3 Ways To Add More Classes To Computer Vision Models

When developing a computer vision model, it is trained on visual data like images and video. However, these images need to be assigned to relevant classes in order for the model to accurately learn from the data. Assigning these classes, or categories, is called classification.
Adding new classes to a production computer vision model may be necessary for several reasons:
- Improved accuracy
- Increased versatility
- Increased robustness
When adding new classes, it is important to have enough high-quality data, use robust evaluation methods, and monitor the model's performance over time to ensure its continued effectiveness.
Adding new classes to a computer vision model can improve accuracy, increased versatility, and the ability to handle a wider range of inputs, but only when it is done well.
In this article, you will learn three easy ways to add more classes to improve the performance of your computer vision (CV) model.

How do I know if I need to add new classes to my computer vision model?
When developing a computer vision model and putting it into production, it is essential to continually benchmark its performance and consider adding new classes where performance is lacking. Several signs may indicate the need for adding new classes, including:
- Decreased accuracy on new data
- Changes in business requirements
- Changes in the environment
- Insufficient data for existing classes
- Overfitting
Decreased accuracy on new data
If you observe a drop in accuracy when applying your model to new data, it may be because the model has not encountered examples of the new classes present in the data or there are some errors in your dataset that you need to fix.
You can add these classes to your training set and retrain your model to improve accuracy. To easily find such classes, you can use Encord Index to search and curate them with your training data.

Encord Index uses embeddings to cluster similar images based on their properties and features, so it's easy to find and add new or imbalanced classes to your training data.
Changes in business requirements
As business needs evolve, adding new classes to your model may be necessary to account for the new objects or scenes that are now relevant to your application.
For example, if you previously developed a model to recognize objects in a warehouse but now need to extend it to recognize objects in a retail store, you may need to add new classes to account for the different types of products and displays.
Changes in the environment
Changes in the environment in which your model is being used can also impact its performance.
For example, if the lighting conditions have changed or there is a new background in the real-world images the detection model is analyzing, it may be necessary to add new classes to account for these changes.
Insufficient data for existing classes
If the data you have collected for your existing classes is insufficient to train a high-quality model, adding new classes can help improve overall performance. This is because the model will have access to more data from which to learn.

Overfitting
Overfitting occurs when a model memorizes specific examples in the training data instead of learning general patterns. If you suspect your model is overfitting, it may be because you have not provided enough training data variability. In this case, adding new classes can help reduce overfitting by providing more diverse examples for the model to learn from.
Quality and Quantity of Data
It is important to consider the quality and quantity of data when adding new classes. A good rule of thumb is to have at least 100-1000 examples per class, but the number may vary depending on the complexity of the classes and the size of your model. The data should also be diverse and representative of the real-world scenarios in which the model will be used.
To evaluate the effectiveness of the model with the added classes, it is important to use robust evaluation methods such as cross-validation. This will provide a reliable estimate of the model's performance on unseen data and help to ensure that it is not overfitting to the new data.
Additionally, it is important to monitor the performance of your model over time and to be proactive in adding new classes if needed. Regular evaluation and monitoring can help you quickly identify when new classes are needed and ensure that your model remains up-to-date and effective.
What are the Benefits of Adding New Classes to a Computer Vision Model?
Adding new classes to a computer vision model can have several benefits, including:
- Improved accuracy
- Increased versatility
- The ability to handle a wider range of inputs.
Improved Accuracy
One of the main benefits of adding new classes to a computer vision model is improved accuracy. Adding new classes allows the model to recognize a wider range of objects, scenes, and patterns, leading to better performance in real-world applications, such as facial recognition or self-driving cars.
This can be particularly important for tasks like image classification, object detection, and semantic segmentation, where the goal is to accurately identify and classify the elements in an image or video.
With a larger number of classes, the model can learn to distinguish between similar objects, such as different breeds of dogs or species of flowers, and better generalize to unseen examples.
