39 Computer Vision Terms You Should Know

Product Manager at Encord
Computer vision is a complex interdisciplinary scientific field. Understanding and keeping track of every term people use in this field can be challenging, even for seasoned experts.
We’ve solved this by producing helpful quick-reference glossaries of the most commonly used computer vision terms and definitions.
This post provides a glossary and guide for 39 computer vision terms and definitions. For annotators and project leaders, there are some terms you might know inside and out and others that you’ve been aware of, but a refresher and explainer are always useful.

What is Computer Vision in Simple Terms?
Computer vision is an interdisciplinary scientific and computer science field that uses everything from simple annotation tools to artificial intelligence (AI), machine learning (ML), neural networks, deep learning, and active learning platforms to produce a high-level and detailed understanding, analysis, interpretation, and pattern recognition within images and videos.
In other words, it’s a powerful and effective way to use computing power, software, and algorithms to make sense of images and videos. Computer vision helps us understand the content and context of images and videos across various sectors, use cases, and practical applications, such as healthcare, sports, manufacturing, security, and numerous others.
Now let’s dive into our glossary of 39 of the most important computer vision terms and definitions that impact video annotation and labeling projects.
39 Computer Vision Terms and Definitions You Need To Know
#1: Image Annotation (also known as Image Labeling)
Computer vision models rely on accurate manual annotations during the training stage of a project. Whether AI (artificial intelligence) or machine learning-based (ML), computer vision models learn and interpret using the labels applied at the manual annotation stage.
6x Faster Model Development with Encord
Encord helps you label your data 6x faster, create active learning pipelines and accelerate your model development. Try it free for 14 days
#2: Computer Vision
Humans can see, interpret, and understand with our eyes and mind. Teaching computers to do the same is more complex, but generates better, more accurate results faster, especially when computer vision is combined with machine learning or AI.
Computer vision is a subset of artificial intelligence (AI), that produces meaningful outputs from images, videos, and other visual datasets. CV models need to be trained. With the right tools and algorithms, computer vision models make it possible for AI, ML, and other neural networks to see, interpret, and understand visual data, according to IBM.
#3: COCO
COCO is a benchmarking dataset for computer vision models, the acronym for Common Objects in Context (COCO).
“COCO is a large-scale object detection, segmentation, and captioning dataset”, an open-source AI-based architecture supported by Microsoft, Facebook (Meta), and numerous AI companies.
Researchers and annotators use the COCO dataset for object detection and recognition against a broader context of background scenes, with 2.5 million labeled instances in 328,000 images. It’s ideal for recognition, context, understanding the gradient of an image, image segmentation, and detecting keypoints in human movement in videos.
#4: YOLO
YOLO means, “You Only Look Once”, a real-time object detection algorithm that processes fast-moving images and videos. YOLO is one of the most popular model architectures and detection algorithms used in computer vision models. YOLO helps annotators because it’s highly accurate with real-time processing tasks while maintaining a reasonable speed and a fast number of frames per second (FPS), and it can be used on numerous devices.
#5: DICOM
The DICOM standard — Digital Imaging and Communications in Medicine (DICOM) — is one of the most widely used imaging standards in the healthcare sector.
DICOM started to take off in the mid-nineties, and is now used across numerous medical fields, including radiology, CT, MRI, Ultrasound, and RF, with thousands of devices and medical technology platforms equipped to support the transfer of images and patient information using DICOM.
DICOM makes it easier for medical providers in multi-vendor environments to transfer medical images, store images and patient data across multiple systems, and expand an image archiving and communications network, according to the standard facilitator, the National Electrical Manufacturers Association (NEMA).
