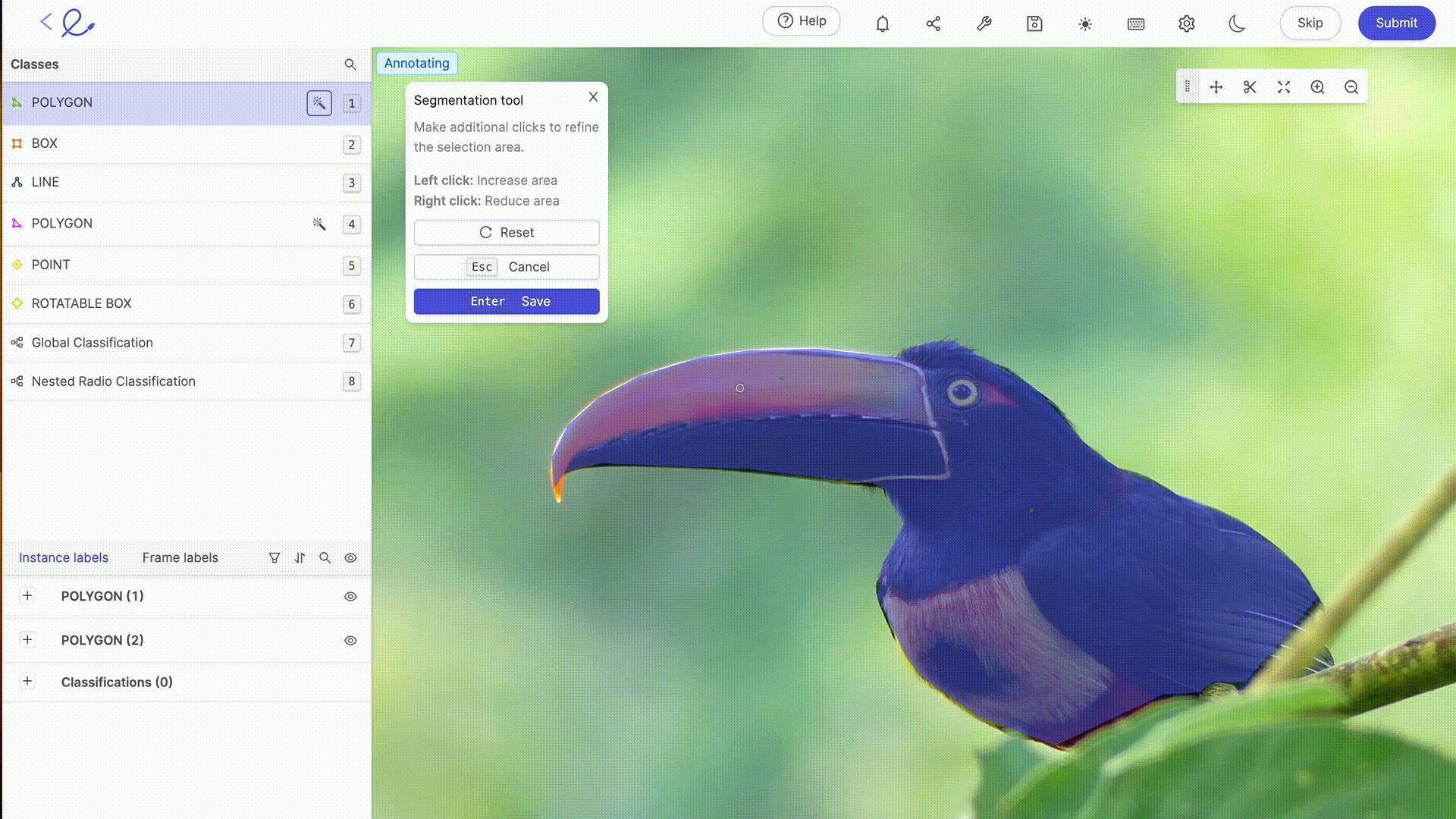
After collecting your dataset, you need to annotate it and validate the quality of your annotations and images. For this stage, Encord Annotate supports all key annotation types, such as bounding boxes, polygons, polylines, image segmentation, and more, across various visual formats.
