Grok-1.5 Vision: First Multimodal Model from Elon Musk’s xAI

With its Grok series, Elon Musk's artificial intelligence laboratory X.ai has consistently pushed the limits of large language models (LLMs). Grok-1 was released with a window size of an impressive 128,000 tokens (larger than many other LLMs) with a Mixture of Expert (MoE) architecture.
Grok-1.5V builds on top of it. This new multimodal model expands the capabilities of traditional text-based LLMs to encompass visual understanding. It interprets language and can process various image types, making breakthroughs in complex reasoning tasks.
The model combines linguistic skills with the ability to analyze and interpret diverse visual inputs, such as documents, diagrams, and photographs.
Grok-1.5V is a move towards AI systems that can interact in a way that connects the physical and digital worlds, closely resembling human perception.
Let’s learn all about it in this deep-dive explainer!
Short on time? No worries, we have a TL;DR.
- Grok-1.5V is a new AI model from X.ai that can understand both text and images.
- It can answer your questions about pictures, analyze documents, and even understand real-world spatial relationships.
- This is a big leap forward for AI, but there are ethical concerns to consider, like bias and misinformation.
- Overall, Grok-1.5V is a promising step towards more versatile and powerful AI tools.
Grok-1.5 Vision: Capabilities
Grok-1.5V builds upon the strong language foundation of Grok-1, extending its abilities with visual understanding. Let's cover some of its key capabilities:
Grok-1.5V: Processing Visual Information
One of the most remarkable features of Grok-1.5V is its ability to process and understand a wide range of visual information. This includes:
- Documents: Analyzing complex documents, understanding diagrams, and extracting key information from tables and charts.
- Screenshots: Interpreting user interface elements or code snippets within screenshots.
- Photographs: Understanding the content and relationships between objects within photographs.
This opens up a world of possibilities for applications that require advanced visual understanding, such as document analysis, image captioning, and object recognition.
Grok-1.5V's visual processing prowess is not limited to static images. The model can also handle dynamic visual content, such as videos and animations, for tasks like video analysis, action recognition, and scene understanding.
This makes Grok-1.5V useful in fields like entertainment, security, and surveillance.

Grok-1.5V: Multi-disciplinary Reasoning
Another key strength of Grok-1.5V is its ability to perform multi-disciplinary reasoning. The model can draw insights from various domains, combining visual and textual information to arrive at complex conclusions. For example, Grok-1.5V could:
- Answer questions about scientific diagrams, combining your knowledge of scientific concepts with visual diagram analysis.
- Follow instructions, including text and images, enabling more complex task execution.
This is particularly valuable in medical imaging, where the model can analyze medical scans and patient records to provide comprehensive diagnostic insights.
Grok-1.5V's multi-disciplinary reasoning also extends to tasks that require creative problem-solving.
For instance, the model can generate code from hand-drawn sketches, bridging the gap between the visual and programming domains. This is exciting for intuitive programming interfaces and rapid prototyping.
Grok-1.5 V: Real-world Spatial Understanding
One of Grok-1.5V's most significant advancements is its ability to understand and reason about spatial relationships within the physical world. X.ai has introduced the RealWorldQA benchmark specifically to measure this capability.

The benchmark comprises over 760 image-based questions and answers that challenge AI models to understand and interact with the physical world.
Grok-1.5V's strong performance on this benchmark indicates its potential for applications involving:
- Robotics and Navigation
- Augmented Reality
- Visual Question Answering in real-world settings
Grok-1.5V's spatial understanding also extends to tasks that require common-sense reasoning. For example, the model can provide home maintenance advice based on images of household problems, showcasing its ability to apply real-world knowledge to practical situations.
Model Evaluation Performance Benchmarking Across Grok-1.5V, GPT-4V, Claude 3 Sonnet, Claude 3 Opus, and Gemini Pro 1.5
To truly appreciate Grok-1.5V's capabilities, it is essential to compare its performance against other leading AI models. In this section, we will examine how Grok-1.5V compares against GPT-4V, Claude 3 Sonnet, Claude 3 Opus, and Gemini Pro 1.5 across various benchmarks that assess different aspects of visual and multimodal understanding.
