5 Strategies To Build Successful Data Labeling Operations

ML Lead at Encord
Data labeling operations are an essential component of training and building a computer vision model. Data operations are a function that oversees the full lifecycle of data labeling and annotation, from sourcing and cleaning through to training and making a model production-ready.
Data scientists and machine learning engineers aren’t wizards. Getting computer vision projects production-ready involves a lot of hard work, and behind the scenes are tireless professionals known as data operations teams.
Data operations, also known as data labeling operations teams, play a mission-critical role in implementing computer vision artificial intelligence projects.
Especially when a project is data-centric. It’s important and helpful to have an automated, AI-backed labeling and annotation tool, but for a project to succeed, you also need a team and process to ensure the work goes smoothly.
In other words, to ensure data labels and annotations are high-quality, a data labeling operations function is essential.
In this article, we will cover:
- Why data labeling operations are crucial for any algorithmic learning project (e.g., CV, ML, AI, etc.)?
- What are the benefits of data labeling operations?
- Should you buy or build data labeling and annotation software?
- 5 strategies for creating successful data labeling operations
Let’s dive in . . .
Why do Computer Vision Projects Need Data Labeling?
Data labeling, also known as data annotation, is a series of tasks that take raw, unlabeled data and apply annotations and labels to image or video-based datasets (or other sources of data) for computer vision and other algorithmic models.
Quality and accuracy are crucial for computer vision projects. Inputting poor-quality, badly labeled, and annotated images or videos will generate inaccurate results.
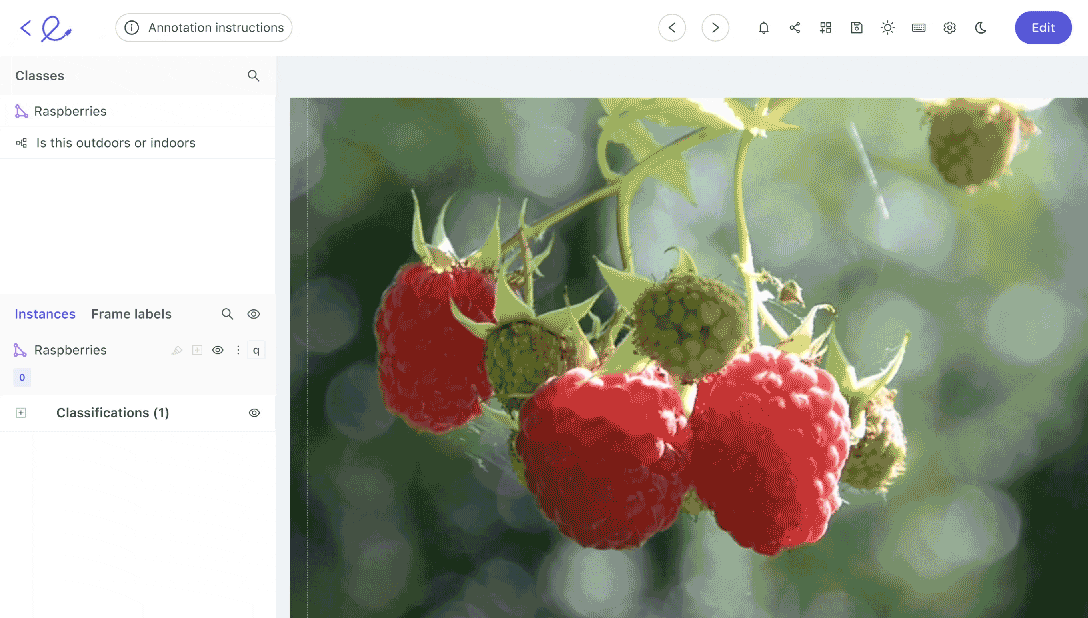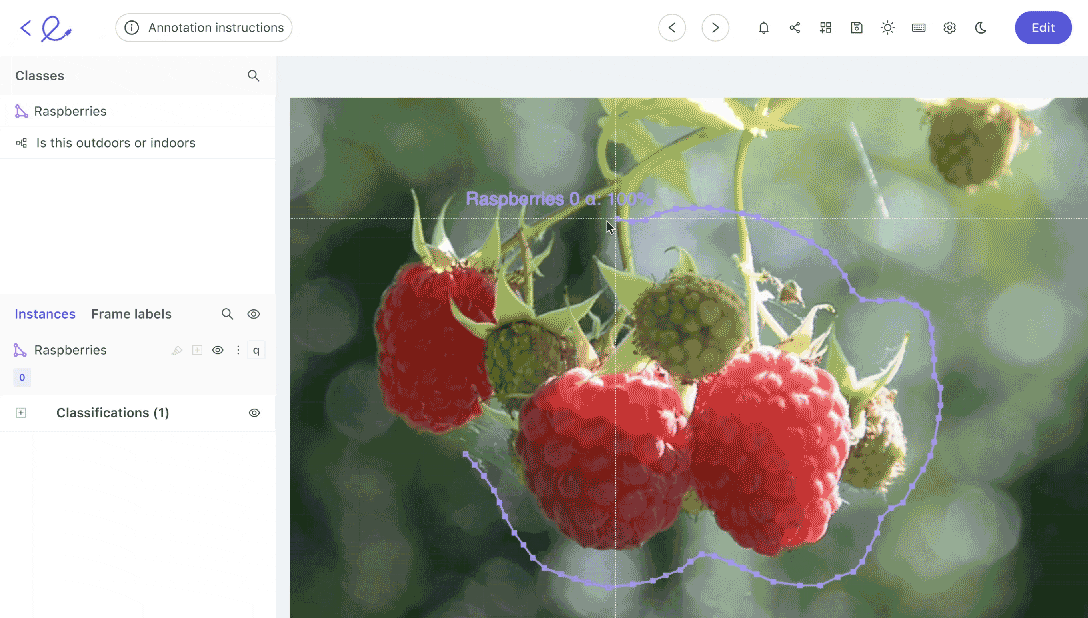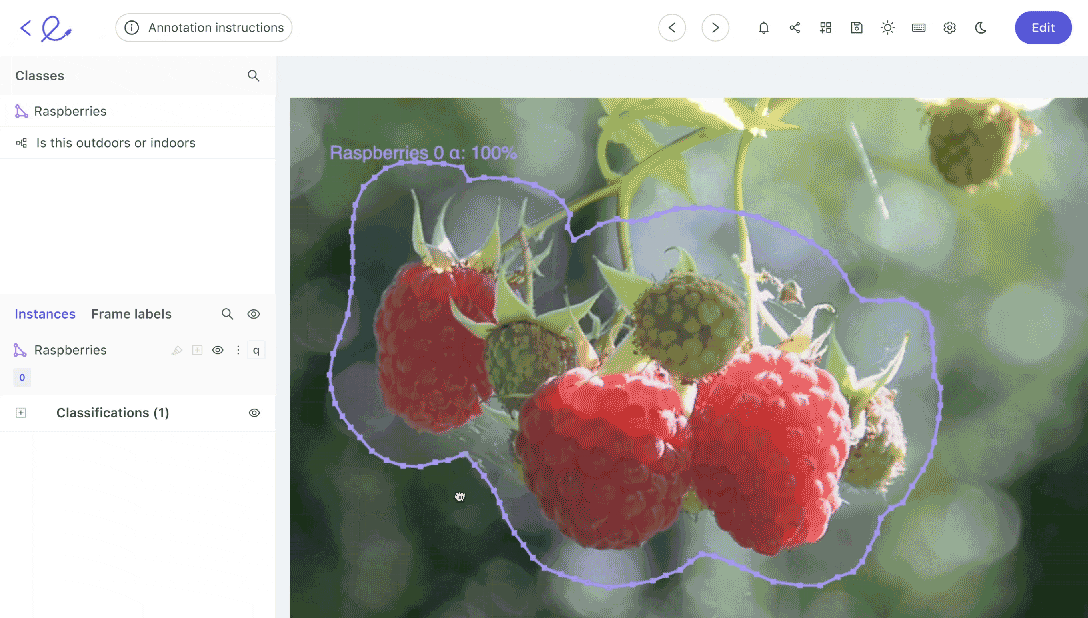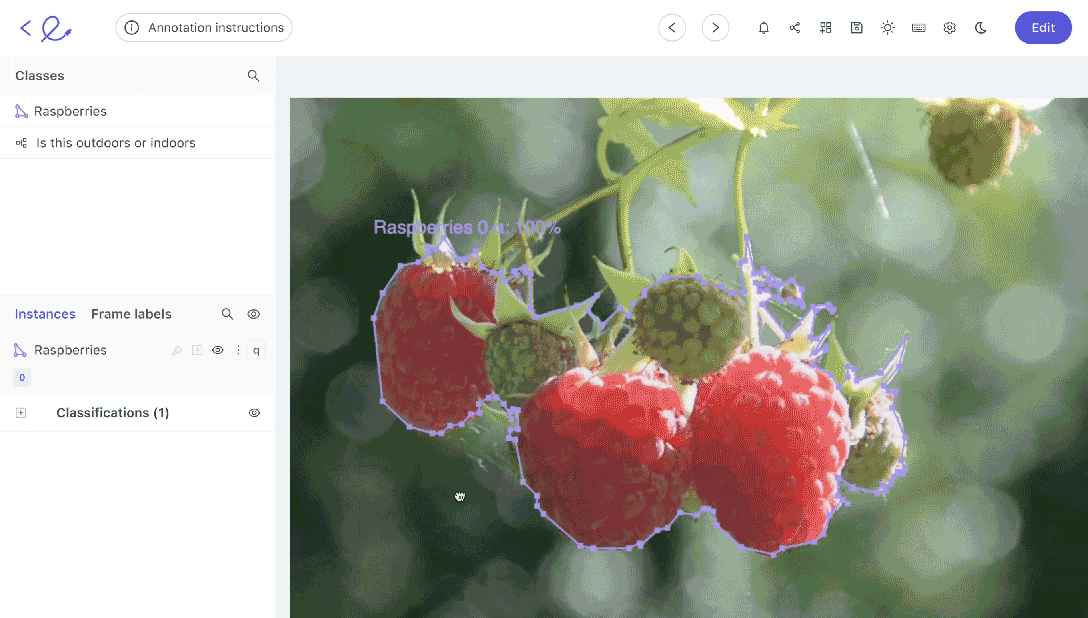
Data labeling can be implemented in a number of ways. If you’ve only got a small dataset, your annotation team might be able to manage using manual annotation. Going through each image or video frame one at a time.