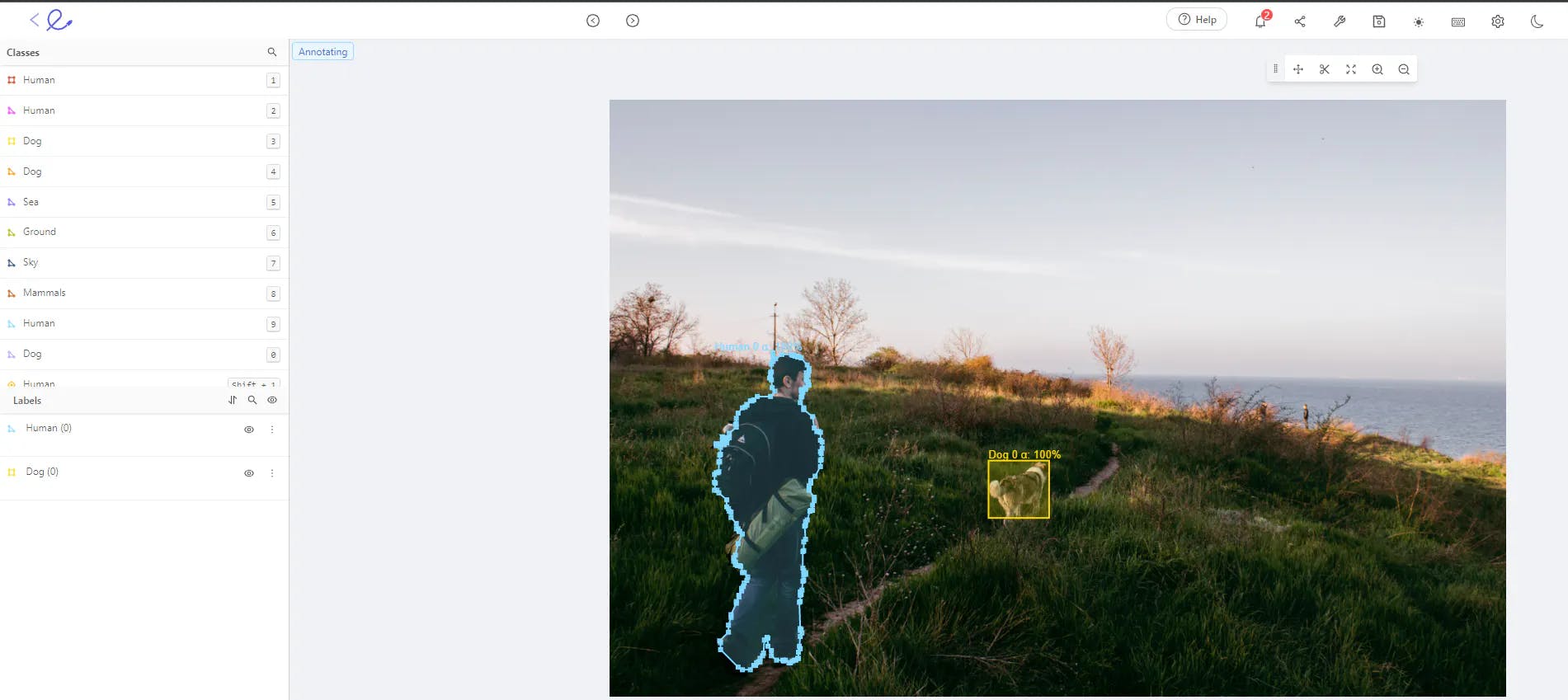
Polygon and bounding box annotations in Encord Annotate.
It includes auto-annotation features such as Meta’s Segment Anything Model and other AI-assisted labeling techniques that can aid your annotation process and reduce the chances of annotation errors occurring.
Annotate provides data integrations into popular storage services and warehouses, so you do not have to worry about moving your data.
Annotate’s quality assessment toolkit helps scale your data validation processes by spotting hidden errors in your training dataset. You can also use Annotate to automatically find classification and geometric errors in your training data, ensuring that your labels are of the highest possible quality before they go into production.
