Training, Validation, Test Split for Machine Learning Datasets

Product Manager at Encord
Properly splitting your machine learning datasets into training, validation, and test sets is essential for building robust and accurate models. This guide explores the differences between these sets, highlights three effective splitting methods, identifies common mistakes to avoid, and explains how to use Encord for managing dataset splits in computer vision projects.
The train-validation-test split is fundamental to the development of robust and reliable machine learning models.
Put very simply:
- The goal: Create a neural network that generalizes well to new data
- The motto: Never train that model on test data
The premise is intuitive – avoid employing the same dataset to train your machine learning model that you use to evaluate it. Doing so will result in a biased model that reports an artificially high model accuracy against the dataset it was trained on and poor model accuracy against any other dataset.
To ensure the generalizability of your machine learning algorithm, it is crucial to split the dataset into three segments: the training set, validation set, and test set. This will allow you to realistically measure your model’s performance by ensuring that the dataset used to train the model and the dataset used to evaluate it are distinct.
In this article, we outline:
- Training Set vs. Validation Set vs. Test Sets
- 3 Methods to Split Machine Learning Datasets
- 3 Mistakes to Avoid When Splitting Machine Learning Datasets
- How to use Encord for Training, Validation, and Test Splits in Computer Vision
- Key Takeaways

Training vs. Validation vs. Test Sets
Before we dive into the best practices of the train-validation-test split for machine learning models, let’s define the three sets of data.
Training Set
The training set is the portion of the dataset reserved to fit the model. In other words, the model sees and learns from the data in the training set to directly improve its parameters.
To maximize model performance, the training set must be (i) large enough to yield meaningful results (but not too large that the model overfits) and (ii) representative of the dataset as a whole. This will allow the trained model to predict any unseen data that may appear in the future.
Overfitting occurs when a machine learning model is too specialized and adapted to the training data that it is unable to generalize and make correct predictions on new data. As a result, an overfit model will overperform with the training set but underperform when presented with validation sets and test sets.
 💡 Encord pioneered the micro model methodology, which capitalizes on overfitting machine learning models on narrowly defined tasks to be applied across entire datasets once model accuracy is high. Learn more about micro models in An Introduction to Micro-Models for Labeling Images and Videos
💡 Encord pioneered the micro model methodology, which capitalizes on overfitting machine learning models on narrowly defined tasks to be applied across entire datasets once model accuracy is high. Learn more about micro models in An Introduction to Micro-Models for Labeling Images and Videos Validation Set
The validation set is the set of data used to evaluate and fine-tune a machine learning model during training, helping to assess the model’s performance and make adjustments.
By evaluating a trained model on the validation set, we gain insights into its ability to generalize to unseen data. This assessment helps identify potential issues such as overfitting, which can have a significant impact on the model’s performance in real-world scenarios.
The validation set is also essential for hyperparameter tuning. Hyperparameters are settings that control the behavior of the model, such as learning rate or regularization strength. By experimenting with different hyperparameter values, training the model on the training set, and evaluating its performance with the validation set, we can identify the optimal combination of hyperparameters that yields the best results. This iterative process fine-tunes the model and maximizes its performance.
Test Set
The test set is the set of data used to evaluate the final performance of a trained model.
It serves as an unbiased measure of how well the model generalizes to unseen data, assessing its generalization capabilities in real-world scenarios. By keeping the test set separate throughout the development process, we obtain a reliable benchmark of the model’s performance.
The test dataset also helps gauge the trained model's ability to handle new data. Since it represents unseen data that the model has never encountered before, evaluating the model fit on the test set provides an unbiased metric into its practical applicability. This assessment enables us to determine if the trained model has successfully learned relevant patterns and can make accurate predictions beyond the training and validation contexts.
3 Methods to Split Machine Learning Datasets
There are various methods of splitting datasets for machine learning models. The right approach for data splitting and the optimal split ratio both depend on several factors, including the use case, amount of data, quality of data, and the number of hyperparameters.
Random Sampling
The most common approach for dividing a dataset is random sampling. As the name suggests, the method involves shuffling the dataset and randomly assigning samples to training, validation, or test sets according to predetermined ratios. With class-balanced datasets, random sampling ensures the split is unbiased.