However, in most cases, it helps to have an automated data annotation tool and to establish automated workflows to accelerate the process and improve quality and accuracy.
Why are Data Labeling Operations Mission-critical?
An algorithmic model's performance is only as effective as the data it’s trained on.
Dozens of sectors, including medical and healthcare, manufacturing, and satellite images for environmental and defense purposes, rely on high-quality, highly-accurate data labeling operations.
Annotations and labels are how you show an algorithmic model, including computer vision models and what’s in images or videos. Algorithms can’t see. We have to show them. Labels and annotations are how humans train algorithms to see, understand, and contextualize the content/objects within images and videos.
Data labeling operations make all of this possible. There’s a lot of work that goes into making data training and then production-ready, including data cleaning tasks, establishing and maintaining a data pipeline, quality control, and checking models for bias and error.

It all starts with sourcing the data. Either this is proprietary or can come from open-source datasets.
 Here’s our guides for:
Here’s our guides for: 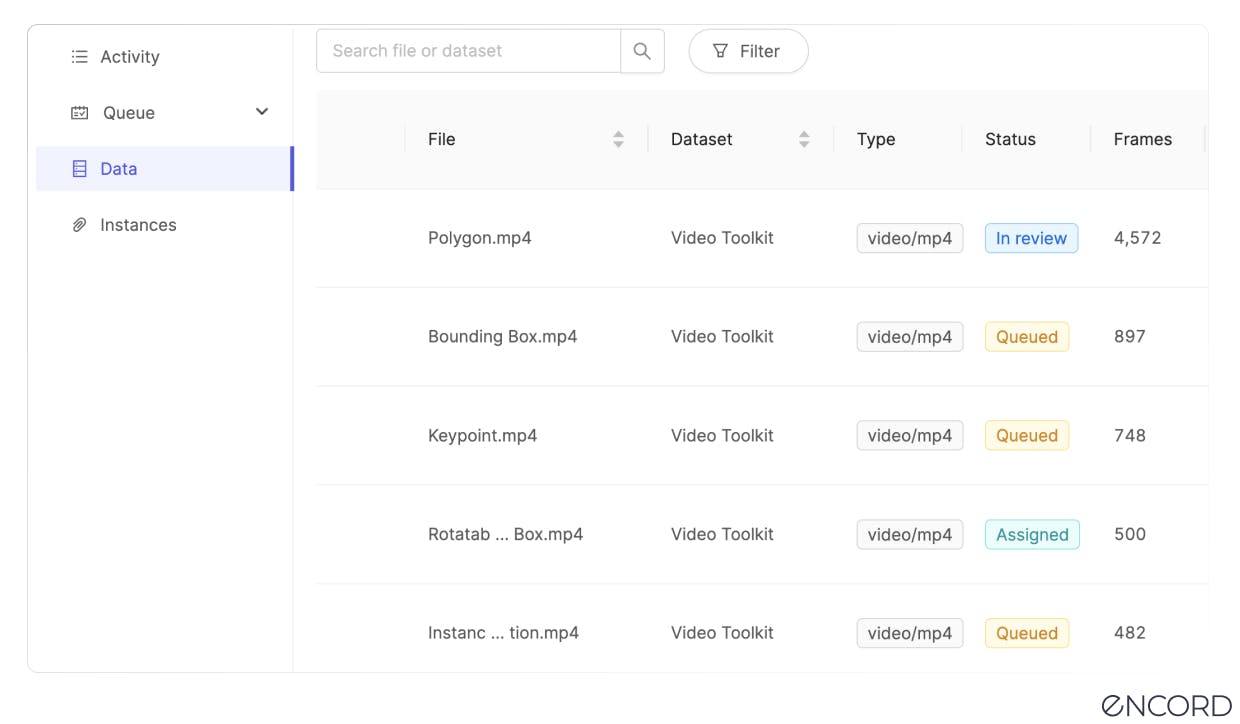
What Are The Benefits of Data Labeling Operations?