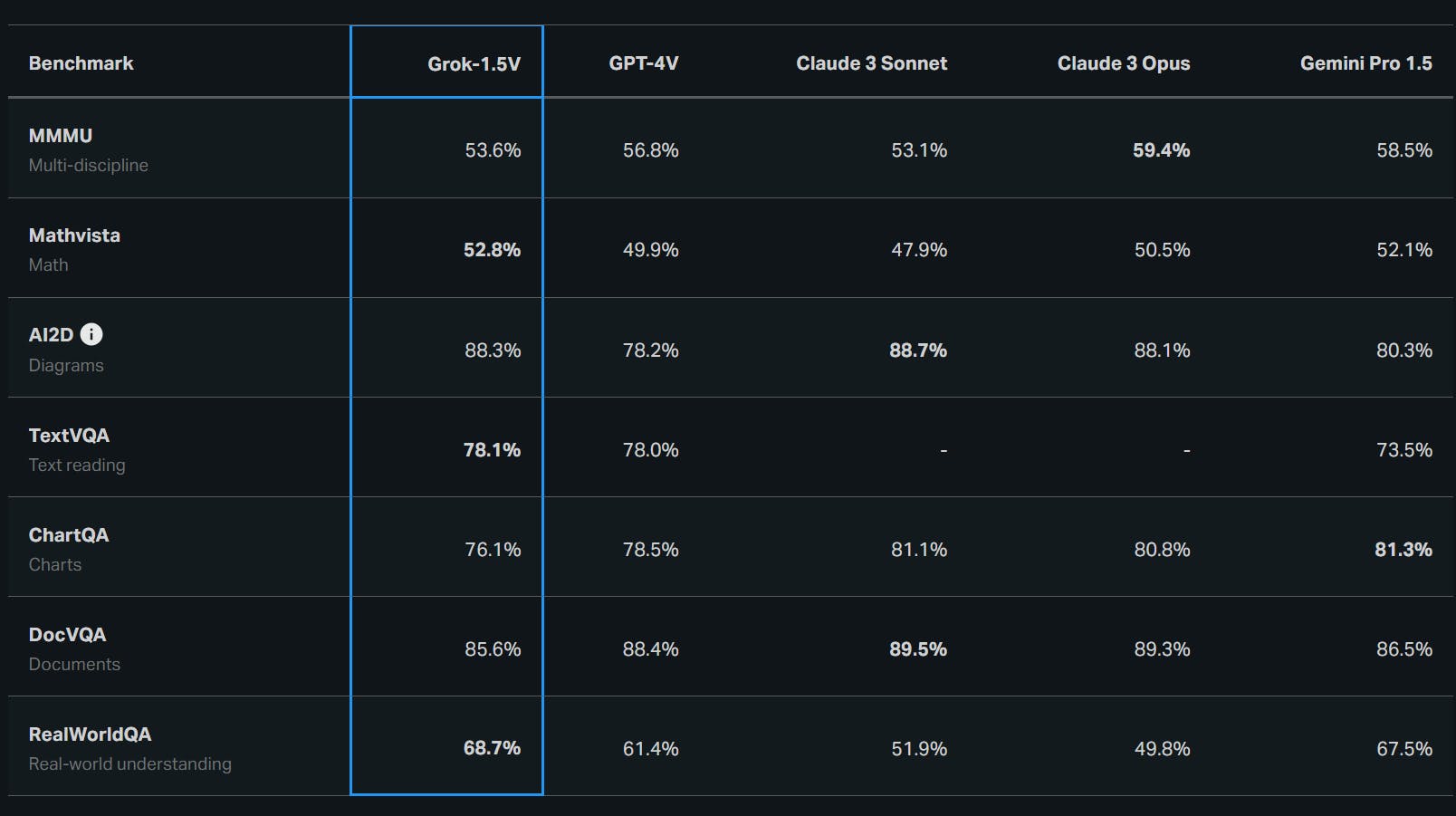
MMU: Multi-discipline Benchmark
The Multi-discipline Benchmark (MMU) evaluates an AI model's reasoning ability across multiple domains, combining visual and textual information to solve complex problems. Grok-1.5V outperforms its competitors in this benchmark with superior multi-disciplinary reasoning capabilities.