While random sampling is the best approach for many ML problems, it is not the correct approach with imbalanced datasets. When the data consists of skewed class proportions, random sampling will almost certainly create a bias in the model.
Stratified Dataset Splitting
Stratified dataset splitting is a method commonly used with imbalanced datasets, where certain classes or categories have significantly fewer instances than others. In such cases, it is crucial to ensure that the training, validation, and test sets adequately represent the class distribution to avoid bias in the final model.
In stratified splitting, the dataset is divided while preserving the relative proportions of each class across the splits. As a result, the training, validation, and test sets contain a representative subset from each class, maintaining the original class distribution. By doing so, the model can learn to recognize patterns and make predictions for all classes, resulting in a more robust and reliable machine learning algorithm.
Cross-Validation Splitting
Cross-validation sampling is a technique used to split a dataset into training and validation sets for cross-validation purposes. It involves creating multiple subsets of the data, each serving as a training set or validation set during different iterations of the cross-validation process.
K-fold cross-validation and stratified k-fold cross-validation are common techniques. By utilizing these cross-validation sampling techniques, researchers and machine learning practitioners can obtain more reliable and unbiased performance metrics for their machine learning models, enabling them to make better-informed decisions during model development and selection.
3 Mistakes to Avoid When Data Splitting
There are some common pitfalls that data scientists and ML engineers make when splitting datasets for model training.
Inadequate Sample Size
Insufficient sample size in the training, validation, or test sets can lead to unreliable model performance metrics. If the training set is too small, the model may not capture enough patterns or generalize well. Similarly, if the validation set or test set is too small, the performance evaluation may lack statistical significance.
Data Leakage
Data leakage occurs when information from the validation set or test set inadvertently leaks into the training set. This can lead to overly optimistic performance metrics and an inflated sense of the final model accuracy. To prevent data leakage, it is crucial to ensure strict separation between the training set, validation set, and test set, making sure that no information from the evaluation sets are used during model training.
Improper Shuffle or Sorting
Incorrectly shuffling or sorting the data before splitting can introduce bias and affect the generalization of the final model. For example, if the dataset is not shuffled randomly before splitting into training set and validation set, it may introduce biases or patterns that the model can exploit during training. As a result, the trained model may overfit to those specific patterns and fail to generalize well to new, unseen data.
How to use Encord for Training, Validation, and Test Splits
To get started with a machine learning project, Encord’s platform can be used for data splitting. Encord Index enhances this process by providing powerful tools for managing and curating your datasets.
With Encord Index, you can efficiently organize and visualize your data, ensuring accurate and balanced training, validation, and test splits. This streamlined process helps maintain data integrity and improves model performance, allowing for effective and realistic evaluation of your machine learning models.
To split the dataset you can download Encord Active, run the following commands in your preferred Python environment:
python3.9 -m venv ea-venv source ea-venv/bin/activate # within venv pip install encord-active
Alternatively, run the following command to install Encord Active using GitHub:
pip install git+https://github.com/encord-team/encord-active
To confirm Encord Active has been installed, run the following:
encord-active --help
Encord Active has many sandbox datasets like the COCO, Rareplanes, BDD100K, TACO dataset and many more. These sandbox datasets are commonly used in computer vision applications for building benchmark models.
Now that Encord Active has been installed, download the COCO dataset with the following command:
encord-active download
The script prompts you to choose a project, navigate the options ↓ and ↑ select the COCO dataset, and hit enter. The COCO dataset referred to here is the same COCO validation dataset mentioned in the COCO webpage. This dataset is used to demonstrate how Encord Active can filter and split the dataset easily.