There are numerous benefits to having a highly-skilled and smoothly-ran data labeling operations team, such as:
- Improved accuracy and performance of machine learning and computer vision models, thanks to higher-quality training data going into them.
- Reduced time and cost of implementing full-cycle data labeling and annotations.
- Improved quality of training data, especially when data ops is responsible for quality control and iterative learning and applies automated tools using a supervised or semi-supervised approach.
- An effective data ops team ensures a smooth and unending flow of high-quality data, helping to train a computer vision model.
- With the right data ops team, you can make sure the machine learning ops (MLops) team is more effective, supporting model training to produce the desired outcomes.
Buy vs. Build for Data Labeling Ops Tools?
Whether to buy or build data labeling tools is a question many teams and project leaders consider.
It might seem an advantage to develop your own data labeling and annotation software. However, the downsides are that it’s a massively expensive and time-consuming investment.
Having developed in-house software, you will need engineers to maintain and update it. And what if you need new features? Your ability to scale and adapt is more restricted.
There are open-source tools and lots of them. However, for commercial data ops teams, most don’t meet the right requirements.
Compared to building your own solution, buying/signing-up for a commercial platform is several orders of magnitude more cost and time-effective. Plus, you can be up and running in a matter of days, even hours, compared to 9 to 18 months if you go the in-house route.
For projects that need tools for specific use cases, such as collaborative annotating tooling for clinical data ops teams and radiologists, there are commercial platforms on the market tailored for numerous industries, including healthcare.
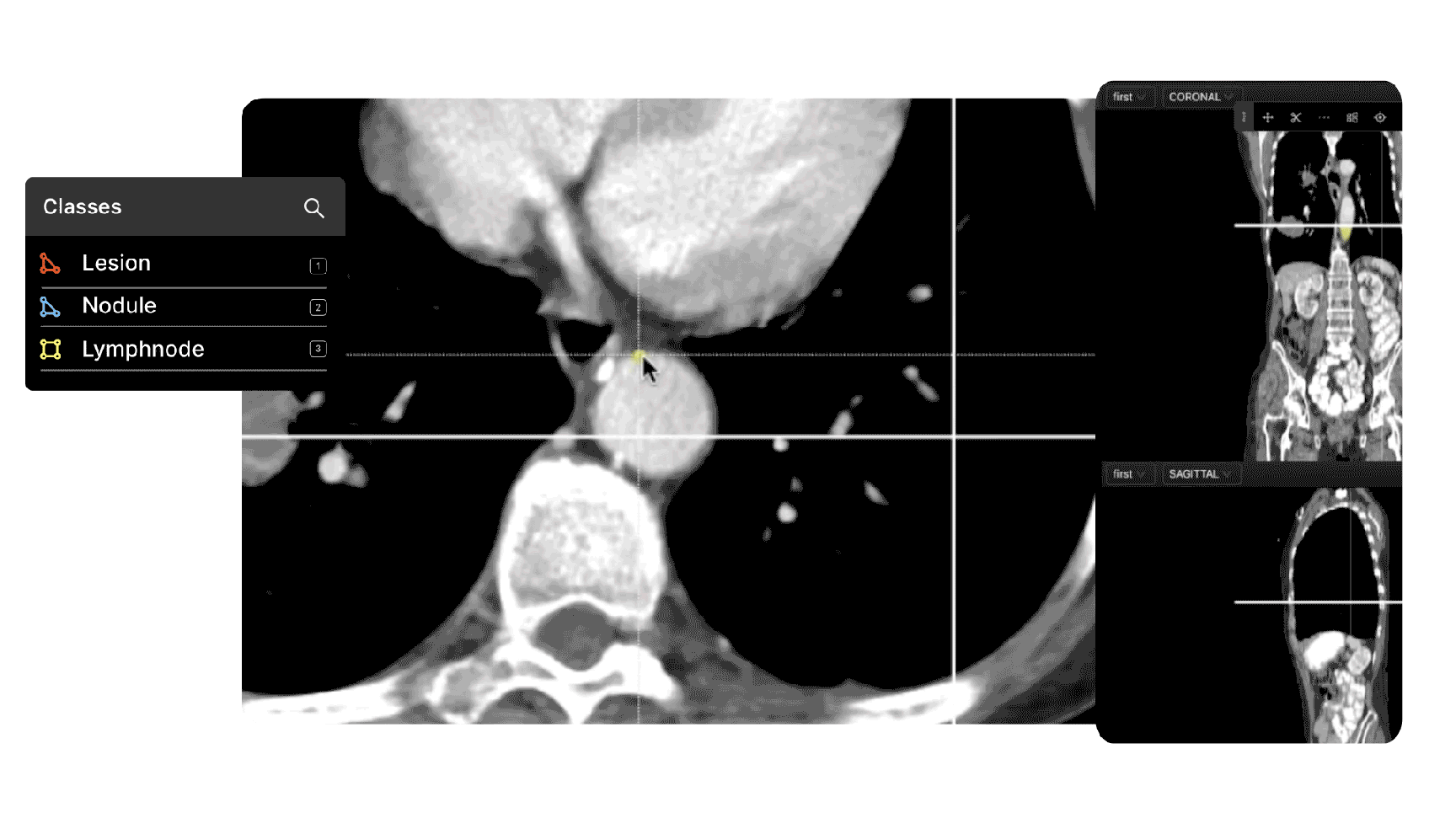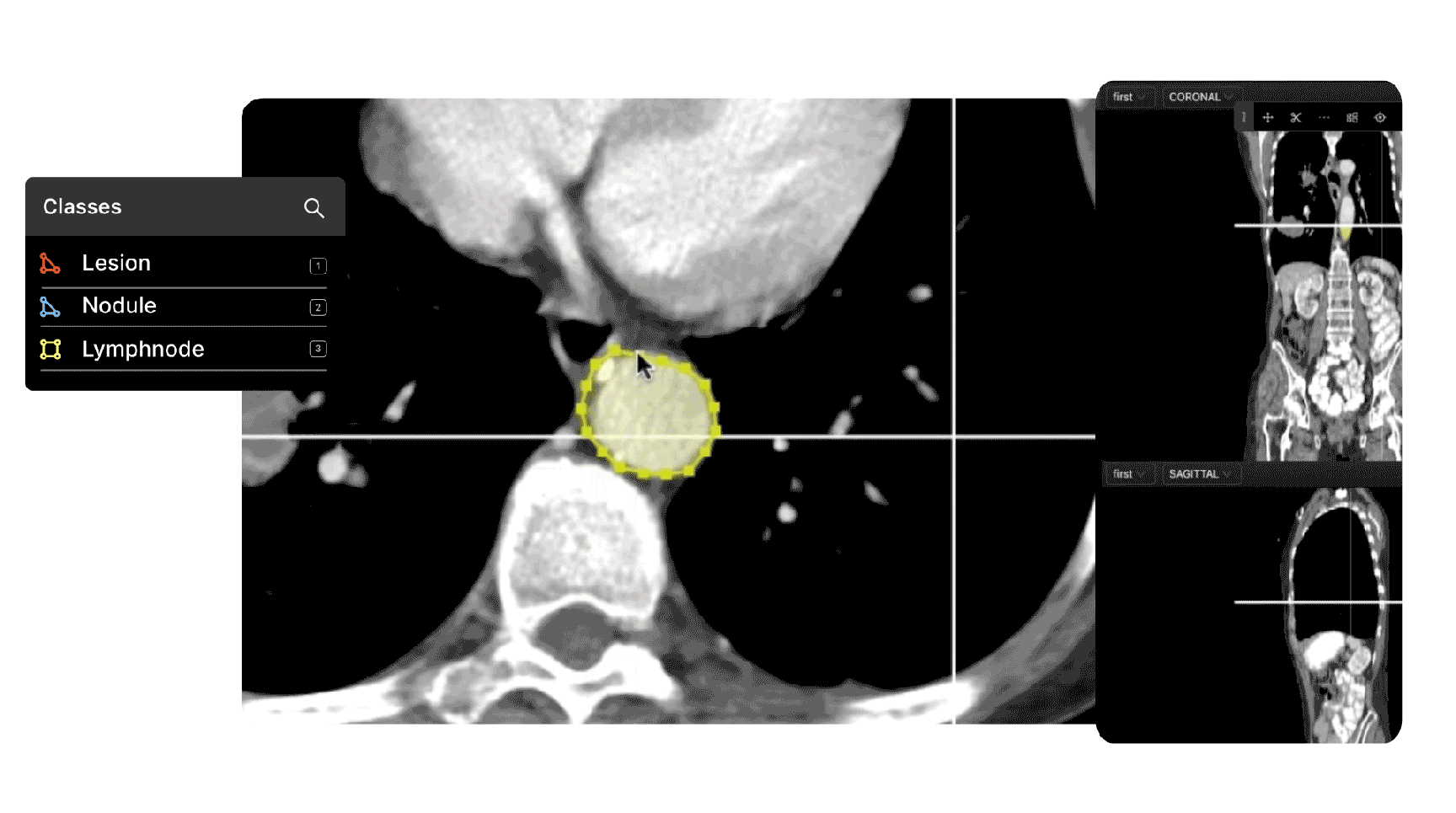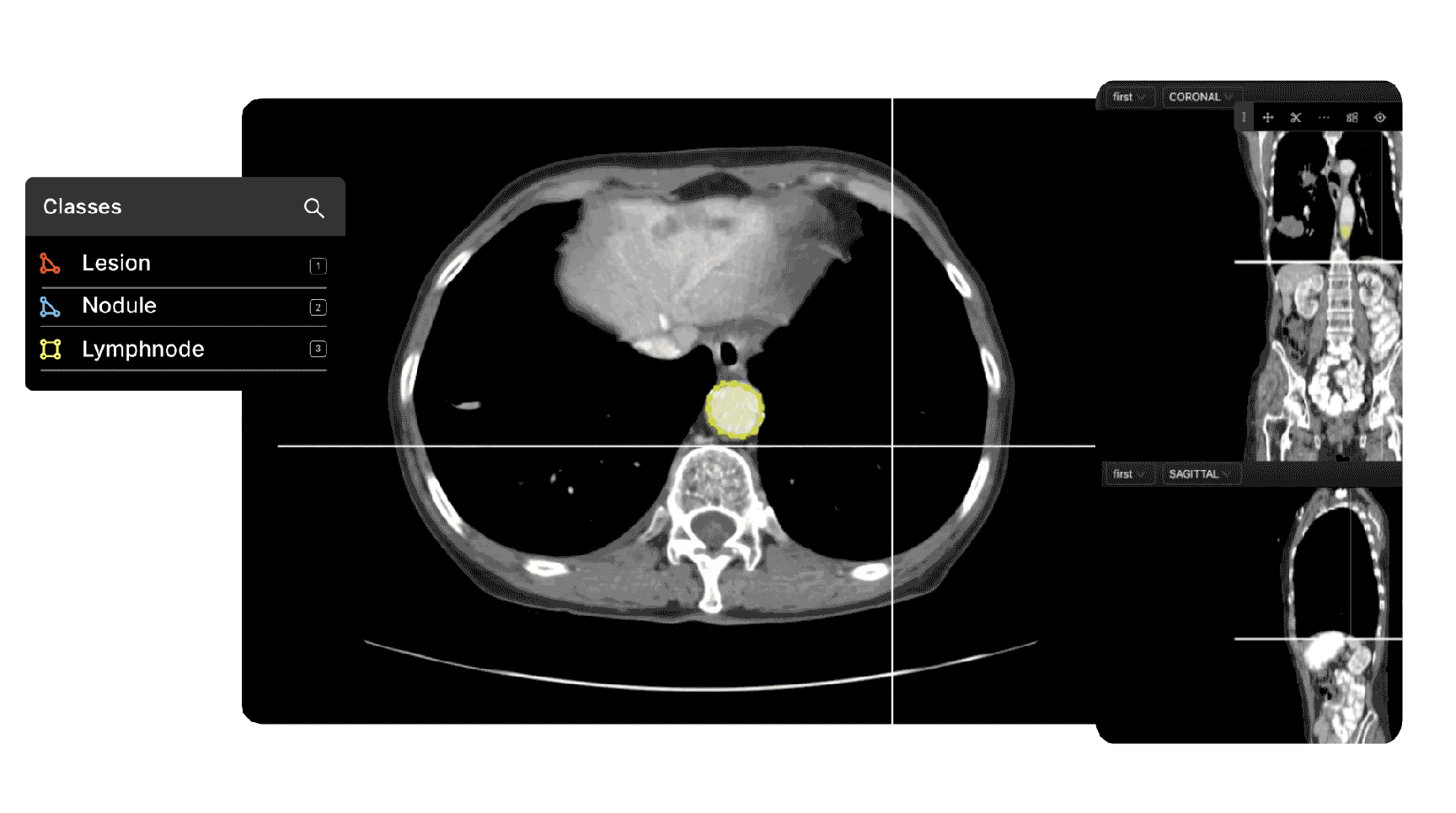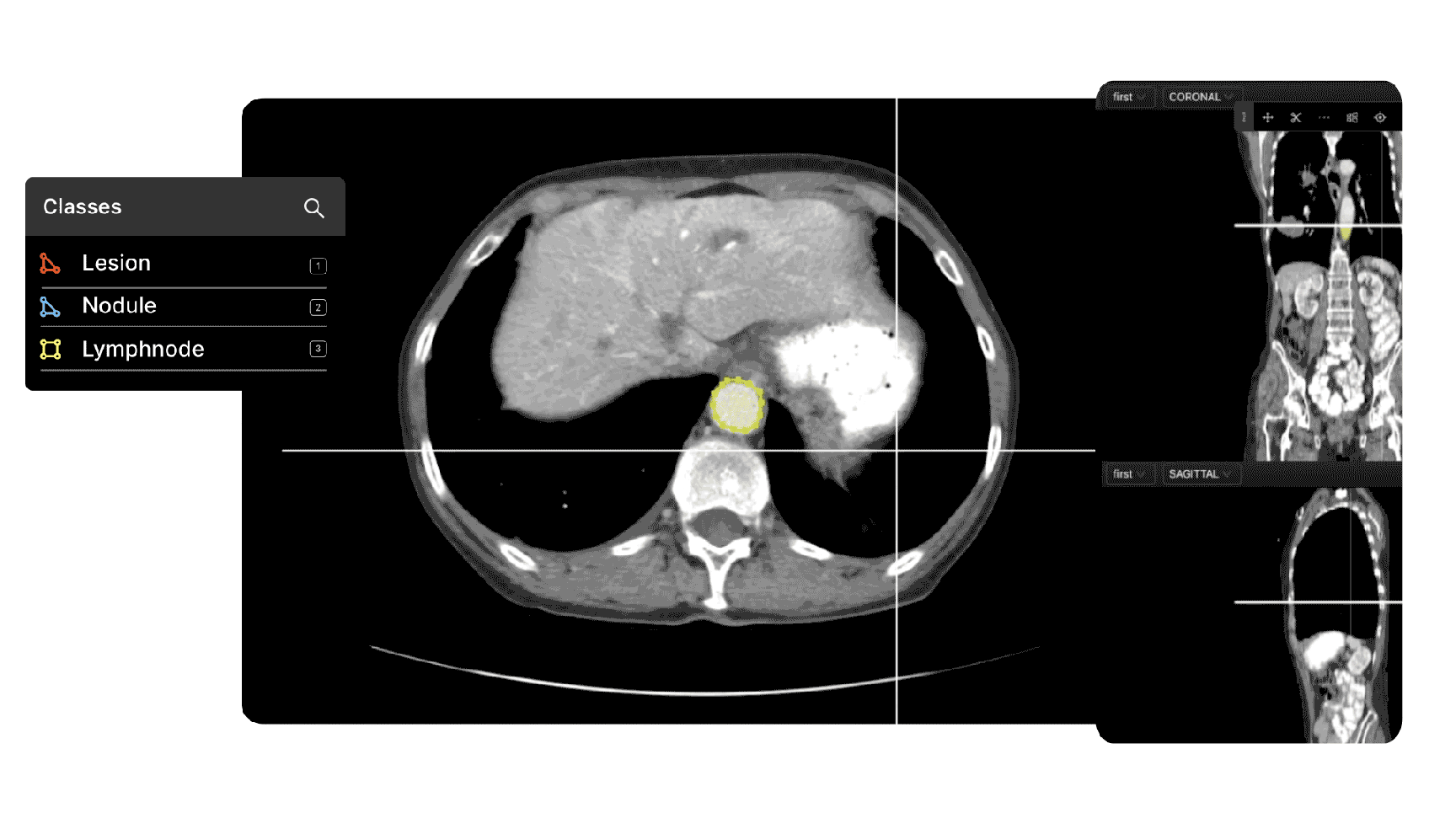
5 Strategies to Create Successful Data Labeling Operations
Now let’s look at 5 strategies for creating successful data labeling operations.
Understand the use case
Before launching into a project, data ops and ML leaders need to understand the problems they’re trying to solve for the particular use case.
It’s a helpful exercise to map out a series of questions and work with senior leadership to understand project objectives and the routes to achieving them successfully.
