An Overview of the Machine Learning Lifecycle

Machine learning (ML) is a transformative technology that has recently witnessed widespread adoption and business impact across industries. However, realizing the true business potential of machine learning is challenging due to the intricate processes involved in building an ML product across various stages, from raw data management and preparations to model development and deployment.
Therefore, organizations, especially emerging AI startups, must understand the entire ML lifecycle and implement best practices to build machine learning products in an efficient, reliable, secure, and scalable manner.
In this article, I will provide an overview of the various stages of the ML lifecycle and share hard-won practical insights and advice from working in the AI industry across big technology companies and startups. Whether you're a data scientist, an ML engineer, or a business leader, this overview will equip you with the knowledge to navigate the complexities of building and deploying ML products effectively.
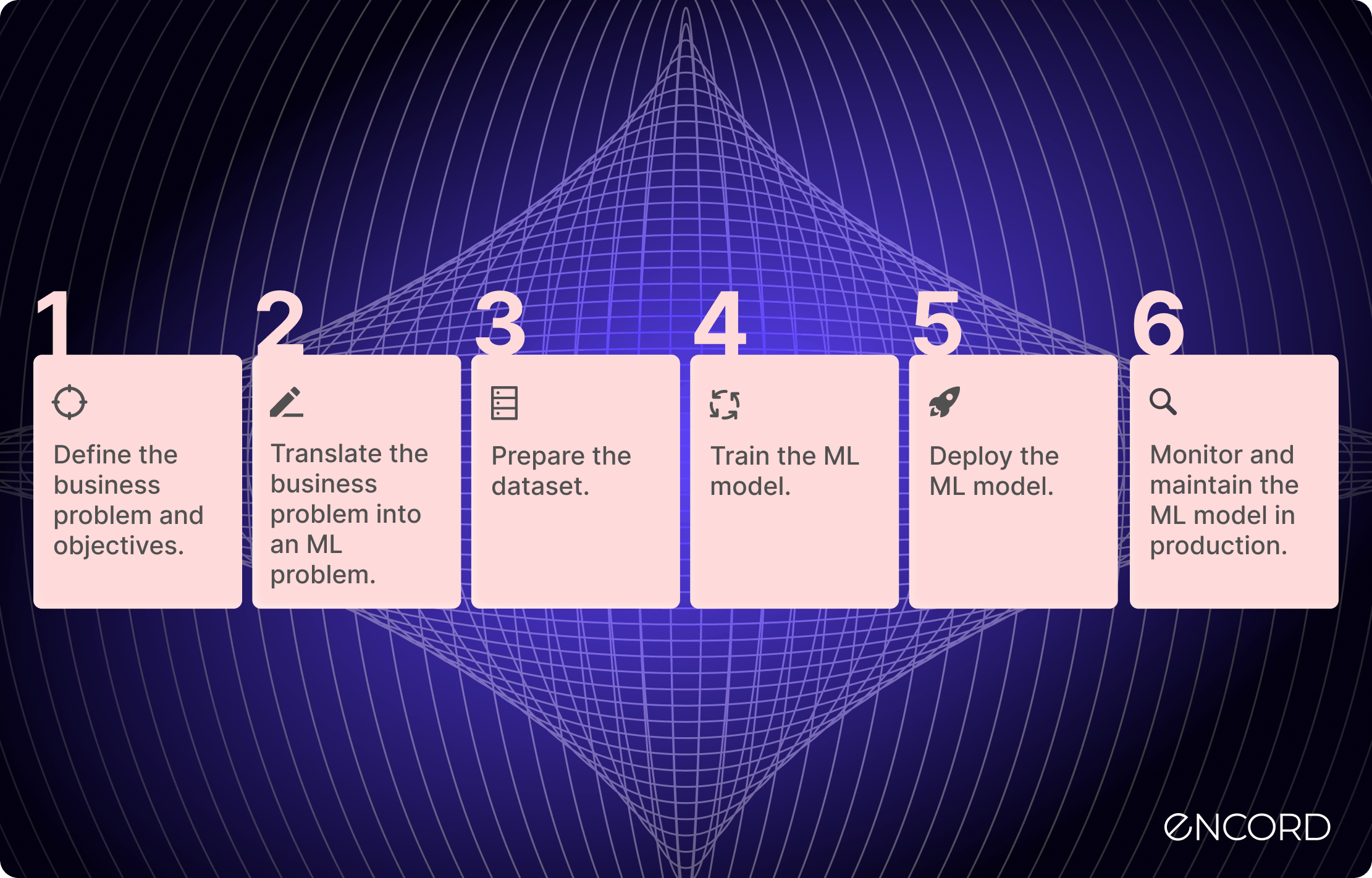
Here are the stages we will look at:
- Stage 1: Define the business problem and objectives.