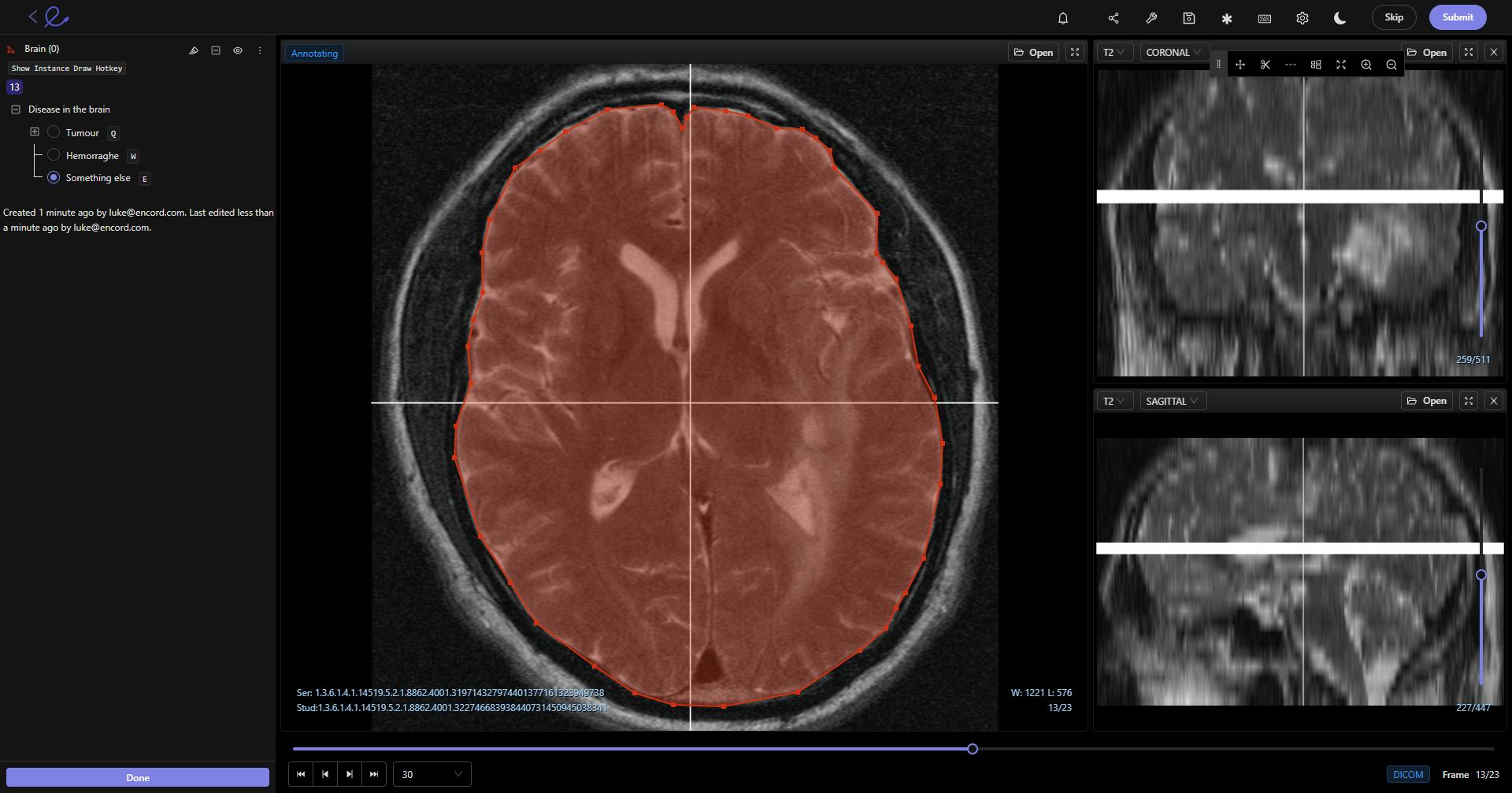
DICOM image annotation in Encord
#6: NIfTI
NIfTI is the invention and acronym for The Neuroimaging Informatics Technology Initiative. NIfTI is sponsored by The National Institute of Mental Health and the National Institute of Neurological Disorders and Stroke.
NIfTI is another highly-popular medical imaging standard created to overcome some challenges of other imaging standards, including DICOM (we’ve explained this in more detail in our article What’s The Difference Between DICOM and NIFTI?)
One of those challenges is the lack of orientation in certain image formats. It’s something that negatively impacts neurosurgeons. If you can’t tell which side of the brain is which, it can cause serious problems when understanding and diagnosing medical problems.
NIfTI solves this by allocating “the first three dimensions to define the three spatial dimensions — x, y and z —, while the fourth dimension is reserved to define the time points — t.”
Medical professionals and image annotators in the healthcare sector can work with both formats, depending on the computer vision models and tools used for medical image and video annotation work.
