Meta AI's Segment Anything Model (SAM) Explained: The Ultimate Guide

Product Manager at Encord
 Breaking: Meta has recently released Segment Anything Model 2 (SAM 2) & SA-V Dataset.
Update: Segment Anything (SAM) is live in Encord! Check out our tutorial on How To Fine-Tune Segment Anything or book a demo with the team to learn how to use the Segment Anything Model (SAM) to reduce labeling costs.
Breaking: Meta has recently released Segment Anything Model 2 (SAM 2) & SA-V Dataset.
Update: Segment Anything (SAM) is live in Encord! Check out our tutorial on How To Fine-Tune Segment Anything or book a demo with the team to learn how to use the Segment Anything Model (SAM) to reduce labeling costs. If you thought the AI space was moving fast with tools like ChatGPT, GPT-4, and Stable Diffusion, then 2024 has truly shifted the game to a whole new level.
Meta’s FAIR lab broke ground with the Segment Anything Model (SAM), a state-of-the-art image segmentation model that has since become a cornerstone in computer vision. Released in 2023, SAM is based on foundation models that have significantly impacted natural language processing (NLP). It focuses on promptable segmentation tasks, using prompt engineering to adapt to diverse downstream segmentation problems.
Fast forward to December 2024, and SAM has inspired a wave of innovations across AI, from real-time video segmentation in augmented reality (AR) to integration with multimodal systems like OpenAI’s GPT-4 Vision and Anthropic’s multimodal Claude.
Whether you're working in design, healthcare, or robotics, SAM’s impact is still expanding.
In this blog post, you will:
- Learn how it compares to other foundation models.
- Learn about the Segment Anything (SA) project
- Dive into SAM's network architecture, design, and implementation.
- Learn how to implement and fine-tune SAM
- Discover potential uses of SAM for AI-assisted labeling.
Why Are We So Excited About SAM?
Having tested it out for a day now, we can see the following incredible advances:
- SAM can segment objects by simply clicking or interactively selecting points to include or exclude from the object. You can also create segmentations by drawing bounding boxes or segmenting regions with a polygon tool, and it will snap to the object.
- When encountering uncertainty in identifying the object to be segmented, SAM can produce multiple valid masks.
- SAM can identify and generate masks for all objects present in an image automatically.
- After precomputing the image embeddings, SAM can provide a segmentation mask for any prompt instantly for real-time interaction with the model.
Segment Anything Model Vs. Previous Foundation Models
SAM is a big step forward for AI because it builds on the foundations that were set by earlier models. SAM can take input prompts from other systems, such as, in the future, taking a user's gaze from an AR/VR headset to select an object, using the output masks for video editing, abstracting 2D objects into 3D models, and even popular Google Photos tasks like creating collages.
It can handle tricky situations by generating multiple valid masks where the prompt is unclear. Take, for instance, a user’s prompt for finding Waldo:

Image displaying semantic segmentations by the Segment Anything Model (SAM)
One of the reasons the results from SAM are groundbreaking is because of how good the segmentation masks are compared to other techniques like ViTDet. The illustration below shows a comparison of both techniques:

Segmentation masks by humans, ViTDet, and the Segment Anything Model (SAM)
What is the Segment Anything Model (SAM)?
SAM, as a vision foundation model, specializes in image segmentation, allowing it to accurately locate either specific objects or all objects within an image. SAM was purposefully designed to excel in promptable segmentation tasks, enabling it to produce accurate segmentation masks based on various prompts, including spatial or textual clues that identify specific objects.
Is Segment Anything Model Open Source?
The short answer is YES! The SA-1B Dataset has been released as open source for research purposes. In addition, Meta AI released the pre-trained models (~2.4 GB in size) and code under Apache 2.0 (a permissive license) following FAIR’s commitment to open research. It is freely accessible on GitHub. The training dataset is also available, alongside an interactive demo web UI.
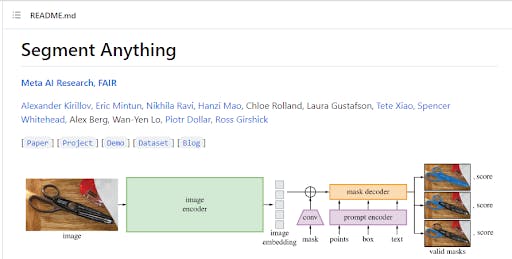
FAIR Segment Anything (SA) Paper
How does the Segment Anything Model (SAM) work?