The illustration below shows what you can expect the annotation and validation workflows to look like with Encord:
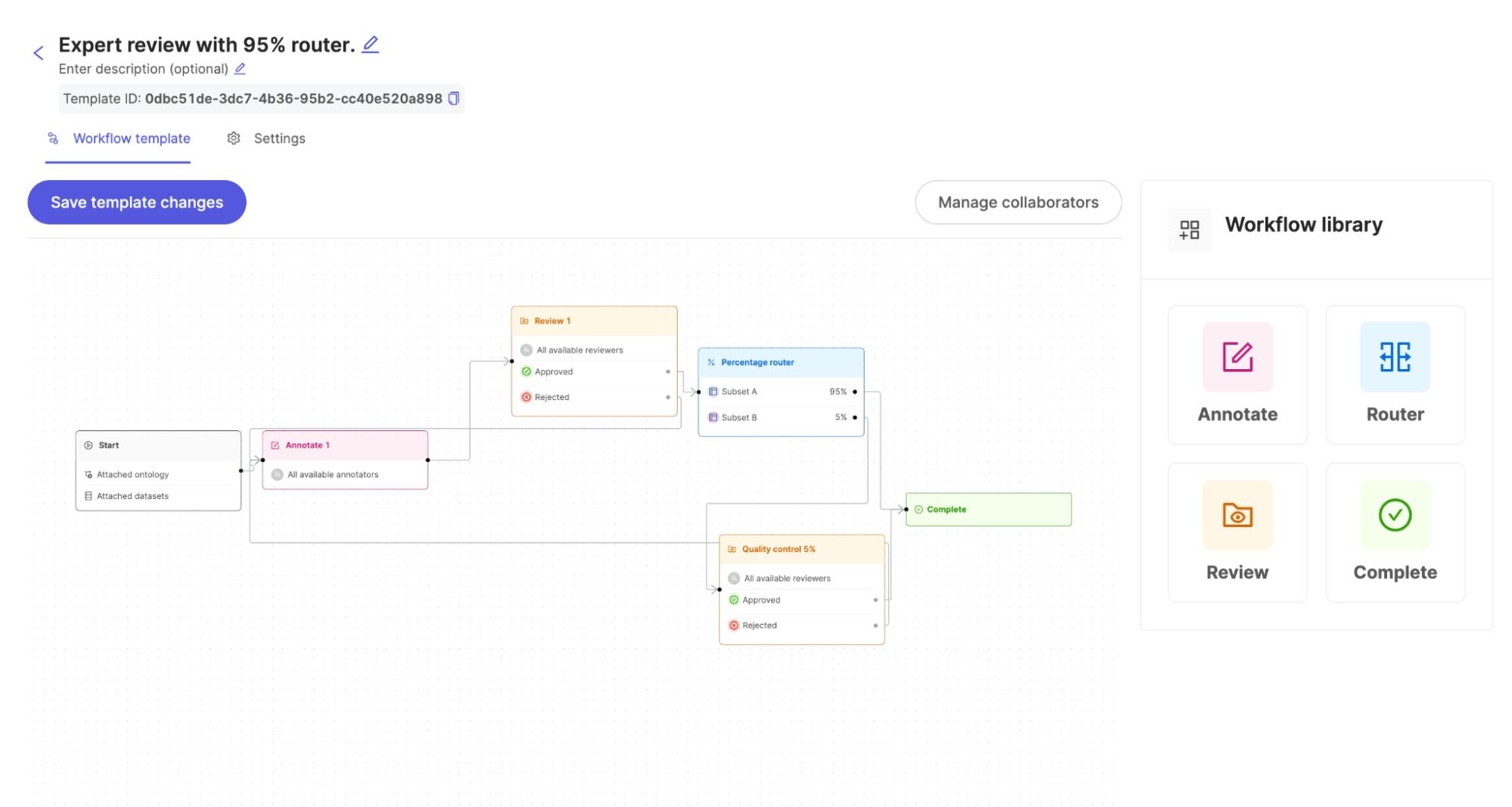
Annotation and validation workflow with Encord.
Data Cleaning
With Encord Active, you can refine the dataset by efficiently identifying and removing duplicate entries, for example. How does it do this? Active computes the image embeddings and uses algorithms to evaluate the dataset based on objective quality metrics like “Uniqueness,” “Area,” “Contrast,” and so on.
Try Below
In this example, you will identify outlier images using the embeddings view, use the "similarity search" to find similar objects, select multiple images and then add to a collection.
Normalization
While curating your data, you might want to adjust your values on a consistent scale. In color images, each pixel has three values (one for each of the red, green, and blue channels), usually ranging from 0 to 255. Normalization rescales these pixel values to a new range.