- Stage 2: Translate the business problem into an ML problem.
- Stage 3: Prepare the dataset.
- Stage 4: Train the ML model.
- Stage 5: Deploy the ML model.
- Stage 6: Monitor and maintain the ML model in production.
Stage 1. Define the Business Problem and Objectives
In industry, it is important to understand that machine learning is a tool, and a powerful one at that, to improve business products, processes, and ultimately impact commercial goals. In some companies, ML is core to the business; in most organizations, it serves to amplify business outcomes.
The first stage in the machine learning lifecycle involves the conception and iterative refinement of a business problem aligned with the company’s short-term or long-term strategic goals. You must continuously iterate on the problem until its scope and objectives are finalized through the underlying market or customer research and discussions amongst the relevant stakeholders (including business leaders, product managers, ML engineers, and domain experts).
Using machine learning is a given to solve some business problems, such as reducing the cost of manually annotating images. However, for other problems, the potential of machine learning needs to be explored further by conducting research and analyzing relevant datasets.
Only once you form a clear definition and understanding of the business problem, goals, and the necessity of machine learning should you move forward to the next stage—translating the business problem into a machine learning problem statement.
Although this first stage involves little machine learning per se, it is actually a critical prerequisite for the success of any machine learning project, ensuring that the solution is not only technically viable but also strategically aligned with business goals.
Stage 2. Translate the Business Problem into an ML Problem
Translating a business problem, such as reducing the cost of manual image annotation, into a machine learning problem is a critical step that requires careful consideration of the specific objectives and the available data. However, the particular choice of modeling techniques or datasets to focus on, or whether to use classical machine learning or more advanced deep learning models, must be analyzed before proceeding.
Several approaches exist to solve the problem, and these need to be considered and prioritized based on the experience and intuition of the ML leadership
For instance, one might start with clustering algorithms to group similar images for image annotation. Computer vision models that determine whether two images are similar can achieve this. The next step might involve using pre-trained computer vision models like ResNet or Vision Transformers to annotate the images for the use case of interest, for instance, image segmentation.
Finally, the model-based annotations need human review to validate the utility of this ML-based method. In this way, you may propose a high-level problem statement and finalize it by considering the inputs and experience of the relevant machine learning team.
Once the machine learning-based approaches are finalized, the business project can be better managed regarding requirements, milestones, timelines, stakeholders, the number of machine learning resources to allocate, budget, success criteria, etc.
Stage 3. Data Preparation
With an apparent business problem and its corresponding machine learning formulation, the team has a clear roadmap to build, train, and deploy models.
Data preparation and engineering are the next steps in building the ML solution. This involves multiple processes, such as setting up the overall data ecosystem, including a data lake and feature store, data acquisition and procurement as required, data annotation, data cleaning, data management, governance, and data feature processing.
In large ML organizations, there is typically a dedicated team for all the above aspects of data preparation. For the particular business problem, the team needs to ensure that carefully cleaned, labeled, and curated datasets of high quality are made available to the machine learning scientists who will train models on the same datasets.