SAM's architectural design allows it to adjust to new image distributions and tasks seamlessly, even without prior knowledge, a capability referred to as zero-shot transfer. Utilizing the extensive SA-1B dataset, comprising over 11 million meticulously curated images with more than 1 billion masks, SAM has demonstrated remarkable zero-shot performance, often surpassing previous fully supervised results.
Before we dive into SAM’s network design, let’s discuss the SA project, which led to the introduction of the very first vision foundation model.
Segment Anything Project Components
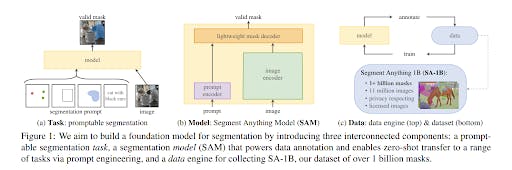
The Segment Anything (SA) project is a comprehensive framework for image segmentation featuring a task, model, and dataset.
The SA project starts with defining a promptable segmentation task with broad applicability, serving as a robust pretraining objective, and facilitating various downstream applications. This task necessitates a model capable of flexible prompting and the real-time generation of segmentation masks to enable interactive usage. Training the model effectively required a diverse, large-scale dataset.
The SA project implements a "data engine" approach to address the lack of web-scale data for segmentation. This involves iteratively using our efficient model to aid in data collection and utilizing the newly gathered data to enhance the model's performance.
Let’s look at the individual components of the SA project.
Segment Anything Task
The Segment Anything Task draws inspiration from natural language processing (NLP) techniques, particularly the next token prediction task, to develop a foundational model for segmentation. This task introduces the concept of promptable segmentation, wherein a prompt can contain various ,input forms such as foreground/background points, bounding boxes, masks, or free-form text, indicating what objects to segment in an image.
The objective of this task is to generate valid segmentation masks based on any given prompt, even in ambiguous scenarios. This approach enables a natural pre-training algorithm and facilitates zero-shot transfer to downstream segmentation tasks by engineering appropriate prompts.
Using prompts and composition techniques allows for extensible model usage across a wide range of applications, distinguishing it from interactive segmentation models designed primarily for human interaction.
Dive into SAM's Network Architecture and Design
SAM’s design hinges on three main components:
- The promptable segmentation task to enable zero-shot generalization.
- The model architecture.
- The dataset that powers the task and model.
Leveraging concepts from Transformer vision models, SAM prioritizes real-time performance while maintaining scalability and powerful pretraining methods.
Scroll down to learn more about SAM’s network design.
Foundation model architecture for the Segment Anything (SA) model
Task
SAM was trained on millions of images and over a billion masks to return a valid segmentation mask for any prompt. In this case, the prompt is the segmentation task and can be foreground/background points, a rough box or mask, clicks, text, or, in general, any information indicating what to segment in an image. The task is also used as the pre-training objective for the model.
Model
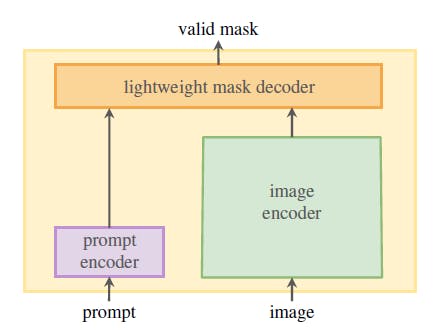
SAM’s architecture comprises three components that work together to return a valid segmentation mask:
- An image encoder to generate one-time image embeddings.
- A prompt encoder that embeds the prompts.
- A lightweight mask decoder that combines the embeddings from the prompt and image encoders.
Components of the Segment Anything (SA) model
We will dive into the architecture in the next section, but for now, let’s take a look at the data engine.
Segment Anything Data Engine
The Segment Anything Data Engine was developed to address the scarcity of segmentation masks on the internet and facilitate the creation of the extensive SA-1B dataset containing over 1.1 billion masks. A data engine is needed to power the tasks and improve the dataset and model.
The data engine has three stages:
- Model-assisted manual annotation, where professional annotators use a browser-based interactive segmentation tool powered by SAM to label masks with foreground/background points. As the model improves, the annotation process becomes more efficient, with the average time per mask decreasing significantly.