Exploring your data distribution provides a clear lens to understand the images you want to normalize to a standard range, often 0 to 1 or -1 to 1. In the workflow below, you can see the distribution of Red, Blue, and Green pixel values across an entire image set.
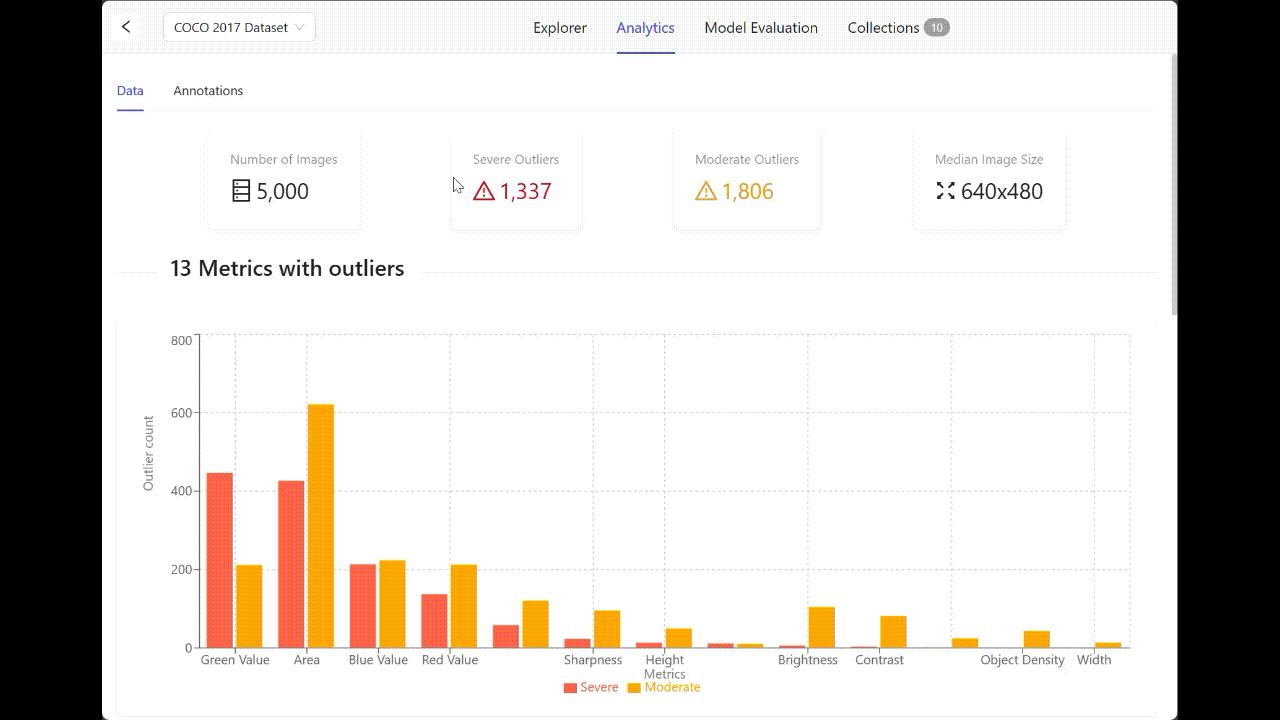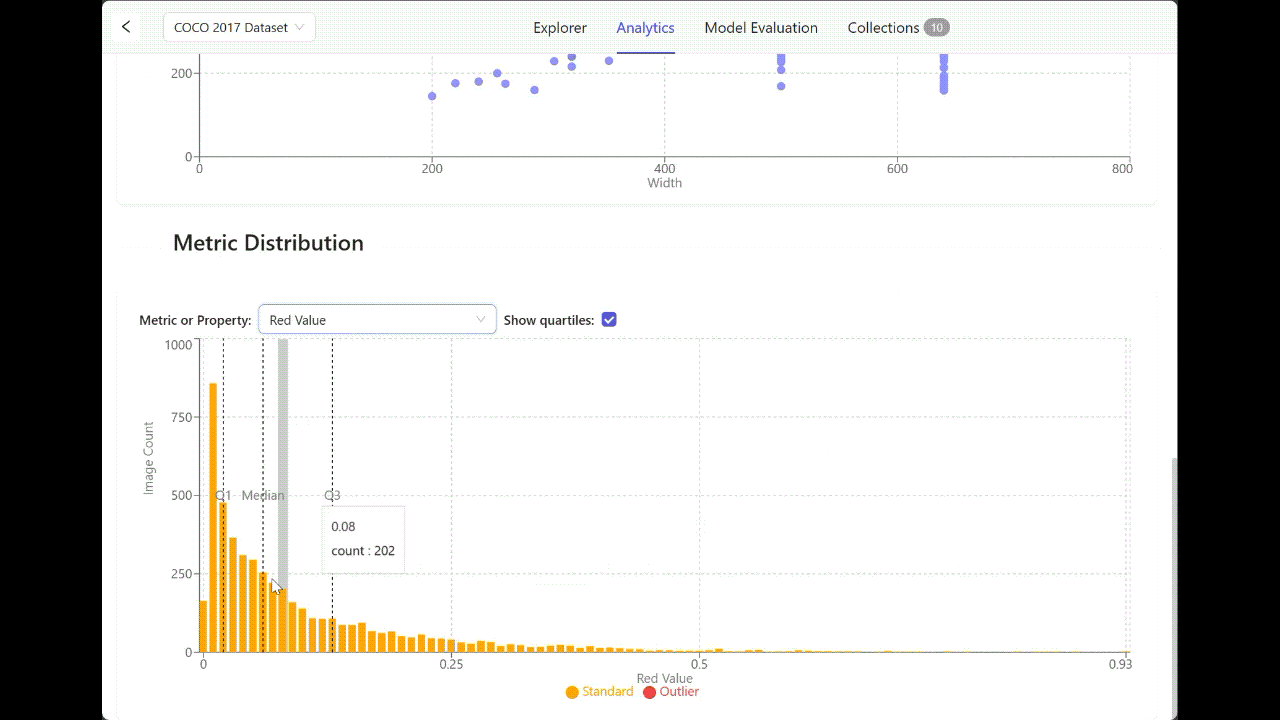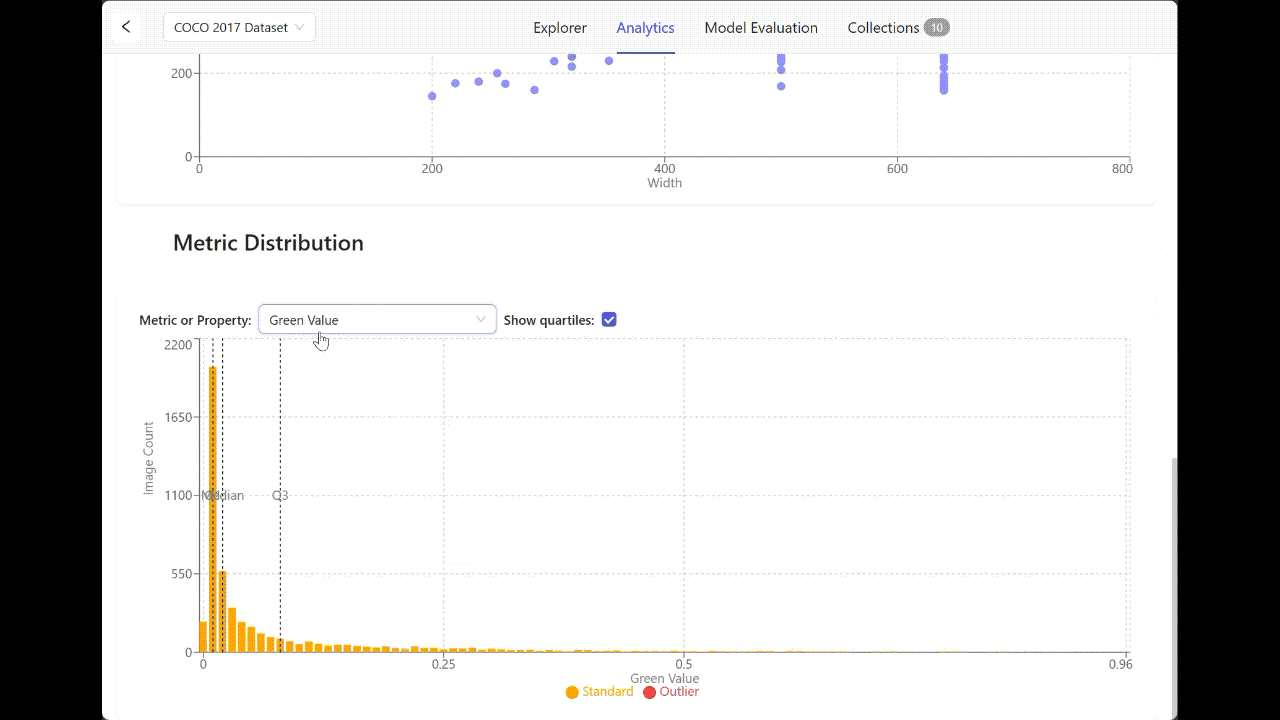