#7: NLP
Natural Language Processing (NLP) is an important subfield of computer science, computer vision models, AI, and linguistics. The development of NLP models started in the 1950s, and most of it has focused on understanding, analyzing, and interpreting text and human speech.
However, in recent decades, with the advancement of computer vision models, AI, ML, deep learning, and neural networks, NLP plays a role in image and video labeling and annotation. When NLP is integrated into computer vision models and tools, annotators can rely on it to generate automated descriptions and labels of images and videos being analyzed.
Integrating NLP with computer vision is useful for solving numerous problems across multiple fields and disciplines.
#8: AI
Artificial Intelligence (AI) is a way of leveraging algorithms, machine learning, neural networks, and other technological advances to solve problems and process vast amounts of data.
One of the most widely accepted modern definitions of AI is from John McCarthy (2004, quoted by IBM): “It is the science and engineering of making intelligent machines, especially intelligent computer programs. It is related to the similar task of using computers to understand human intelligence, but AI does not have to confine itself to methods that are biologically observable.”
#9: ML
Machine Learning (ML) is another constantly evolving branch of AI. An IBM computer scientist, Arthur Samuel, coined the term “machine learning”, starting with seeing whether a computer could play the game of checkers and beat a human. This happened in 1962 when a checkers master, Robert Nealey, played the game on an IBM 7094 computer, and lost.
Although trivial compared to modern ML networks and algorithms, this was a big step forward for machine learning. As algorithms and computer vision models are trained, they become more accurate, faster, and more powerful as they learn more.
Hence the widespread use of ML in computer vision models designed to understand, analyze, and process images and videos. It takes enormous computational power and complex, constantly evolving algorithms to extrapolate and interpret data from images and videos, and that’s where ML-based algorithms can play such a useful role.
#10: Deep Learning
It’s worth pointing out that ML, neural networks, and deep learning are often used interchangeably, as they all originate from an industry-wide exploration into the development and uses of AI.
However, there are distinct nuances and differences between them. Such as the fact that deep learning is a sub-field of machine learning, and neural networks are a sub-field of deep learning. One of the key differentiators is how each algorithmic model learns.
In the case of “Deep” machine learning, or Deep Learning, these models eliminate the need for much of the human intervention and manual work at the start. Depending, of course, on the quality of the data being fed into these algorithms. As always, when it comes to computer vision models, you can use deep learning tools and algorithms, but the quality of the annotated datasets at the start of the process, and tools used, influences the outcomes.
#11: Neural Networks
As mentioned above, neural networks, or artificial neural networks (ANNs), are a sub-field of deep learning, and fall within the remit of data science work. Neural networks involve a series of node layers that analyze data and transmit it between themselves. When there are three or more layers, this is known as a deep learning network, or algorithm.
Whereas, with a neural network, there’s generally only an input and output layer (also known as a node), with a maximum of two processing layers. Once a layer, or algorithmic model within this network reaches capacity, it sends data to the next node to be processed.
Each node in this network has a specific weight, threshold, and purpose. Similar to the human brain, the network won’t function unless every node is active, and data is being fed into it.
In the context of computer vision models, neural networks are often applied to images and videos. Depending on the amount of computational power required and the algorithms used to automate image and video-based models, neural networks might need more nodes to process larger amounts of images and videos.
#12: Active Learning Platform
An active learning platform, or pipeline, is the most effective way to accurately automate and integrate ML or AI-based algorithmic models into data pipelines. Active learning pipelines empower a model to train itself. They’re a valuable part of data science tasks. The more data it sees, the more accurate it will get, and ML teams can then give feedback to annotation teams on what annotated images and videos the model needs to further improve accuracy.
With Encord, you can design, create, and merge workflow scripts to implement streamlined data pipelines using APIs and SDKs.
#13: Frames Per Second (FPS)
Fundamentally, movies and videos are a series of recorded images — individual frames — that move quickly enough that our brain perceives them as a single film, rather than a string of static images.
The number of frames per second (FPS) is crucial to this concept. In the same way that the FPS rate impacts computer vision models.
An average for most videos is 60 FPS. However, this isn’t a fixed number. There are challenges associated with video annotation, such as variable frame rates, ghost frames, frame synchronization issues, an images gradient, and numerous others.