- Semi-automatic, where SAM can automatically generate masks for a subset of objects by prompting it with likely object locations, and annotators focus on annotating the remaining objects, helping increase mask diversity. The focus shifts to increasing mask diversity by detecting confident masks and asking annotators to annotate additional objects. This stage contributes significantly to the dataset, enhancing the model's segmentation capabilities.
- Fully automatic, where human annotators prompt SAM with a regular grid of foreground points, yielding on average 100 high-quality masks per image. The annotation becomes fully automated, leveraging model enhancements and techniques like ambiguity-aware predictions and non-maximal suppression to generate high-quality masks at scale.
This approach enables the creation of the SA-1B dataset, consisting of 1.1 billion high-quality masks derived from 11 million images, paving the way for advanced research in computer vision.
Segment Anything 1-Billion Mask Dataset
The Segment Anything 1 Billion Mask (SA-1B) dataset is the largest labeled segmentation dataset to date. It is specifically designed for the development and evaluation of advanced segmentation models.
We think the dataset will be an important part of training and fine-tuning future general-purpose models. This would allow them to achieve remarkable performance across diverse segmentation tasks. For now, the dataset is only available under a permissive license for research.
The SA-1B dataset is unique due to its:
- Diversity
- Size
- High-quality annotations
Diversity
The dataset is carefully curated to cover a wide range of domains, objects, and scenarios, ensuring that the model can generalize well to different tasks. It includes images from various sources, such as natural scenes, urban environments, medical imagery, satellite images, and more.
This diversity helps the model learn to segment objects and scenes with varying complexity, scale, and context.
Distribution of images and masks for training Segment Anything (SA) model
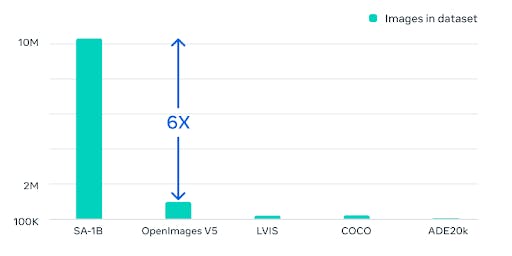
Size
The SA-1B dataset, which contains over a billion high-quality annotated images, provides ample training data for the model. The sheer volume of data helps the model learn complex patterns and representations, enabling it to achieve state-of-the-art performance on different segmentation tasks.
Relative size of SA-1B to train the Segment Anything (SA) model
High-Quality Annotations
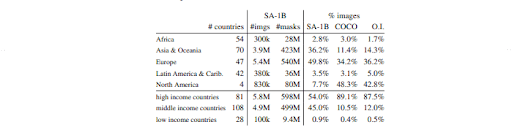
The dataset has been carefully annotated with high-quality masks, leading to more accurate and detailed segmentation results. In the Responsible AI (RAI) analysis of the SA-1B dataset, potential fairness concerns and biases in geographic and income distribution were investigated.
The research paper showed that SA-1B has a substantially higher percentage of images from Europe, Asia, and Oceania, as well as middle-income countries, compared to other open-source datasets. It's important to note that the SA-1B dataset features at least 28 million masks for all regions, including Africa. This is 10 times more than any previous dataset's total number of masks.

Distribution of the images to train the Segment Anything (SA) model
At Encord, we think the SA-1B dataset will enter the computer vision hall of fame (together with famous datasets such as COCO, ImageNet, and MNIST) as a resource for developing future computer vision segmentation models.
Notably, the dataset includes downscaled images to mitigate accessibility and storage challenges while maintaining significantly higher resolution than many existing vision datasets.
The quality of the segmentation masks is rigorously evaluated, with automatic masks deemed high quality and effective for training models, leading to the decision to include automatically generated masks exclusively in SA-1B.
Let's delve into the SAM's network architecture, as it's truly fascinating.
Segment Anything Model's Network Architecture
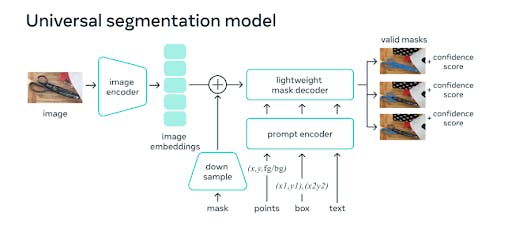
The Segment Anything Model (SAM) network architecture contains three crucial components: the Image Encoder, the Prompt Encoder, and the Mask Decoder.