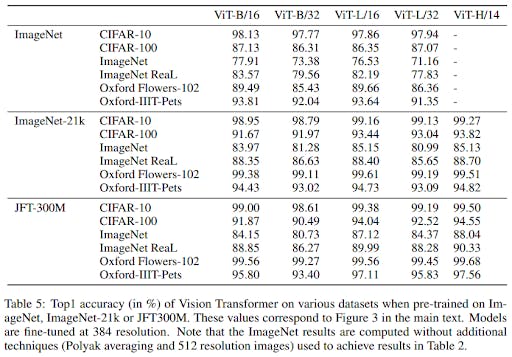
Results from the paper "an image is worth 16x16 words: transformers for image recognition at scale" show that by using more data (the JFT-300M dataset has ~375 million annotated images) you can significantly improve the model's performance.
Increased Versatility
Another benefit of adding new classes is increased versatility. The model can be applied to a wider range of use cases and problems by expanding the range of objects and scenes.
For example, a model trained on a large image dataset of natural images can be adapted to a specific domain, such as medical imaging, by adding relevant classes. This can help the model perform well in more specialized applications, such as disease diagnosis or surgical planning.
Increased Robustness
Adding new classes can also help the model handle a wider range of inputs. For example, a model trained on diverse images can be more robust to variations in lighting, viewpoint, and other factors that can affect image quality.
This can be especially important for real-world applications, where the images used to test the artificial intelligence model may differ from those used during training.
How To Add New Classes To Your Computer Vision Model
Adding new classes to a computer vision model is crucial in improving its accuracy and functionality.
Several steps are involved in this process, including data collection, model training, debugging, and deployment. Various tools and software libraries have been developed to make this task easier.
There are three main ways to prepare a new class for your computer vision model:
- Manual collection and annotation
- Generating synthetic data
- Active learning
Let’s take a look at them one by one.
Manual Dataset Collection and Annotation
Annotation refers to identifying and labeling specific regions in video or image data. This technique is mainly used for image classification through supervised learning. The annotated data serves as the input for training machine learning or deep learning models.
With many annotations and diverse image variations, the model can identify the unique characteristics of the images and videos and learn to perform tasks such as object detection or object tracking, image classification, and others, depending on the model being trained.

There are various types of annotations, including 2D bounding boxes, instance segmentation, 3D cuboid boxes, and keypoint annotations.
- Instance segmentation involves identifying and outlining multiple objects in an image.
- Bounding boxes, or 3D cuboid boxes, can be drawn around objects and assigned labels for object detection.
- Polygonal outlines can be traced around objects for semantic and instance segmentation.
- Keypoints and landmarks can also be identified and labeled for object landmark detection, and straight lines can be marked for lane detection.
- For image classification, images are grouped based on labels.
To prepare and annotate your own dataset, you can either record videos, take photos, or search for freely available open-source datasets online. If your company already has a dataset, you can connect it to a platform via cloud bucket integration (S3, Azure, GCP, etc.).
However, before using these images for training, you must annotate them instead of using data from an already annotated dataset.
When collecting data, keep it as close to your intended inference environment as possible, considering all aspects of the input images, including lighting, angle, objects, etc.
For example, you must consider different light and weather conditions to build machine learning models that detect license plates.

There are many tools available for annotating images for computer vision datasets. Each tool has its own features and is designed for a specific type of project.
- Encord Annotate: An annotation platform for AI-assisted image and video annotation and dataset management. It's the best option for teams using AI automation to make the video and image annotation processes more efficient.
- CVAT (Computer VisionAnnotation Tool): A free, open-source, web-based annotation toolkit built by Intel. CVAT supports four types of annotations (points, polygons, bounding boxes, and polylines).
- Labelbox: A data annotation platform.
- Appen: A data labeling tool founded in 1996, making it one of the first and oldest solutions in the market.
These are just a few tools for adding new classes to a computer vision dataset.
The best tool for you will depend on the specific needs of your project, such as:
- The size of your dataset.
- The types of annotations you need to make.
- The platform you are using.
Ideally, the annotation tool should seamlessly integrate into your ML workflow. It should be efficient, user-friendly, and allow for quick and accurate annotation, enabling you to focus on training your models and improving their performance.
The tool should also have the necessary functionalities and features to meet your specific annotation requirements, making annotating data smoother and more efficient.

Synthetic Datasets
Another way to create a dataset is to generate synthetic data. This method can be especially useful for training in unusual circumstances, as it allows you to create a much larger dataset than you could otherwise obtain from real-world sources.