With effective pre-processing, a powerful AI-based computer vision model tool can overcome these challenges, avoiding the need to re-label everything when videos are very long, or have variable frame rates or ghost frames.
#14: Greyscale
Converting color images into one of many shades of grey, also known as greyscale, is useful if your computer vision model needs to process vast quantities of images. It reduces the strain on the computational and processing powers you’ve got available (placing less strain on CPUs and GPUs).
It speeds up the process, and in some sectors — such as healthcare — the majority of images aren’t in color. Greyscale or black-and-white images are the norm. With most computer vision software and tools, converting images or videos to greyscale is fairly simple, either before or during the initial annotation and upload process.
#15: Segmentation
Segmentation is the process of dividing a digital image or video into segments, reducing the overall complexity, so that you can perform annotation and labeling tasks within specific segments. Image segmentation is a way of assigning labels to pixels, to identify specific elements, such as objects, people, and other crucial visual elements.
#16: Object Detection
Object detection is another powerful feature of computer vision models and AI, ML, or deep learning algorithms. Object detection is the process of accurately labeling and annotating specific objects within videos and images. It’s a way of counting objects within a scene, and determining and tracking their precise location.
Annotators need the ability to accurately identify and track specific objects throughout a video, such as human faces, organs, cars, fast-moving objects, product components on a production line, and thousands of other individual objects.
#17: Image Formatting
Image formatting, also known as image manipulation, are two of the most widely used terms in computer vision tasks. Formatting is often part of the data cleansing stage, to format the images or videos ready for annotation, and further down the project pipeline, to reduce the computational power computer vision models, ML or AI-based algorithms need to apply to learn from the datasets.
Formatting tasks include resizing, cropping, converting them into grayscale images, or other formats. Depending on the computer vision tool you use for the annotation stage, you might need to edit a video into shorter segments. However, with the most powerful image and video annotation tools, you should have the ability to display and analyze them natively, without any or too much formatting.
#18: IoU and Dice Loss
Computer vision machine learning teams need to measure and analyze the performance of models they’re using against certain benchmarks. Two of the main computational metrics used are the Intersection over Union (IoU) score and Dice Loss.
The Intersection over Union (IoU) score is a way of measuring the ground truth of a particular image or video and the prediction a computer vision model generates. IoU is considered one of the best measurements for accuracy, and any score over 0.5 is considered acceptable for practical applications.
Dice loss is a measurement used in image processing to understand the similarity between two or more two or more entities. Dice loss is represented as a coefficient after evaluating the true positive, false positive, and negative values. Dice loss is more widely practiced in medical image computer vision applications to address imbalances between foreground and background components of an image.
#19: Anchor Boxes and Non-Maximum Suppression (NMS)
Anchor boxes and non-maximum suppression (NMS) are integral to implementation of object detection algorithms in computer vision models.
Anchor boxes are used to set bounding boxes of a predefined height and width within an image or video frame. It’s a way of capturing specific aspect ratios to train a computer vision model on.
However, because anchor boxes are far from perfect, the concept of NMS is used to reduce the number of overlapping tiles before images or videos are fed into a computer vision model.
#20: Noise
Noise is a way of describing anything that reduces the overall quality of an image or video. Usually an external factor that could interfere with the outcome of a computer vision model, such as an image that’s out of focus, blurred, pixilated, or a video with ghost frames.
At the data cleansing stage, it’s best to reduce and edit out as much noise as possible to ensure images and videos are of a high enough quality for the annotation stage.
#21: Blur Techniques
Blur techniques, also known as the smoothing process, is a crucial part of computer vision image annotation and pre-processing. Using blur techniques is another way to reduce the ‘noise’ in an image or video. Manual annotation or data cleansing teams can apply blurring techniques, such as the Gaussian Blur, to smooth an image before any annotation work starts on a dataset.
#22: Edge Detection
Edge detection is another integral part of computer vision projects. Edge detection helps to identify the various parts of an image or video with varying degrees of brightness or discontinuities of patterns. It’s also used to extract the structure of particular objects within images, and it’s equally useful when deployed in object detection.
#23: Dynamic and Event-Based Classifications
Dynamic classifications are also known as “events-based” classifications, a way for annotators and machine learning teams to identify what an object is doing. This classification format is ideal for moving objects, such as cars; e.g. whether a car is moving, turning, accelerating, or decelerating from one frame to the next.