Architecture of the Segment Anything (SA) universal segmentation model
Image Encoder
At the highest level, an image encoder (a masked auto-encoder, MAE, pre-trained Vision Transformer, ViT) generates one-time image embeddings. It is applied before prompting the model. The image encoder, based on a masked autoencoder (MAE) pre-trained Vision Transformer (ViT), processes high-resolution inputs efficiently. This encoder runs once per image and can be applied before prompting the model for seamless integration into the segmentation process.
Prompt Encoder
The prompt encoder encodes background points, masks, bounding boxes, or texts into an embedding vector in real-time. The research considers two sets of prompts: sparse (points, boxes, text) and dense (masks).
Points and boxes are represented by positional encodings and added with learned embeddings for each prompt type. Free-form text prompts are represented with an off-the-shelf text encoder from CLIP. Dense prompts, like masks, are embedded with convolutions and summed element-wise with the image embedding.
The prompt encoder manages both sparse and dense prompts. Dense prompts, like masks, are embedded using convolutions and then summed element-wise with the image embedding. Sparse prompts, representing points, boxes, and text, are encoded using positional embeddings for each prompt type. Free-form text is handled with a pre-existing text encoder from CLIP. This approach ensures that SAM can effectively interpret various types of prompts, enhancing its adaptability.
Mask Decoder
A lightweight mask decoder predicts the segmentation masks based on the embeddings from both the image and prompt encoders. The mask decoder efficiently maps the image and prompt embeddings to generate segmentation masks. It maps the image embedding, prompt embeddings, and an output token to a mask.
SAM uses a modified decoder block and then a dynamic mask prediction head, taking inspiration from already existing Transformer decoder blocks. This design incorporates prompt self-attention and cross-attention mechanisms to update all embeddings effectively. All of the embeddings are updated by the decoder block, which uses prompt self-attention and cross-attention in two directions (from prompt to image embedding and back).
SAM's Mask Decoder is optimized for real-time performance, enabling seamless interactive prompting of the model. The masks are annotated and used to update the model weights. This layout enhances the dataset and allows the model to learn and improve over time, making it efficient and flexible.
SAM's overall design prioritizes efficiency, with the prompt encoder and mask decoder running seamlessly in web browsers in approximately 50 milliseconds, enabling real-time interactive prompting.
How to Use the Segment Anything Model?
At Encord, we see the Segment Anything Model (SAM) as a game changer in AI-assisted labeling. It basically eliminates the need to go through the pain of segmenting images with polygon drawing tools and allows you to focus on the data tasks that are more important for your model.
These other data tasks include mapping the relationships between different objects, giving them attributes that describe how they act, and evaluating the training data to ensure it is balanced, diverse, and bias-free.
Enhancing Manual Labeling with AI
SAM can be used to create AI-assisted workflow enhancements and boost productivity for annotators. Here are just a few improvements we think SAM can contribute:
- Improved accuracy: Annotators can achieve more precise and accurate labels, reducing errors and improving the overall quality of the annotated data.
- Faster annotation: There is no doubt that SAM will speed up the labeling process, enabling annotators to complete tasks more quickly and efficiently when combined with a suitable image annotation tool.
- Consistency: Having all annotators use a version of SAM would ensure consistency across annotations, which is particularly important when multiple annotators are working on the same project.
- Reduced workload: By automating the segmentation of complex and intricate structures, SAM significantly reduces the manual workload for annotators, allowing them to focus on more challenging and intricate tasks.
- Continuous learning: As annotators refine and correct SAM's assisted labeling, we could implement it such that the model continually learns and improves, leading to better performance over time and further streamlining the annotation process.
As such, integrating SAM into the annotation workflow is a no-brainer from our side, and it would allow our current and future customers to accelerate the development of cutting-edge computer vision applications.
AI-Assisted Labeling with Segment Anything Model on Encord
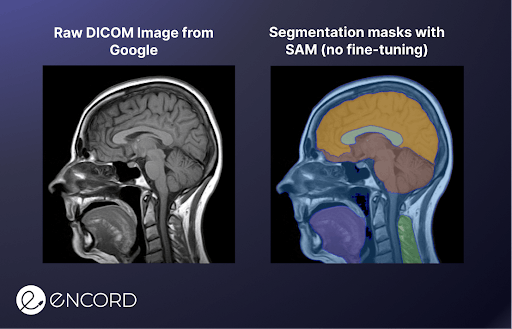
Consider the medical image example from before to give an example of how SAM can contribute to AI-assisted labeling. We uploaded the DICOM image to the demo web UI, and spent 10 seconds clicking the image to segment the different areas of interest.