As a result, your model is likely to perform better and achieve better results. However, using only synthetic data or putting synthetic data into validation/test data is not recommended.

Generating synthetic computer vision datasets is another option for adding new classes to your model. There are several tools available for this purpose:
- Unity3D/Unreal Engine: Popular game engines that can generate synthetic computer visiondatasets by creating virtual environments and simulating camera movements.
- Blender: A free and open-source 3D creation software that can generate synthetic computer visiondatasets by creating 3D models and rendering them as images.
- AirSim: an open-source, cross-platform simulation environment for autonomous systems and robotics, developed by Microsoft. It uses Unreal Engine for physically and visually realistic simulations and allows for testing and developing autonomous systems such as drones, ground vehicles, and robotic systems.
- CARLA: an open-source, autonomous driving simulator. It provides a platform for researchers and developers to test and validate their autonomous vehicle algorithms in a simulated environment. CARLA simulates various real-world conditions, such as weather, traffic, and road layouts, allowing users to test their algorithms in various scenarios. It also provides several pre-built maps, vehicles, sensors, and an API for creating custom components.
- Generative adversarial networks (GANs) allow you to generate synthetic data by setting two neural networks to compete against each other. One generates the data and the other identifies whether it's real or synthetic. Through iteration, the models adjust their parameters to improve their performance, with the discriminator becoming better at distinguishing real from synthetic data and the generator becoming more effective at creating accurate synthetic data. GANs can be used to supplement training datasets that lack sufficient real-world data, but there are also challenges to using synthetic data that need to be considered.
These tools can be used to generate synthetic data for various computer vision tasks, such as object detection, segmentation, and scene understanding. The choice of tool will depend on the specific requirements of your project, such as the type of data you need to generate, the complexity of the scene, and the resources available.
Annotation with Active Learning
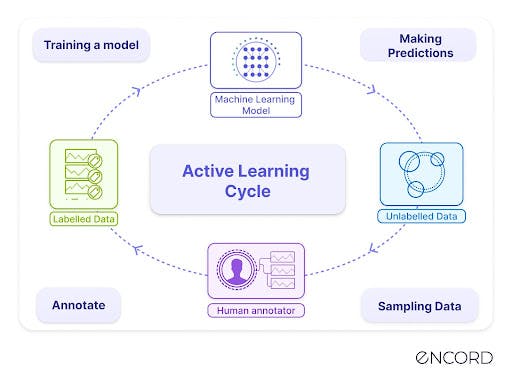
Active learning is a machine learning technique that trains models by allowing them to actively query annotators for information that will help improve their performance. The process starts with a small subset of labeled data from a large dataset. The model uses this labeled data to predict the remaining unlabeled data. ML engineers and data scientists then evaluate the model's predictions to determine its level of certainty.
A common method for determining uncertainty is looking at the entropy of the probability distribution of the prediction. For example, in image classification, the model reports a confidence probability for each class considered for each prediction made.
If the model is highly confident in its prediction, such as a 99 percent probability that an image is a motorcycle, then it has a high level of certainty.
If the model has low certainty in its prediction, such as a 55 percent probability that an image is a truck, then the model needs to be trained on more labeled images of trucks.
Another example is the classification of images of animals. After the model is initially trained on a subset of labeled data, it can identify cats with high certainty but is uncertain about how to identify a dog, reporting a 51 percent probability that it is not a cat and a 49 percent probability that it is a cat. In this case, the model needs to be fed more labeled images of dogs so that the ML engineers can retrain the model and improve its performance.
The samples with high uncertainty are sent back to the annotators, who label them and provide the newly labeled data to the ML engineers. The engineers then use this data to retrain the model, and the process continues until the model reaches an acceptable performance threshold. This loop of training, testing, identifying uncertainty, annotating, and retraining allows the model to improve its performance continually.
Active learning pipelines also help ML engineers identify failure modes such as edge cases, where the model predicts with high uncertainty, indicating that the data does not fit into one of the categories the model has been designed to detect.
The model flags these outliers, and the ML engineers can retrain the model with the labeled sample to help the model learn to identify these edge cases.