Begin the process of establishing data operations by asking yourself the following questions: - What are the project objects?
- How much data and what type of data does this project need?
- How accurate does the model have to be when it’s production-ready to achieve the objectives?
- How much time does the project have to achieve the goals?
- What outcomes are senior leadership expecting?
- Is the allocated budget and resources sufficient to produce the results senior leaders want?
- If not, how can we argue the business case to increase the budget if needed?
- What’s the best way to implement data labeling operations: In-house, outsourced, or crowd-sourced?
Once you’ve worked through the answers to these questions, it’s time to get build a data labeling operations team, processes, and workflows.
Document labeling workflows and create instructions
Taking a data-centric approach to data ops means that you can treat datasets, including the labels and annotations, as part of your organization's and project's intellectual property (IP). Making it more important to document the entire process.
Documenting labeling workflows means that you can create standard operating procedures (SOPs), making data ops more scalable. It’s also essential for safeguarding datasets from data theft and cyberattacks and maintaining a clearly auditable and compliant data pipeline.
Designing operational workflows before a project starts is essential. Otherwise, you’re putting the entire project at risk once data starts flowing through the pipeline.
Create clear processes. Get the tools you need, budget, senior leadership buy-in, and resources, including operating procedures, before the project starts.
Plan for the long haul (make your ontology expandable)
Whether the project involves video annotation or image annotation or you’re using an active learning pipeline to accelerate a model’s iterative learnings, it’s important to make your ontology expandable.
Regardless of the project, use case, or sector, including whether you’re annotating medical image files, such as DICOM and NIfTI, an expandable ontology means it’s easier to scale.
Getting the ontology and label structure right at the start is important. No matter which approaches you take to labeling tasks or whether you automate them, everything flows from the labels and ontology you create.
Start small and iterate
The best way to build a successful data labeling operations workflow is to start small, learn from small setbacks, iterate, and then scale.