Afterward, we did the same exercise with manual labeling using polygon annotations, which took 2.5 minutes. A 15x improvement in the labeling speed!
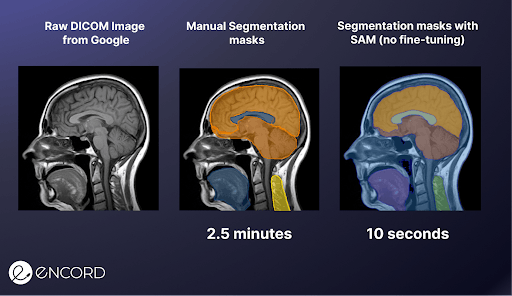
Combining SAM with Encord Annotate harnesses SAM's versatility in segmenting diverse content alongside Encord's robust ontologies, interactive editing capabilities, and extensive media compatibility. Encord seamlessly integrates SAM for annotating images, videos, and specialized data types like satellite imagery and DICOM files. This includes support for various medical imaging formats, such as X-ray, CT, and MRI, requiring no extra input from the user.
How to Fine-Tune Segment Anything Model (SAM)
To fine-tune the SAM model effectively, particularly considering its intricate architecture, a pragmatic strategy involves refining the mask decoder. Unlike the image encoder, which boasts a complex architecture with numerous parameters, the mask decoder offers a streamlined and lightweight design. This characteristic makes it inherently easier, faster, and more memory-efficient to fine-tune.
Users can expedite the fine-tuning process while conserving computational resources by prioritizing adjustments to the mask decoder. This focused approach ensures efficient adaptation of SAM to specific tasks or datasets, optimizing its performance for diverse applications.
The steps include:
- Create a custom dataset by extracting the bounding box coordinates (prompts for the model) and the ground truth segmentation masks.
- Prepare for fine-tuning by converting the input images to PyTorch tensors, a format SAM's internal functions expect.
- Run the fine-tuning step by instantiating a training loop that uses the lightweight mask decoder to iterate over the data items, generate masks, and compare them to your ground truth masks. The mask decoder is easier, faster, and more memory-efficient to fine-tune.
- Compare your tuned model to the original model to make sure there’s indeed a significant improvement.
Real-World Use Cases and Applications
SAM can be used in almost every single segmentation task, from instance to panoptic. We’re excited about how quickly SAM can help you pre-label objects with almost pixel-perfect segmentation masks before your expert reviewer adds the ontology on top.
From agriculture and retail to medical imagery and geospatial imagery, the AI-assisted labeling that SAM can achieve is endless. It will be hard to imagine a world where SAM is not a default feature in all major annotation tools. This is why we at Encord are very excited about this new technology.
Find other applications that could leverage SAM below.
Image and Video Editors
SAM’s outstanding ability to provide accurate segmentation masks for even the most complex videos and images can provide image and video editing applications with automatic object segmentation skills. Whether the prompts (point coordinates, bounding boxes, etc.) are in the foreground or background, SAM uses positional encodings to indicate if the prompt is in the foreground or background.
Generating Synthetic Datasets for Low-resource Industries
One challenge that has plagued computer vision applications in industries like manufacturing is the lack of datasets. For example, industries building car parts and planning to detect defects in the parts along the production line cannot afford to gather large datasets for that use case.
You can use SAM to generate synthetic datasets for your applications. If you realize SAM does not work particularly well for your applications, an option is to fine-tune it on existing datasets.
Gaze-based Segmentation
AR applications can use SAM’s Zero-Shot Single Point Valid Mask Evaluation technique to segment objects through devices like AR glasses based on where subjects gaze. This can help AR technologies give users a more realistic sense of the world as they interact with those objects.
Medical Image Segmentation
SAM's application in medical image segmentation addresses the demand for accurate and efficient ROI delineation in various medical images. While manual segmentation is accurate, it's time-consuming and labor-intensive. SAM alleviates these challenges by providing semi- or fully automatic segmentation methods, reducing time and labor, and ensuring consistency.
With the adaptation of SAM to medical imaging, MedSAM emerges as the first foundation model for universal medical image segmentation. MedSAM leverages SAM's underlying architecture and training process, providing heightened versatility and potentially more consistent results across different tasks.