Using active learning in machine learning can make model training faster and cheaper while reducing the burden of data labeling for annotators.
Instead of labeling all the data in a massive dataset, organizations can intelligently select and label a portion to increase model performance and reduce costs.
With an AL pipeline, ML teams can prioritize labeling the most useful data for training the model and continuously adjust their training as new data is annotated and used for training.
Surprisingly, active learning is also useful even when ML engineers have a large amount of already labeled data.
Training the model on every piece of labeled data in a dataset can be a poor allocation of resources, and active learning can help select a subset of data that is most useful for training the model, reducing computational costs.
Active learning is a powerful ML technique that allows models to actively seek information that will help improve their performance.
By reducing the burden of data labeling and optimizing the use of computational resources, active learning can help organizations achieve better results more efficiently and cost-effectively. However, an active learning pipeline can be hard to implement.
Encord Index is a data management and curation tool that includes visualizations, workflows, and data sets. It labels quality metrics and performs model performance analysis based on the model's predictions.
It allows you to add the model's predictions, filter them by the model's confidence, and export them into your annotation tool (for example, Encord Annotate).

What Do You Do Once You’ve Added New Classes?
Once you’ve added new classes to your computer vision model, there are several steps you can take to optimize its performance:
- Evaluate the model
- Fine-tune the model
- Data augmentation
- Monitor performance
Evaluate The Model
After adding new classes to your model, the first step is to evaluate its performance. This involves using a dataset of images or videos to test the model and see how well it can recognize the new classes.
You can use metrics like accuracy, precision, recall, and F1 score to quantify and compare the model's performance with baseline models. You can also visualize the results and check model performance using confusion matrices, precision-recall, and ROC curves.
These evaluations will help you identify areas where the model performs well and needs improvement.

Fine-Tune the Model
Based on the evaluation results, you may need to fine-tune the model to optimize its performance for the new classes. Fine-tuning can involve adjusting the model's hyperparameters, such as learning rate, weight decay, or architecture.
You can also use techniques like transfer learning to leverage pre-trained models and fine-tune them for your specific task.
Data Augmentation
Another approach to improving the model's performance is to use data augmentation. This involves transforming the existing training data to create new, synthetic examples.
For example, you can use techniques like random cropping, flipping, or rotation to create new training samples. By increasing the size of the training dataset, data augmentation can help prevent overfitting and improve the model's generalization ability.
Monitor Performance
Once you’ve fine-tuned the model, monitoring its performance over time is important. This can involve tracking the model's behavior on a test set or in a real-world deployment and adjusting the model as needed to keep it up-to-date.
Monitoring performance can help ensure the model continues functioning well when new classes are added and the underlying data distribution changes.
Adding new classes to a computer vision model is the first step in optimizing its performance. By evaluating the model, fine-tuning its parameters, using data augmentation and regularization, and monitoring its performance, you can make the model more accurate, versatile, and robust to new classes.
These steps are crucial for ensuring that your model remains effective and up-to-date over time and for achieving the best possible performance in real-world applications.
Adding Classes To Computer Vision Models: Summary of Steps
Step 1: Assess the Need for New Classes
- Benchmark the model’s performance
- Check for business or environmental changes
- Evaluate data sufficiency
Step 2: Curate High-Quality Data
- Collect data relevant to your application and use open-source datasets if available
- Annotate data using tools like Encord Annotate
- Maintain diversity by gathering 100–1000 examples per class
Step 3: Generate Additional Data (Optional)
- Use synthetic data generated with tools like Unity3D, Unreal Engine, or Blender.
- Leverage GANs to generate realistic data and address dataset imbalances or rare scenarios
Step 4: Optimize Data Collection with Active Learning
- Train an initial model with a small, labeled dataset and use the model to predict on unlabeled data.
- Identify high-uncertainty samples
- Iterate by annotating high-uncertainty samples and retraining the model
Step 5: Train and Fine-Tune the Model
- Combine old and new class data to prevent bias toward recently added classes and use transfer learning if starting with a pre-trained model.
- Adjust hyperparameters based on performance.
Step 6: Evaluate the Updated Model
- Measure performance using metrics like accuracy, precision, recall, and F1 score.
- Pinpoint areas where the model struggles and adjust accordingly.