Mathvista: Math Benchmark
The Mathvista benchmark assesses an AI model's mathematical reasoning abilities, focusing on tasks like equation solving, graph interpretation, and geometric reasoning.
Grok-1.5V performs exceptionally well on this benchmark, which shows proficiency in understanding and manipulating mathematical concepts. It can interpret mathematical notation and apply relevant principles to solve problems.
AI2D: Diagram Understanding Benchmark
The AI2D benchmark for visual question-answering evaluates an AI model's ability to understand and interpret diagrams, flowcharts, and other visual representations of information. Grok-1.5V excels in this benchmark; it can extract meaningful insights from complex visual structures.
TextVQA: Text Reading Benchmark
The TextVQA benchmark assesses an AI model's ability to read and comprehend text within images, such as signs, labels, and captions. Grok-1.5V excels at OCR and contextual understanding on this benchmark. The model's ability to extract and interpret textual information from images opens up possibilities for applications in document analysis, accessibility, and language translation.
ChartQA: Charts Interpreting Benchmark
The ChartQA benchmark evaluates an AI model's ability to understand and interpret various charts, including bar graphs, line graphs, and pie charts. Grok-1.5V outperforms its competitors on this benchmark, showcasing its ability to extract insights from visual data representations.
The model's performance on ChartQA highlights its potential for applications in data analysis, business intelligence, and financial forecasting.
DocVQA: Documents Rendering Benchmark
The DocVQA benchmark assesses a model's ability to understand and interpret structured documents, such as forms, invoices, and reports. Grok-1.5V does very well on this benchmark, showing how well it understands documents and extracts information.
The model's performance on DocVQA positions it as a valuable tool for automating document processing tasks in various industries, including healthcare, finance, and legal services.
RealWorldQA: Real-world Understanding Benchmark
The RealWorldQA benchmark, introduced alongside Grok-1.5V, evaluates an AI model's ability to understand and interact with the physical world. Because Grok-1.5V did so well on this benchmark, it shows how advanced its spatial reasoning and real-world understanding skills are.
Grok-1.5V: Model Availability
Currently, Grok-1.5V is in a preview stage and accessible to a limited group of early testers. This includes existing Grok users and subscribers to X.ai's Premium+ service. This phased rollout allows X.ai to gather valuable feedback, fine-tune the model, and ensure responsible deployment.
Here are ways to potentially gain access to Grok-1.5V:
- Existing Grok Users: If you're already using Grok's language modeling capabilities, keep an eye out for announcements from X.ai regarding the Grok-1.5V rollout.
- X.ai Premium+ Subscribers: Consider subscribing to X.ai's premium service, which may provide early access to Grok-1.5V.
- Developer Community: Stay engaged with X.ai's developer community and online forums for future updates on the broader public availability of Grok-1.5V.
X.ai has not yet released a specific timeline for wider public access to Grok-1.5V. However, they will likely gradually increase the pool of users as the model matures and demonstrates robustness in diverse applications.
Grok-1.5 Vision: Ethical Concerns
As Grok-1.5V opens up new possibilities, moral concerns become the most important ones. Here are some key concerns to keep in mind:
Grok Chatbot Instructs Criminal Actions
Like any vision-language model (VLM), Grok-1.5V could be misused to generate harmful or unethical content, including instructions for criminal activities. X.ai must implement robust safety measures and content moderation to minimize such risks. This might involve:
- Thorough fine-tuning on datasets that promote safe and ethical behavior.
- Implementing filters to detect and block harmful text or image generation attempts.
- Providing clear guidelines and usage policies to users.
Spread of Misinformation and Disinformation
Grok-1.5V's ability to generate realistic responses and visual understanding could make it a tool for creating deceptive content ("deepfakes"). Proactive misinformation detection strategies and educating users about responsible use are essential.