The MedSAM model consistently does better than the best segmentation foundation models when tested on a wide range of internal and external validation tasks that include different body structures, pathological conditions, and imaging modalities.
This underscores MedSAM's potential as a powerful tool for medical image segmentation, offering superior performance compared to specialist models and addressing the critical need for universal models in this domain.
Where Does This Leave Us?
The Segment Anything Model (SAM) truly represents a groundbreaking development in computer vision. By leveraging promptable segmentation tasks, SAM can adapt to a wide variety of downstream segmentation problems using prompt engineering.
This innovative approach, combined with the largest labeled segmentation dataset to date (SA-1B), allows SAM to achieve state-of-the-art performance in various segmentation tasks.
With the potential to significantly enhance AI-assisted labeling and reduce manual labor in image segmentation tasks, SAM can pave the way in industries such as agriculture, retail, medical imagery, and geospatial imagery.
At Encord, we recognize the immense potential of SAM, and we are soon bringing the model to the Encord Platform to support AI-assisted labeling, further streamlining the data annotation process for users.
As an open-source model, SAM will inspire further research and development in computer vision, encouraging the AI community to push the boundaries of what is possible in this rapidly evolving field.
Ultimately, SAM marks a new chapter in the story of computer vision, demonstrating the power of foundation models in transforming how we perceive and understand the world around us.
A Brief History of Meta's AI & Computer Vision
As one of the leading companies in the field of artificial intelligence (AI), Meta has been pushing the boundaries of what's possible with machine learning models: from recently released open source models such as LLaMA to developing the most used Python library for ML and AI, PyTorch.
Advances in Computer Vision
Computer vision has also experienced considerable advancements, with models like CLIP bridging the gap between text and image understanding.
These models use contrastive learning to map text and image data. This allows them to generalize to new visual concepts and data distributions through prompt engineering.
FAIR’s Segment Anything Model (SAM) is the latest breakthrough in this field. Their goal was to create a foundation model for image segmentation that can adapt to various downstream tasks using prompt engineering.
The release of SAM started a wave of vision foundation models and vision language models like LLaVA, GPT-4 vision, Gemini, and many more.
Let’s briefly explore some key developments in computer vision that have contributed to the growth of AI systems like Meta's.
Convolutional Neural Networks (CNNs)
CNNs, first introduced by Yann LeCun (now VP & Chief AI Scientist at Meta) in 1989, have emerged as the backbone of modern computer vision systems, enabling machines to learn and recognize complex patterns in images automatically.
By employing convolutional layers, CNNs can capture local and global features in images, allowing them to recognize objects, scenes, and actions effectively. This has significantly improved tasks such as image classification, object detection, and semantic segmentation.
Generative Adversarial Networks (GANs)
GANs are a type of deep learning model that Ian Goodfellow and his team came up with in 2014. They are made up of two neural networks, a generator, and a discriminator, competing.
The generator aims to create realistic outputs, while the discriminator tries to distinguish between real and generated outputs. The competition between these networks has resulted in the creation of increasingly realistic synthetic images. It has led to advances in tasks such as image synthesis, data augmentation, and style transfer.
Transfer Learning and Pre-trained Models
Like NLP, computer vision has benefited from the development of pre-trained models that can be fine-tuned for specific tasks. Models such as ResNet, VGG, and EfficientNet have been trained on large-scale image datasets, allowing researchers to use these models as a starting point for their own projects.
The Growth of Foundation Models
Foundation models in natural language processing (NLP) have made significant strides in recent years, with models like Meta’s own LLaMA or OpenAI’s GPT-4 demonstrating remarkable capabilities in zero-shot and few-shot learning.
These models are pre-trained on vast amounts of data and can generalize to new tasks and data distributions by using prompt engineering. Meta AI has been instrumental in advancing this field, fostering research and the development of large-scale NLP models that have a wide range of applications.
Here, we explore the factors contributing to the growth of foundation models.
Large-scale Language Models
The advent of large-scale language models like GPT-4 has been a driving force behind the development of foundation models in NLP. These models employ deep learning architectures with billions of parameters to capture complex patterns and structures in the training data.
Transfer Learning
A key feature of foundation models in NLP is their capacity for transfer learning. Once trained on a large corpus of data, they can be fine-tuned on smaller, task-specific datasets to achieve state-of-the-art performance across a variety of tasks.