Step 7: Improve with Data Augmentation
- Use techniques like cropping, flipping, and rotation to increase dataset variability.
- Prevent overfitting with data augmentation.
Step 8: Monitor and Maintain
- Continuously monitor real-world performance and adjust for any emerging issues.
- Add new classes proactively
Want to stay updated?
- Follow us on Twitter and LinkedIn for more content on computer vision, training data, and active learning.
- Join the Slack community to chat and connect.
Frequently asked questions
Look for signs such as decreased accuracy on new data, changes in business requirements or environment, insufficient data for existing classes, or signs of overfitting. Monitoring performance metrics regularly can help identify these needs.
Improved Accuracy: Helps recognize a broader range of objects or patterns.
Increased Versatility: Extends the model’s applicability to new use cases.
Enhanced Robustness: Enables the model to adapt to variations in input, like lighting or viewpoint changes.
High-quality, diverse, and representative data is crucial. Ideally, you should have 100–1000 examples per class, depending on the class complexity and model size.
Fine-tuning involves adjusting model parameters or using transfer learning to optimize performance for the new classes. It ensures the model adapts effectively to the updated dataset.
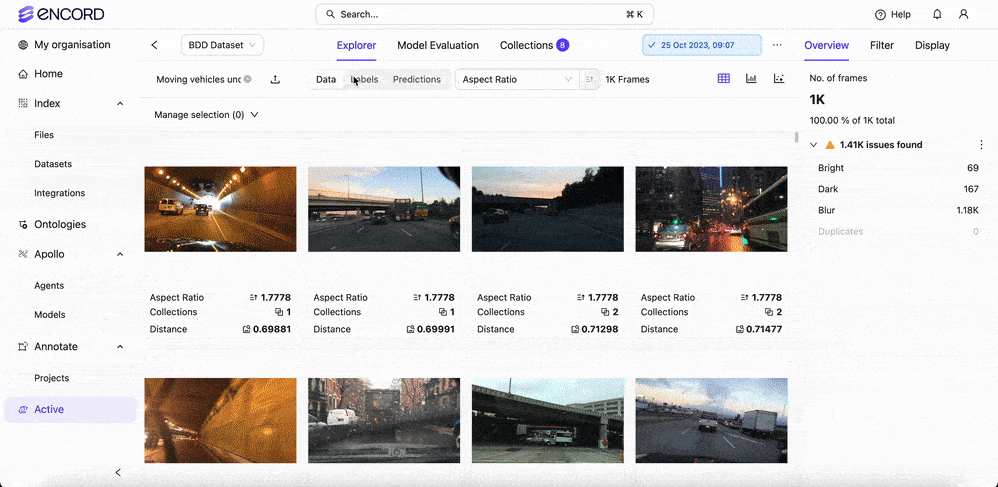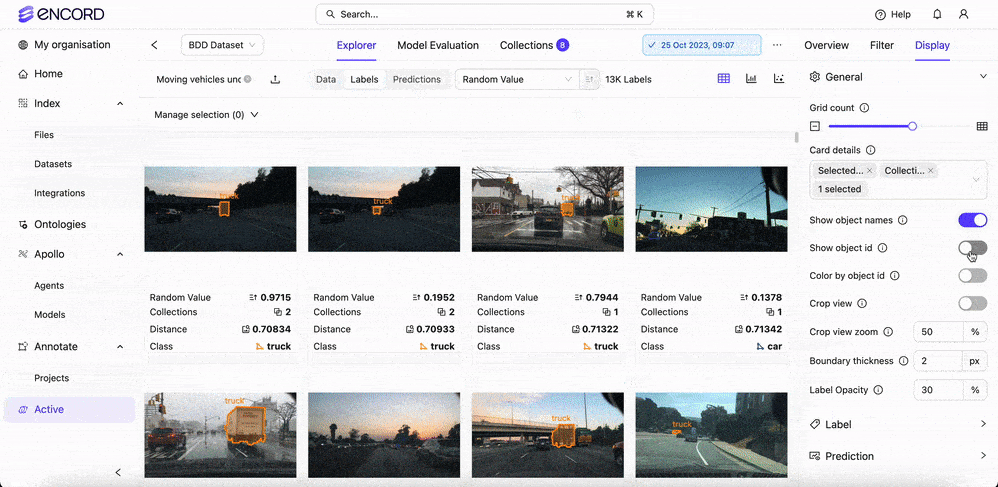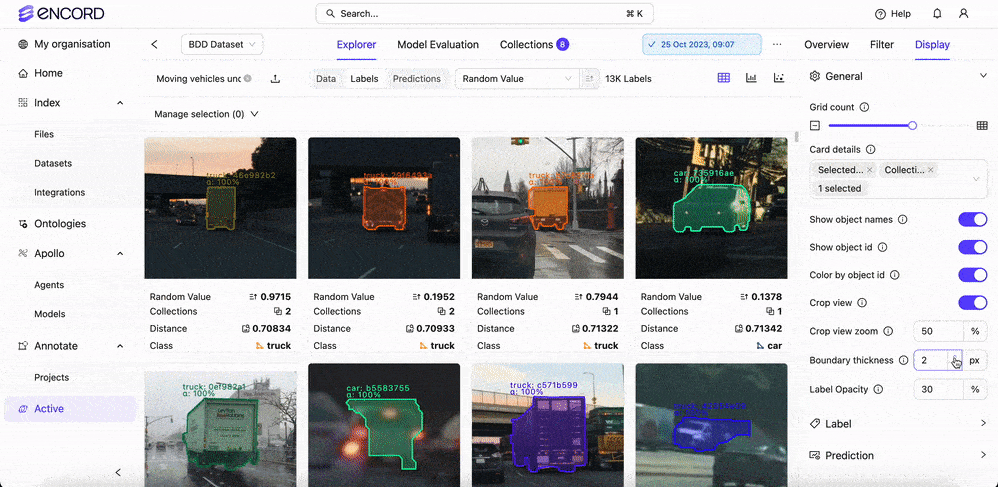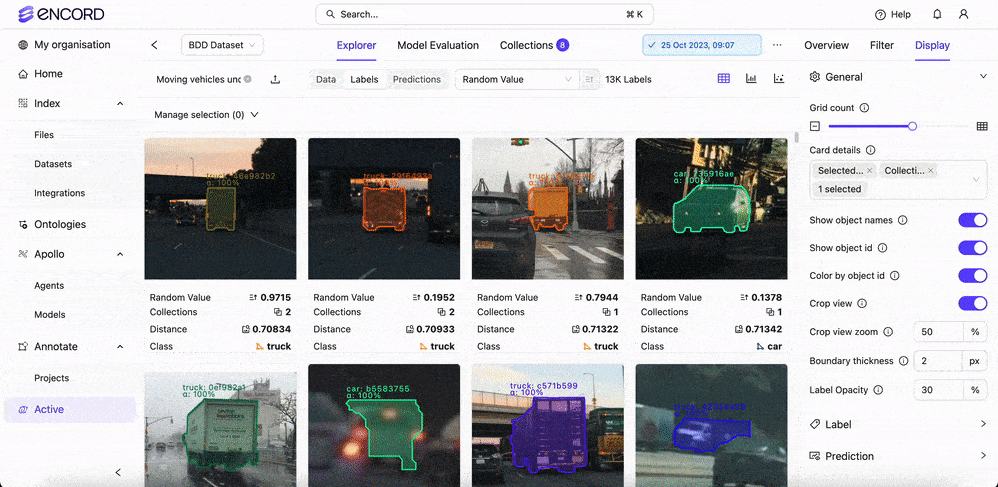
Yes, Encord allows users to fully customize classes and their associated colors. When setting up the ontology, you can define colors for each class to differentiate between various objects, making it easier to visualize the annotations in the label editor.
The sidebar in Encord Active has been redesigned to be collapsed by default, allowing for more screen real estate. Filters have also been repositioned to the left side, making it easier for users to access and apply them without cluttering the workspace.
Yes, Encord allows users to combine existing classes and expand into new classes as part of their data annotation process. This flexibility ensures that the labeling structure remains aligned with the evolving needs of the project.
Yes, Encord allows users to customize the grid count and display settings to accommodate longer text entries, ensuring that users can view extensive content comfortably within the user interface.