Every bit of detail that’s annotated gives computer vision models more to learn from during the training process. Hence the importance of dynamic classifications, such as whether its day or night time in an image or video. Annotators can apply as much granular detail as needed to train the computer vision model.
#24: Annotation
Annotations are markups, or labels, applied to objects and metadata in images and videos that are used to teach computer vision models the ground truth within the training data. Annotations can be applied in countless ways, including text-based labels, detailed metadata, polygons, polylines, keypoints, bounding boxes, primitives, segmentations, and numerous others.
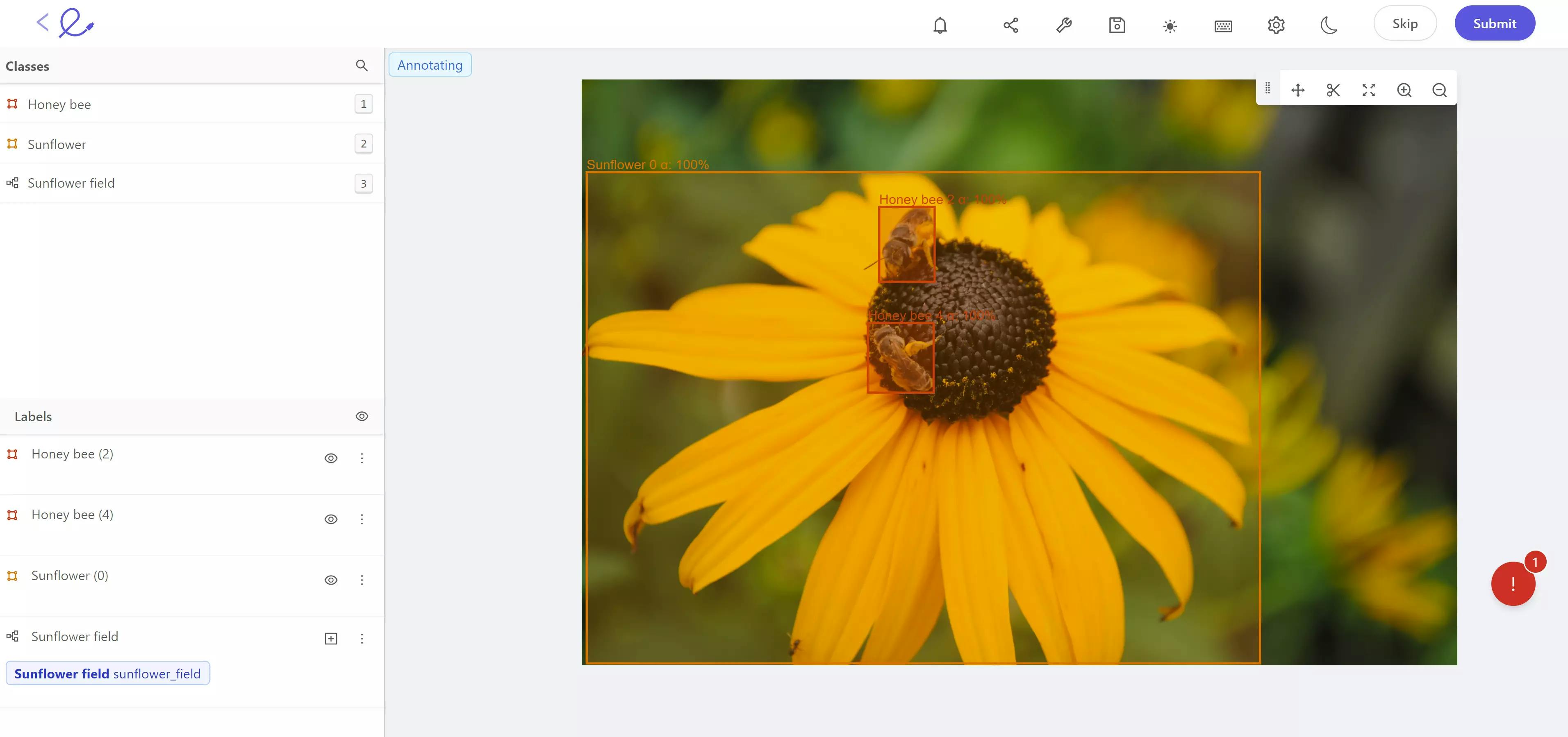
Data annotation in the Encord platform
#25: AI-assisted Labeling
Manual annotation is a time-consuming and labor intensive task. It's far more cost and time effective when annotation teams use automation tools, as a form of supervised learning, when annotating videos and images.