Zero-shot and Few-shot Learning
Foundation models have also shown promise in zero-shot and few-shot learning, where they can perform tasks without fine-tuning or with minimal task-specific training data. This capability is largely attributed to the models' ability to understand and generate human-like responses based on the context provided by prompts.
Multi-modal Learning
Another growing area of interest is multi-modal learning, where foundation models are trained to understand and generate content across different modalities, such as text and images.
Models like Gemini, GPT-4V, LLaVA, CLIP, and ALIGN show how NLP and computer vision could be used together to make multi-modal models that can translate actions from one domain to another.
Ethical Considerations and Safety
The growth of foundation models in NLP has also raised concerns about their ethical implications and safety. Researchers are actively exploring ways to mitigate potential biases, address content generation concerns, and develop safe and controllable AI systems. Proof of this was the recent call for a six-month halt on all development of cutting-edge models.

Frequently Asked Questions on Segment Anything Model (SAM)
How do I fine-tune SAM for my tasks?
We have provided a step-by-step walkthrough you can follow to fine-tune SAM for your tasks. Check out the tutorial: How To Fine-Tune Segment Anything.
What datasets were used to train SAM?
The Segment Anything 1 Billion Mask (SA-1B) dataset has been touted as the “ImageNet of segmentation tasks.” The images vary across subject matter. Scenes, objects, and places frequently appear throughout the dataset. Masks range from large-scale objects such as buildings to fine-grained details like door handles.
See the data card and dataset viewer to learn more about the composition of the dataset.
Does SAM work well for all tasks?
Yes. You can automatically select individual items from images—it works very well on complex images. SAM is a foundation model that provides multi-task capabilities to any application you plug it into.
Does SAM work well for ambiguous images?
Yes, it does. Because of this, you might find duplicates in your mask sets when you run SAM over your dataset. This allows you to select the most appropriate masks for your task. In this case, you should add a post-processing step to segment the most suitable masks for your task.
How long does it take SAM to generate segmentation masks?
SAM can generate a segment in as little as 50 milliseconds—practically real-time!
Do I need a GPU to run SAM?
Although it is possible to run SAM on your CPU, you can use a GPU to achieve significantly faster results from SAM.
Frequently asked questions
The Segment Anything Model (SAM) is a state-of-the-art image segmentation model released by Meta AI. SAM is based on foundation models and focuses on promptable segmentation tasks.
SAM’s design hinges on three main components: the promptable segmentation task, model architecture, and the dataset that powers the task and model.
Yes, Fundamental AI Research or FAIR at Meta has released the Segment Anything paper. All other resources are also available on the project page:
https://segment-anything.com/Yes, SAM is designed to support zero-shot prediction, allowing it to generate valid segmentation masks even for tasks it hasn't been explicitly trained on.
As of now Meta has not released any API for Segment Anything.
Yes, the model is licensed under the Apache 2.0 license, which allows for free commercial use, subject to the terms and conditions outlined in the license agreement.
There is a Segment Anything demo available but only for research purposes and not for commercial purposes.
The Segment Anything model can be adapted for object detection tasks by using prompts or inputs that specify the objects to be detected within an image. These prompts can include spatial or textual clues identifying the objects of interest.
Segmentation models focus on identifying and delineating specific regions or objects within an image, providing pixel-level accuracy. Object detection models, on the other hand, aim to identify and locate objects within an image while also providing information about their bounding boxes and classifications.
SAM's primary objective is to serve as a vision foundation model for image segmentation tasks, capable of generating valid segmentation masks from any given prompt or input.
SAM was trained using a large dataset consisting of more than 1 billion images, enabling it to learn diverse patterns and features for accurate segmentation.
Yes, the Segment Anything model, also known as SAM, is considered a foundation model designed to provide a broad and versatile framework for various segmentation tasks.
Encord ensures compliance with customer contracts regarding data usage. Depending on the agreement, customer data may be used to enrich models but can be restricted from being mixed with generic models. This approach allows us to maintain data integrity while providing tailored solutions.
Workflow schemas in the Encord annotation platform are essential for managing the flow of tasks within an annotation project. They help in organizing the raw data, defining the ontology or schema, and ensuring that tasks are executed efficiently throughout the annotation process.
Encord supports users in identifying and annotating edge cases that may not be obvious by combining various data sampling techniques and providing insights into potential blind spots in the model. This proactive approach helps improve overall model accuracy and reliability.