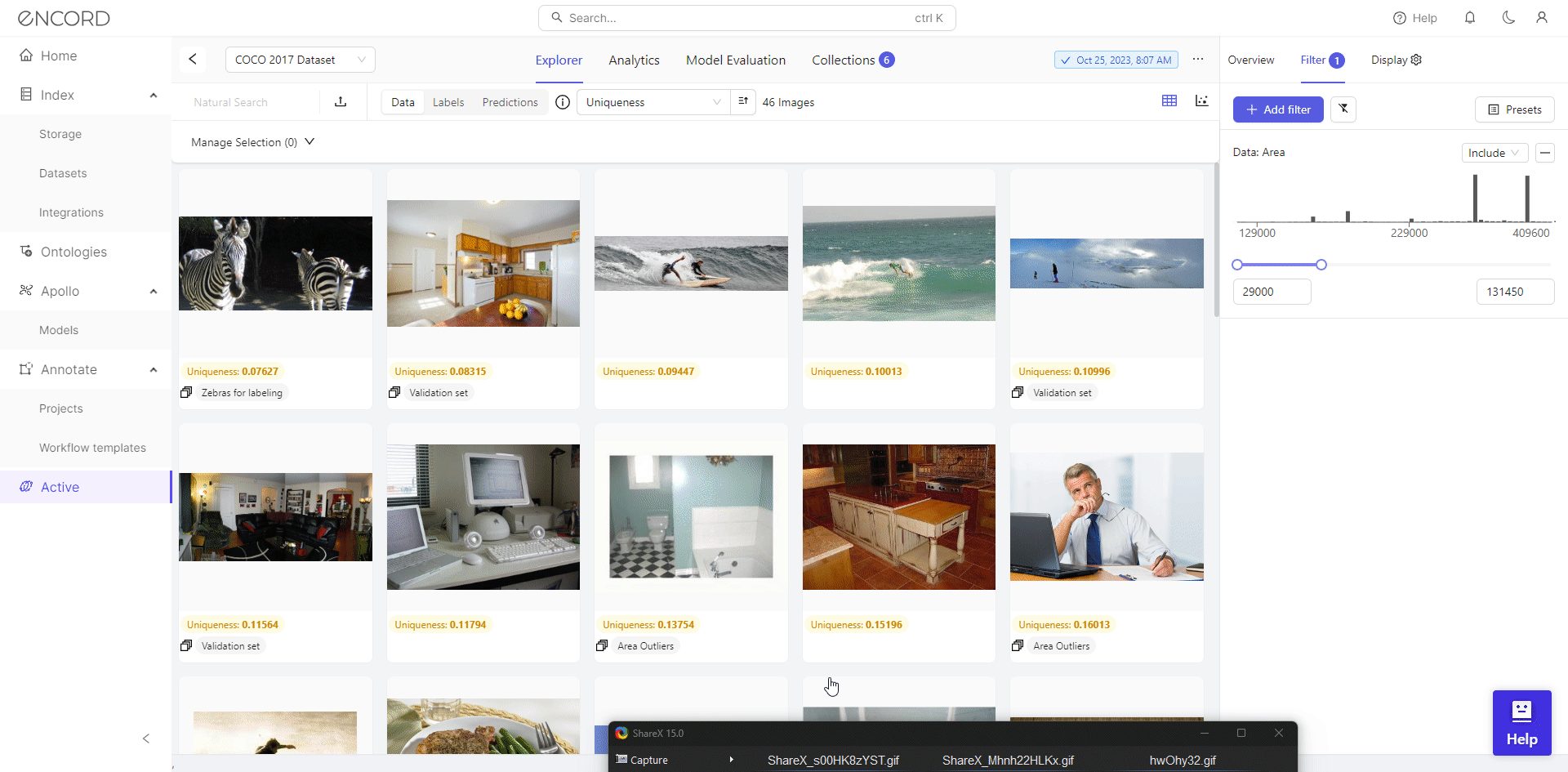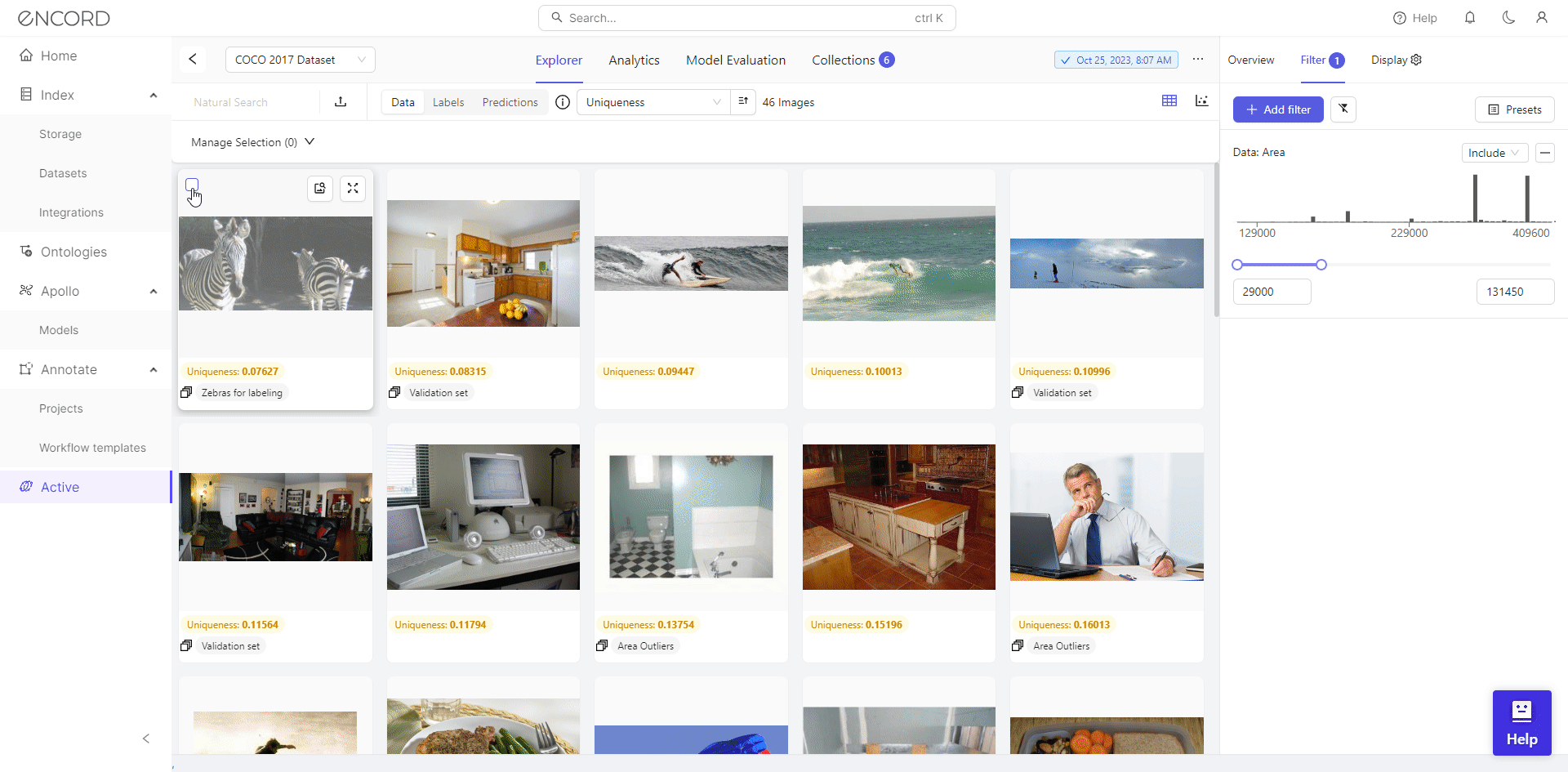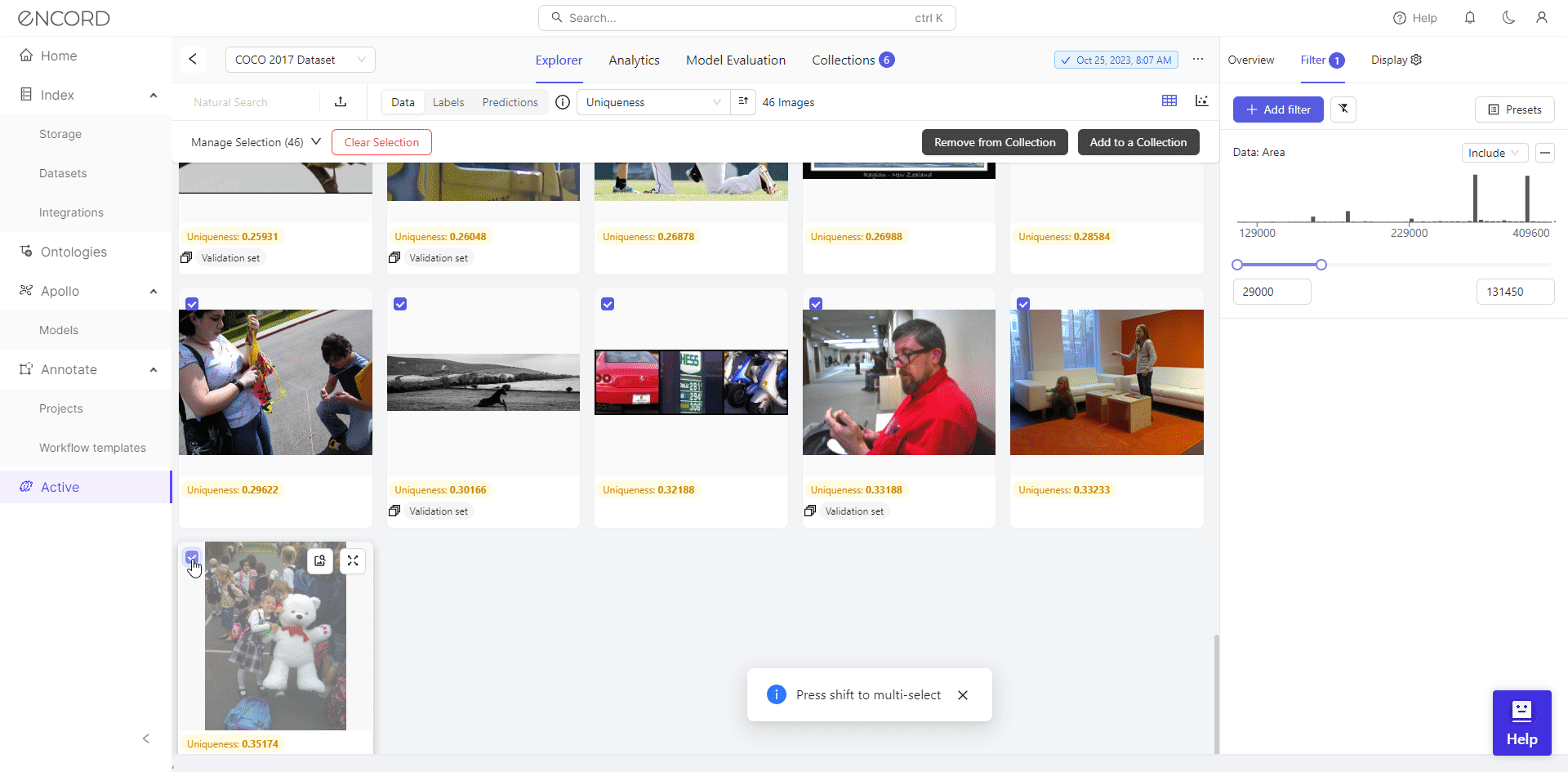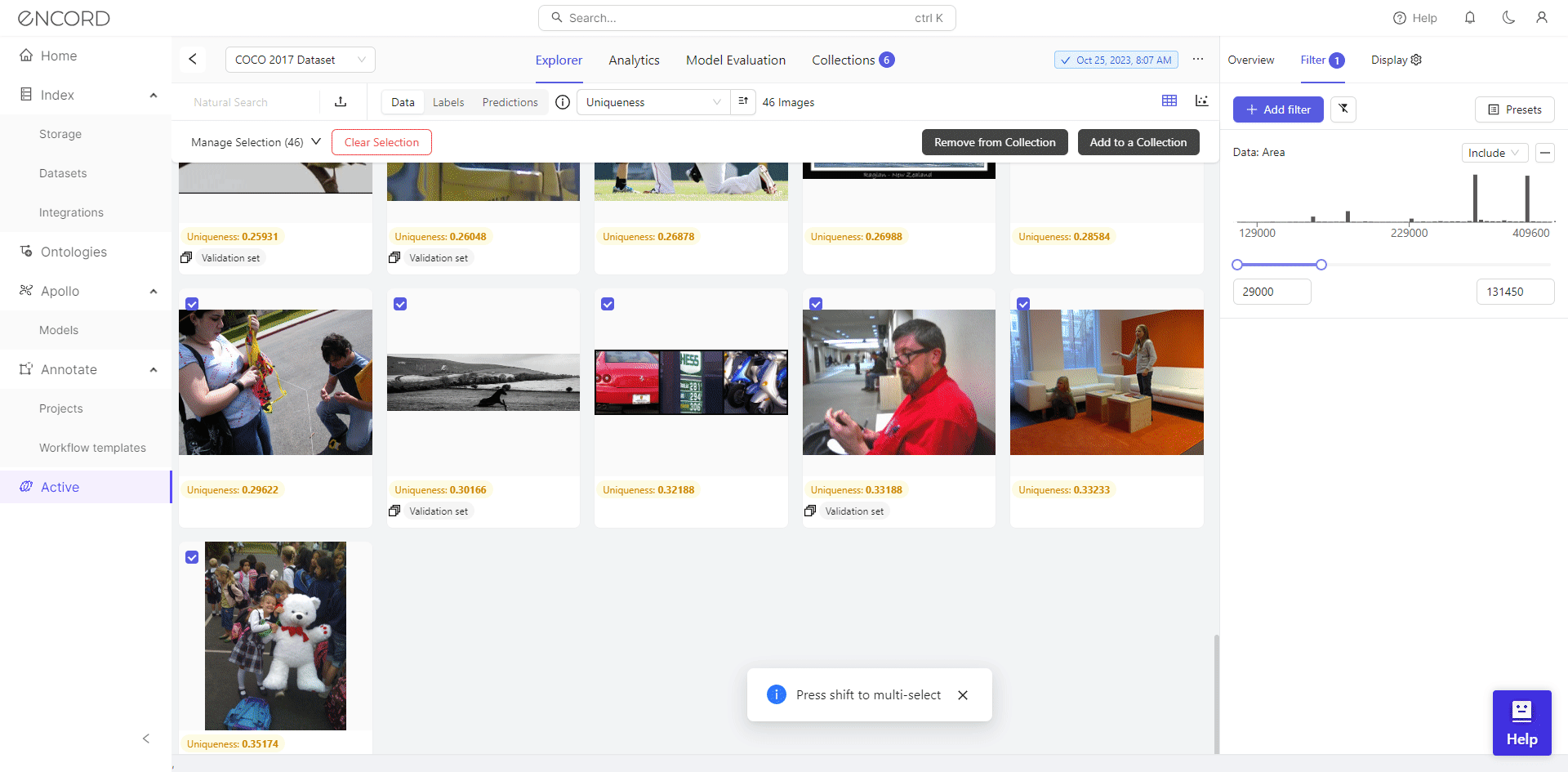
Curating datasets by area metric using Encord Active
Sometimes, you may need to acquire data externally by purchasing it from data brokers, web scraping, or using machine learning based approaches for generating synthetic data. After that, you may need to label data for supervised machine learning problems and subsequently clean and process it to create features relevant to the use case. These features must be stored in a feature store so that data scientists can efficiently access and retrieve them.
In addition to the actual data preparation and processing work, most organizations must also invest in establishing a data governance and management strategy.
Adopting a data-centric approach to your ML projects has become increasingly crucial. As organizations strive to develop more robust and effective deep learning models, the spotlight has shifted toward understanding and optimizing the data that fuels these systems. As you prepare your datasets, understanding the significance, key principles, and tools to implement this approach will set your project up for success.
Stage 4. Model Training
With a training dataset ready, you can now build models to solve the particular use case. Conduct preliminary research on choosing relevant models based on a literature review, including papers, conference proceedings, and technical blogs, before you start training the models.