AI-assisted labelling features various software tools should come with — including Encord — are interpolation, automated object tracking, and auto object segmentation.
Micro-models are AI-assisted labelling tools unique to Encord, and they are “annotation-specific models that are overtrained to a particular task or particular piece of data.”
Micro-models are perfect for bootstrapping automated video annotation projects, and the advantage is they don’t need vast amounts of data. You can train a micro-model with as few as 5 annotated images and set up a project in a matter of minutes.
#26: Ghost Frames
Ghost frames can be a problem for video annotation teams, similar to other problems often encountered, such as variable frame rates. Ghost frames are when there’s a frame with a negative timestamp in the metadata. Some media players play these ghost frames, and others don’t.
One way to solve this problem is to re-encode a video — unpacking a video, frame-by-frame — and piecing it together again. During this process, you can drop corrupted frames, such as ghost frames. You can do this by implementing simple code-based commands into the original video file, and it's best to do this before starting any video annotation or labeling work.
#27: Polygons
Polygons are an annotation type you can draw free-hand and then apply the relevant label to the object being annotated. Polygons can be static or dynamic, depending on the object in question, whether it's a video or an image, and the level of granular detail required for the computer vision model. Static polygons, for example, are especially useful when annotating medical images.
#28: Polylines
Polylines are another annotation type, a form of supervised learning, ideal when labeling a static object that moves from frame to frame. You can also draw these free-hand and label the object(s) accordingly with as much granular detail as needed. Polylines are ideal for roads, walkways, railway lines, power cables, and other static objects that continue throughout numerous frames.
#29: Keypoints
Keypoints outline the landmarks of specific shapes and objects, such as a building or the human body. Keypoint annotation is incredibly useful and endlessly versatile. Once you highlight the outline of a specific object using keypoints it can be tracked from frame to frame, especially once AI-based systems are applied to an image or video annotation project.
#30: Bounding Boxes
A bounding box is another way to label or classify an object in a video or image. Bounding boxes are an integral part of the video annotation project. With the right annotation tool, you can draw bounding boxes around any object you need to label, and automatically track that annotation from frame to frame. For example, city planners can use bounding box annotations to track the movement of vehicles around a city, to assist with smart planning strategies.
#31: Primitives (skeleton templates)
Primitives, also known as skeleton templates, are a more specialized annotation type, used to templatize specific shapes and objects in videos and images. For example, primitives are ideal when they’re applied to pose estimation skeletons, rotated bounding boxes, and 3D cuboids.
#32: Human Pose Estimation (HPE)
Human Pose Estimation (HPE) and tracking is a powerful computer vision supervised learning tool within machine learning models. Tracking, estimating, and interpolating human poses and movements takes vast amounts of computational power and advanced AI-based algorithms. Pose estimation is a process that involves detecting, tracking, and associating dozens of semantic keypoints.
Using HPE, annotators and ML teams can leverage computer vision models and highly-accurate AI-based algorithms to track, annotate, label, and estimate movement patterns for humans, animals, vehicles, and other complex and dynamic moving objects, with numerous real-world use cases.
#33: Interpolation
Interpolation is one of many automation features and tools that the most powerful and versatile software comes with. Using a linear interpolation algorithm, annotators can draw simple vertices in any direction (e.g., clockwise, counter clockwise, etc.), and the algorithm will automatically track the same object from frame to frame.
#34: RSN
Residual Steps Network (RSN) is one of numerous machine learning models that are often applied to human pose estimation for computer vision projects. RSN is an innovative algorithm that aggregates features and objects within images and videos that have the same spatial size with the aim of achieving precise keypoint localization. RSN achieves state-of-the-art results when measured against the COCO and MPII benchmarks.