Biases in the Training Data
Large-scale models are often trained on massive datasets that may reflect societal unconscious biases. Such biases can perpetuate harmful stereotypes or discriminatory behavior. Mitigating this requires:
- Careful curation and analysis of Grok-1.5V's training data.
- Transparent reporting of any identified biases or limitations.
- Ongoing bias monitoring and evaluation, even after deployment.
- See Also: Data Curation in Computer Vision.
Unintended Consequences
While Grok-1.5V has the potential for many positive applications, it's important to anticipate potential negative consequences. For example, misuse of surveillance or manipulating public opinion could have serious societal ramifications.
Addressing these ethical concerns requires an ongoing dialogue between X.ai, the AI community, and the broader public. X.ai's commitment to transparency and responsible AI development will be essential in building trust and ensuring that Grok-1.5V serves as a tool for good.
Grok-1.5 Vision: What's Next?
X.ai's release of Grok-1.5V signals a promising shift towards more versatile and comprehensive AI models. Here's what we might anticipate soon:
Advancements in Understanding and Multimodal Capabilities
Expect improvements in how Grok-1.5V processes and integrates information across different modalities. This could include:
- Understanding Video: Going beyond images to analyze video content for richer insights.
- Audio Integration: Enabling models to understand and respond to speech and other audio inputs.
- Enhanced Reasoning: Developing even more sophisticated reasoning abilities across text, images, and other modalities.
Grok-1.5V: Building Beneficial AGI (Artificial General Intelligence)
X.ai has expressed a long-term goal of developing beneficial Artificial General Intelligence. Grok-1.5V is a crucial step in that direction. We can expect its multimodal capabilities to contribute towards models that exhibit:
- Adaptability: AGI should be able to tackle a wide range of tasks and learn new skills quickly. Multimodal models train on more diverse data for adaptability.
- Common Sense: Integrating real-world spatial understanding into language models is essential for developing AI with common sense reasoning capabilities.
- Safety and Alignment: Future iterations will likely focus on ensuring AGI is aligned with human values and operates safely within our world.
Even though Grok 1.5-V is a big deal, the road to real AGI is still a long way off. Grok-1.5V serves as an example of the advancements made in multimodal AI, which pave the way for increasingly intelligent systems that can perceive, comprehend, and interact with the world in previously unthinkable ways.
Grok-1.5 Vision: Key Takeaways
Grok-1.5 Vision (Grok-1.5V) from X.ai is a big step forward in developing vision-language models. By introducing multimodal capabilities, Grok-1.5V can process and understand information from text and images, documents, and other visual formats. This opens doors for various applications, including document analysis, real-world question answering, and potentially even creative tasks.
Grok-1.5V's performance on various benchmarks showcases its strengths, particularly in spatial reasoning and diagram understanding. While the model is in a preview stage, X.ai's commitment to responsible AI development gives hope for a future where Grok-1.5V and similar models are utilized ethically and safely.
The potential for advancements in understanding and the path toward building beneficial AGI makes Grok-1.5V a development to watch closely as the field of AI continues to evolve.
Frequently asked questions
Grok-1.5v is a cutting-edge AI model from X.ai that can understand and generate responses based on both text and images. It extends the capabilities of traditional text-only language models for a wider range of applications.
Currently, Grok-1.5v is in a preview stage with access primarily for existing Grok users and those on X.ai's Premium+ service. It might become more widely available in the future.
It depends. If you're already a Grok user or an X.ai Premium+ subscriber, you might have access to the model. Check for updates from X.ai about Grok-1.5v availability.
- Multimodal Understanding: Processes both language and visual data (images, diagrams, etc.).
- Document Analysis: Extracts information, interprets charts, and summarizes documents.
- Real-world Spatial Understanding: Excels in tasks requiring spatial reasoning about the physical world.
Based on benchmark results, Grok-1.5v demonstrates stronger performance in certain areas of visual understanding, particularly spatial reasoning and understanding scientific diagrams. However, comparing performance across various tasks is important to get a complete picture.
Encord provides native support for 16-bit multiple bands, allowing users to annotate satellite imagery without needing to convert images to lower bit depths. This feature streamlines the workflow and eliminates the need for pre-processing that can complicate the annotation process.