Otherwise, you risk trying to annotate and label too much data in one go. Annotators make mistakes, meaning there will be more errors to fix. It will take you more time to attempt to annotate and label a larger dataset, to begin with, than to start on a smaller scale.
Once you’ve got everything running smoothly, including integrating the right labeling tools, then you can expand the operation.
Use iterative feedback loops, implement quality assurance, and continuously improve
Iterative feedback loops and quality assurance/control are an integral part of creating and implementing data operations.
Labels need to be validated. You need to make sure annotation teams are applying them correctly. Monitor for errors, bias, and bugs in the model. It’s impossible to avoid errors, inaccuracies, poorly-labeled images or video frames, and bugs.
With the right AI-powered, automated data labeling and annotation tool, you can reduce the number and impact of errors, inaccuracies, poorly-labeled images or video frames, and bugs in training data and production-ready datasets.
Pick an automation tool that integrates into your quality control workflows to ensure bugs and errors are fixed faster. This way, you’ll have more time and cost-effective feedback loops, especially if you’ve deployed an automated data pipeline, active learning pipelines, or micro-models.

Build More Streamlined and Effective Data Label Operations With Encord
With Encord and Encord Active, automated tools used by world-leading AI teams, you can build data labeling operations more effectively, securely, and at scale.
Encord was created to improve the efficiency of automated image and video data labeling for computer vision projects. Our solution also makes managing data ops and a team of annotators easier, more time, and cost-effective while reducing errors, bugs, and bias.
Encord Active is an open-source active learning platform of automated tools for computer vision: in other words, it's a test suite for your labels, data, and models.
With Encord, you can achieve production AI faster with ML-assisted labeling, training, and diagnostic tools to improve quality control, fix errors, and reduce dataset bias.
Make data labeling more collaborative, faster, and easier to manage with an interactive dashboard and customizable annotation toolkits. Improve the quality of your computer vision datasets, and enhance model performance.
Key Takeaways: How to build successful data labeling operations
Building a successful data labeling operation is essential for the success of computer vision projects. It takes time, work, and resources. But once you’ve got the people, processes, and tools in place, you can take data operations to the next level and scale computer vision projects more effectively.
- Successful data operations need the following scalable processes:
- Project goals and objectives;
- Documented workflows and processes;
- An expandable ontology;
- Iterative feedback loops and quality assurance workflows;
- And the right tools to make everything run more smoothly, including automated, AI-based annotation and labeling.
Ready to improve the performance and scale your data operations, labeling, and automated annotation?
Sign-up for an Encord Free Trial: The Active Learning Platform for Computer Vision, used by the world’s leading computer vision teams.
AI-assisted labeling, model training & diagnostics, find & fix dataset errors and biases, all in one collaborative active learning platform, to get to production AI faster. Try Encord for Free Today.
Want to stay updated?
- Follow us on Twitter and LinkedIn for more content on computer vision, training data, and active learning.
- Join the Slack community to chat and connect.
Frequently asked questions
Custom metadata can be added to frames in Encord during the data import process by using a single JSON file. This allows data analysts and machine learning engineers to register their data along with relevant metadata in one step. Additionally, if more metadata needs to be added later, Encord provides an SDK to expand the metadata associated with existing frames.
Encord allows for the integration of an agent stage within workflows, which can perform programmatic actions like pre-labeling or quantifying the confidence level of outputs. This feature helps teams optimize their review processes based on the confidence in the annotations, allowing for smarter routing as needed.
Encord allows for the incorporation of custom agents developed by teams into the pre-labeling phase, which enhances the automation of the annotation process. This customizability helps teams leverage their unique tools and improve overall efficiency in their workflows.
Before selecting labeling tools within Encord, teams are encouraged to conduct initial experiments with automatic label generation to understand their specific annotation needs. This allows for a more informed decision on which tools will best support their projects.
Yes, Encord can integrate your existing pre-labeling models into the workflow. This means that when annotators reach the annotation stage, the labels generated by your models will already be in place, allowing for a more streamlined review and correction process.
Setting up a project on Encord involves loading data into the platform, creating a labeling specification, and then using the provided datasets to create test projects. Users can then annotate the data according to their specifications and export the results.
Encord facilitates consensus labeling workflows by allowing teams to set up pre-labeling blocks that leverage models through an API. This ensures that tasks are automatically pre-labeled before being assigned to annotators, streamlining the labeling process.
Encord Active provides various functionalities to enhance label management, including the ability to filter labels and analyze label distribution across projects. Understanding these actions can help users leverage the full potential of their annotations.
Encord allows users to connect their own models for pre-labeling tasks. This integration facilitates faster annotation by leveraging machine learning capabilities, streamlining the workflow for teams looking to enhance their efficiency.
Yes, Encord facilitates the creation of machine-generated labels to streamline annotation workflows. This feature allows teams to define their processes more efficiently, helping to build better models faster.