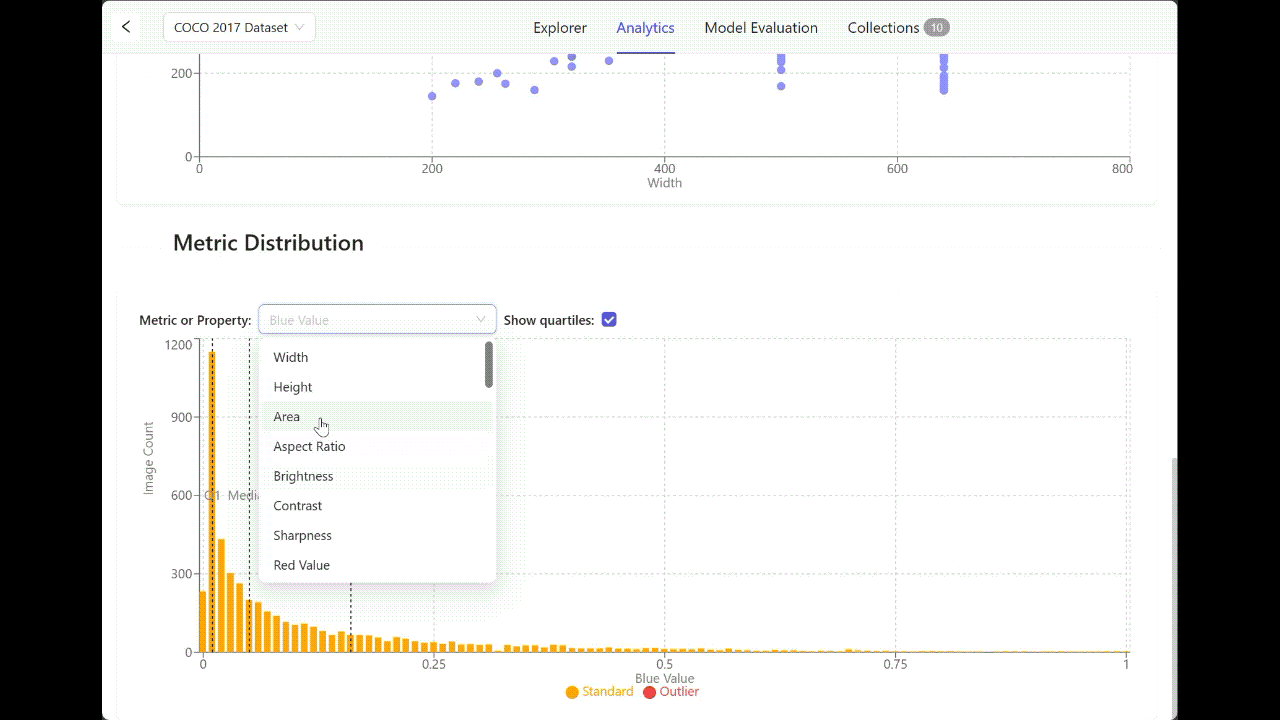
Metric distribution in Encord Active.
De-identification
Safeguarding sensitive information is fundamental to building trust and ensuring the ethical use of data in machine learning and computer vision applications. Active can aid the de-identification process by allowing you to identify images through textual prompts that likely contain Personally Identifiable Information (PII). Annotate can help you anonymize or de-identify PII programmable from the SDK.
Finding human faces in Encord Active.
Data curation is a critical determinant of the success of computer vision projects as businesses increasingly depend on AI for better user applications and efficient business operations.