#35: AlphaPose (RMPE)
AlphaPose, or Regional Multi-Person Pose Estimation (RMPE), is a machine learning model for human pose estimation. It’s more accurate when detecting human poses within bounding boxes, and the architecture of the algorithm is equally effective when applied to single and multi-person poses in images and videos.
#36: MediaPipe
MediaPipe is an open-source, cross-platform ML solution originally created by Google for live videos and streaming media. Google provides numerous in-depth use cases on the Google AI and Google Developers Blogs. MediaPipe was developed to more accurately track faces, eye movements, hands, poses, and other holistic human pose estimation tasks, with numerous real-world use cases.
#37: OpenPose
OpenPose is another popular bottom-up machine learning algorithm that’s used to detect real-time multi-person poses for tracking and estimation purposes. It’s widely used through an API that can be integrated with CCTV footage, making it ideal for law enforcement, security services, counter-terrorism, and police investigations.
#38: PACS
PACS (Picture Archiving and Communication System) is a widely used medical imaging format in the healthcare sector, often used by doctors and specialists, alongside DICOM and NIfTI files. Images in the PACS format usually come from X-ray machines and MRI scanners.
PACS is a medical image, storage, and archiving format, and PACS images include layers of valuable metadata that radiologists and other medical specialists use when assessing what patients need and the various healthcare plans and treatment available to them. Like other medical image formats, PACS files can be annotated and fed into computer vision models for more detailed analysis.
#39: Native Formatting
Native formatting is a way of ensuring computer vision models and tools don’t need to adjust videos and images for the annotation tools being used. When videos can maintain a native format it avoids potential issues around ghost frames, variable frame rates, or needing to cut videos into segments for annotation and analysis.
And there we go, we’ve covered 39 of the most widely used terms in computer vision projects. We hope you’ve found this useful!
Ready to automate and improve the quality of your data labeling?
Sign-up for an Encord Free Trial: The Active Learning Platform for Computer Vision, used by the world’s leading computer vision teams.
AI-assisted labeling, model training & diagnostics, find & fix dataset errors and biases, all in one collaborative active learning platform, to get to production AI faster. Try Encord for Free Today.
Want to stay updated?
Follow us on Twitter and LinkedIn for more content on computer vision, training data, and active learning.
Join our Discord channel to chat and connect.
Frequently asked questions
Encord offers a comprehensive suite of features tailored for computer vision projects, including advanced labeling tools, quality assurance mechanisms, and integration capabilities with popular machine learning frameworks. These features facilitate seamless collaboration among teams, ensuring that projects are completed efficiently and effectively.
Encord stands out with its advanced features, such as support for simultaneous annotation across multiple images and alignment of color and infrared images. This capability allows users to gain a comprehensive view of their data and make informed decisions during the annotation process, which is not commonly found in other tools.
Encord provides a comprehensive platform that simplifies the integration of hardware and software components in computer vision applications. This streamlines the data collection and processing workflow, enabling teams to focus on optimizing their models without the complexities of hardware-software integration.
Encord supports various types of annotations for computer vision projects, including bounding boxes, tracking, and behavior-related annotations using transformer and clip-based technologies. The platform is designed to handle both image and video data, allowing teams to efficiently label and train their models.
Encord supports various types of annotations for video data, including bounding boxes, polygons, and segmentation masks. This flexibility allows users to choose the most effective method for their specific analysis needs, whether it's for animal tracking or other applications.
Encord addresses the challenges of managing video throughput by offering streamlined workflows and efficient annotation processes. This ensures that teams can handle large volumes of video data effectively, facilitating faster project completion and better model development.
Encord supports automated annotation through computer vision technology while also facilitating human annotation for cases that require nuanced understanding. This dual approach ensures comprehensive coverage of different data types and enhances overall model accuracy.
Yes, Encord can handle video data for annotation, enabling users to annotate frames in sequence and utilize tracking features. This method contrasts with traditional image-by-image annotation, offering a more efficient workflow by allowing batch processing of frames.
Encord is utilized by a variety of companies, particularly those involved in multimodal projects, such as translation services, dubbing, and AI development. The platform is particularly beneficial for teams looking to streamline data management and annotation tasks.
Encord offers advanced annotation tools specifically designed for video data, allowing for precise labeling and segmentation. This functionality is critical for developing computer vision applications, especially in dynamic environments where accuracy is essential.