It is also crucial to carefully define the relevant set of model metrics. The metrics should be relevant to the use case and not just include accuracy as a metric by default. For instance, IoU (Intersection Over Union) is a more appropriate metric for object detection and segmentation models. At the same time, the BLEU score is a relevant metric for measuring the performance of neural machine translation models. It's critical to consider multiple metrics to capture different performance aspects, ensuring they align with the technical and business objectives.
Model training is typically done in Python notebooks such as Jupyter or Google Colaboratory with GPUs for handling large neural network models. However, conducting model training experiments using platforms that enable experiment tracking and visualization of results is helpful in promoting reproducible research and effective stakeholder collaboration. Apart from versioning the underlying code, it is really important to version the dataset, the model, and associated hyperparameters.
In some cases, a single model may not achieve the required performance levels, and it makes sense to ensemble different models together to attain the required performance. Analyze the model's results carefully on the validation dataset, ideally reflecting the distribution of the real-world data.
One approach you could take is to use tools that help you explore and understand the distribution of your validation datasets and how the model performs on them. Also, consider quality metrics that give you a nuanced, detailed evaluation of your model’s performance on the training and validation sets.
Encord Active uses a data-centric approach to evaluate how well your model will generalize to real-world scenarios using built-in metrics, custom quality metrics, and ML-assisted model evaluation features.
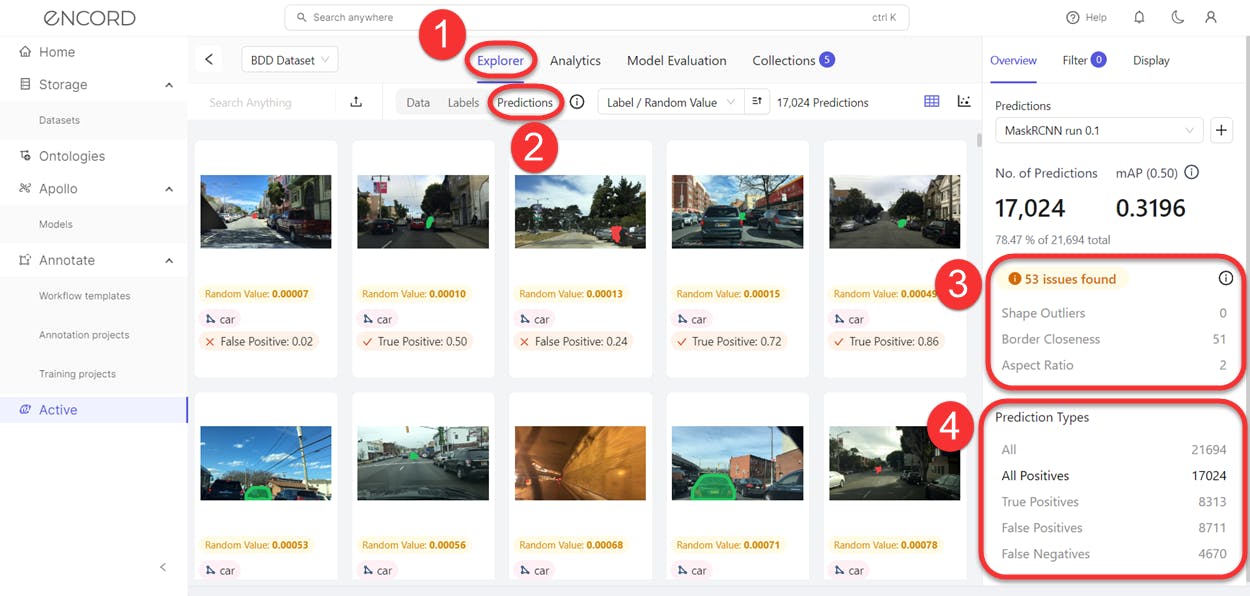
Prediction Issues and Types View in Encord Active
The final step here is to seek feedback from domain knowledge experts to confirm whether the model performance is robust, potentially guiding adjustments in features, model architecture, or problem framing.