However, the complexity and challenges of data curation, especially in computer vision, call for the right tools to streamline this process. The Encord platform provides the tools to curate and manage your data pipelines.
Data Curation: Key Takeaways
As companies gravitate more toward AI to solve business problems using complex data, the importance of data curation will increase significantly. The points below are critical considerations organizations must make to build a successful data curation workflow.
- Data curation is a part of data management. As such, data curation in isolation may only solve a part of the problem. Encord Index offers robust tools for holistic data curation within AI workflows.
- The curation workflow must suit specific requirements. A workflow that works for a particular task may fail to produce results for another. Encord allows you to customize and automate your data curation workflow for any vision use case.
- Encord Index enhances data management by offering powerful tools for organizing, visualizing, and ensuring data
- The right combination of data curation tools can accelerate the development of high-quality training data.
- Encord Annotate provides features to label visual data and manage large-scale annotation teams using customizable workflows and quality control tools.
- With Encord Active, you can find failure modes, surface poor-quality data, and evaluate your model’s performance.
Data curation is an ongoing process, and each organization must commit to robust data curation practices throughout the model building, deployment, and monitoring stages while continuing to improve the curation workflow as data evolves.

Frequently asked questions
Data curation is collecting, cleaning, selecting, and organizing data for AI models so data scientists can get complete, accurate, relevant, and unbiased data for model training, validation, and testing. It’s an iterative process that companies must follow even after model deployment to ensure incoming data matches the data in the production environment.
While data curation is the responsibility of the entire data team within an organization, specialist data curators specifically look after the curation process to ensure the data is clean, accurate, and consistent. They work with data stewards to align data curation with set policies and standards for overall data management.
Data collection is the initial step in the data lifecycle, while data curation involves selecting relevant data for specific modeling tasks and organizing it for better usability and searchability.
Data curation enhances healthcare data's quality, completeness, and usability by ensuring it passes through all the steps, such as cleansing, feature extraction, augmentation, etc. Healthcare analytics apps can use curated healthcare datasets to perform tasks more efficiently, like data visualization, patient stratification, predictive modeling, etc.
Natural Language Processing (NLP) involves models that understand text and everyday speech as accurately as humans. As such, annotation techniques for NLP differ from those used in CV. Typical techniques include labeling sentiments, parts-of-speech tagging, keyphrase labeling, etc.
Encord's platform offers robust data curation capabilities that help in cleaning datasets by removing duplicates and low-quality images. This ensures that only the most relevant images or videos are collected and sent to the annotation platform, improving the overall quality and performance of machine learning models.
Encord prioritizes data curation, allowing users to organize and balance datasets based on specific criteria such as image size, brightness, and source field. This structured approach enables users to effectively manage and select diverse datasets for annotation, ultimately improving the quality of training data.
Encord provides tools that help streamline the data curation process, allowing users to balance datasets by incorporating various sources and qualities of images. This includes assessing the impact of different retailers and shelf appearances, ensuring a diverse representation in the training data.
Encord provides robust tools focused on curation and model evaluation, catering specifically to the needs of autonomous driving applications. These tools enable users to automate the identification of edge cases and anomalies in data, ultimately helping to build better models faster.
Encord's platform allows users to bring in datasets with detailed metadata, enabling effective filtering and exploration. Users can filter out unwanted signals, such as image quality issues, and focus on relevant views or attributes, making it easier to curate high-quality datasets.
Encord's curation tools allow you to filter and manage extensive datasets effectively. This capability enables you to streamline the process of identifying relevant images within a large collection, ensuring that your analysis focuses on the most pertinent data for your projects.
The Encord platform allows users to filter data based on various characteristics, such as brightness, RGB values, or specific scenarios like low lighting or night footage. This capability enhances the exploration of datasets for targeted annotation and quality assurance.
Encord offers advanced filtering capabilities that allow users to identify and manage image data based on specific criteria, such as brightness and clarity. This ensures that only high-quality images are retained in the dataset, enhancing the overall quality of analysis.
Encord offers robust data curation capabilities that streamline the process of finding high-quality data. Users can manage data more effectively without relying solely on Jupyter notebooks or third-party platforms, allowing for a more integrated workflow.
Curation in Encord's platform plays a critical role in quickly surfacing and unlocking valuable data sets. This process allows teams to efficiently sift through large volumes of data, facilitating better insights and more effective model training.