Stage 5. Model Deployment
In the next stage, the trained model is prepared for model deployment. However, ensuring that the model size and latency meet the required criteria is crucial. Models can be compressed through techniques such as knowledge distillation or pruning without significantly impacting accuracy.
The choice of deployment environment depends on the use case and can vary from deployment in the cloud to deployment on the edge for devices such as a smartphone or a smart speaker. The final choice of the deployment platform is based on several factors, including computational resources, data privacy, latency requirements, and cost. You should also consider if the use case requires real-time or batch predictions so that the appropriate infrastructure for monitoring and logging is set up accordingly.
Before the model is put into production at scale, A/B testing is recommended to validate the model's performance and impact on the user experience. Implementing a phased rollout strategy can further mitigate risk, allowing for incremental adjustments based on real-world feedback and performance data. It is also important to remain cognizant of ethical and legal considerations, ensuring the model's deployment aligns with data protection regulations and ethical standards.
Stage 6. Model Monitoring and Maintenance
Once the model is deployed, you proceed to the final, but no less important, stage of model monitoring and maintenance. Continuous monitoring of the model performance metrics, the underlying hardware infrastructure, and the user experience is essential. Monitoring is an automated continuous process, all events are logged with alerting systems set up to flag and visualize any errors and anomalies.
Once a model is deployed, it may lose its performance over time, especially in case of data drift or model drift. In such scenarios, the model may need to be retrained to address the change in the data distribution.
Most machine learning models in production are continuously retrained regularly, either hourly, daily, weekly, or monthly. By capturing the latest real-world data in the updated training set, you can continuously improve the machine learning model and adapt its performance to the dynamic real-world data distributions.
Conclusion
Building machine learning models from scratch and taking them into production to provide a delightful customer experience is an arduous yet rewarding and commercially viable journey. However, building machine learning systems is not straightforward as they comprise multiple building blocks, including code, data, and models.
To create a significant business impact with machine learning, you have to fight the high odds of failures of commercial machine learning projects. You can maximize the likelihood of success by going through this process systematically with continuous iterations and feedback loops as you navigate the various stages of the ML lifecycle.
Frequently asked questions
Encord addresses workflow management by providing a comprehensive solution that integrates data curation and annotation into a single platform. This allows teams to manage their machine learning workflows more efficiently, ensuring that all data is tracked, organized, and easily accessible throughout the development process.
Encord's ML data ops platform focuses on the data curation and annotation processes within the machine learning model building lifecycle. While it does not source or provide datasets or perform model training, it excels in cleaning and curating data, ensuring high-quality collections of data for annotation workflows.
Yes, Encord not only aids in the annotation process but also provides tools that support the entire lifecycle of machine learning projects, from data labeling to the deployment of trained models. This holistic approach ensures that teams can efficiently transition from development to real-world application.
Encord provides a robust workflow management system that streamlines the process of data annotation and model training. Users can define specific workflows, track progress, and ensure compliance with project requirements, making it easier to manage complex machine learning initiatives.
Encord provides a user-friendly interface that integrates with existing machine learning workflows. The platform allows users to set parameters, pull datasets, and select features for optimal model performance, making it easier for teams to manage their training pipelines.
Encord streamlines the data pipeline by integrating various tools into a single platform, eliminating the need for manual data transfers and complex integrations. This approach saves time and resources, allowing teams to focus on building better-performing models at scale.
Encord provides a platform that integrates various stakeholders, tools, and workflows involved in the machine learning training data process. This collaborative approach streamlines communication and enhances the efficiency of data handling.
Encord enhances the annotation workflow by offering robust pipelines that streamline the process of labeling data. This allows teams to work collaboratively and efficiently, increasing the overall productivity of machine learning projects.
Yes, Encord can integrate with existing machine learning frameworks such as MLflow, enhancing users' ability to leverage their current setups while benefiting from Encord's advanced features for model evaluation and annotation.
Encord provides a comprehensive set of tools designed to manage the entire machine learning lifecycle, from data creation and annotation to model training and deployment, streamlining the process for users.