In order to visualize the data in the browser, run the following command:
cd /path/to/downloaded/project encord-active visualize
The image displayed below is the webpage that opens in your browser, showcasing the data and its properties. Let’s examine the properties:
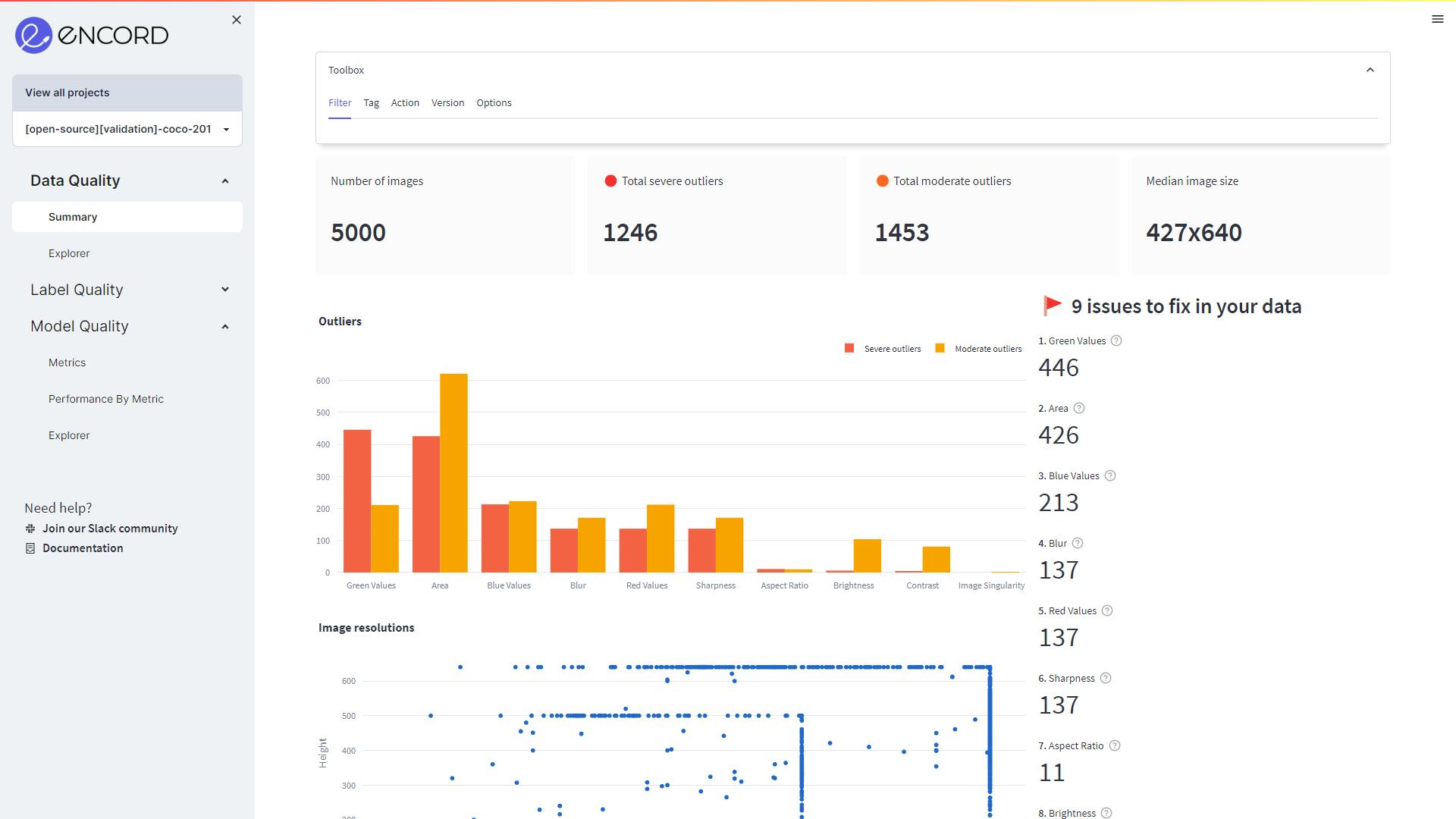
Visualize the data in your browser (data = COCO dataset)
The COCO dataset comprises 5000 images, of which we have allocated 3500 images for the training set, 1000 images for the validation set, and 500 images for the test set.
The filter can be used to select images based on their features, ensuring the subsets of data are balanced.
As illustrated below, in Data Quality→Explorer, use the features to filter out images.
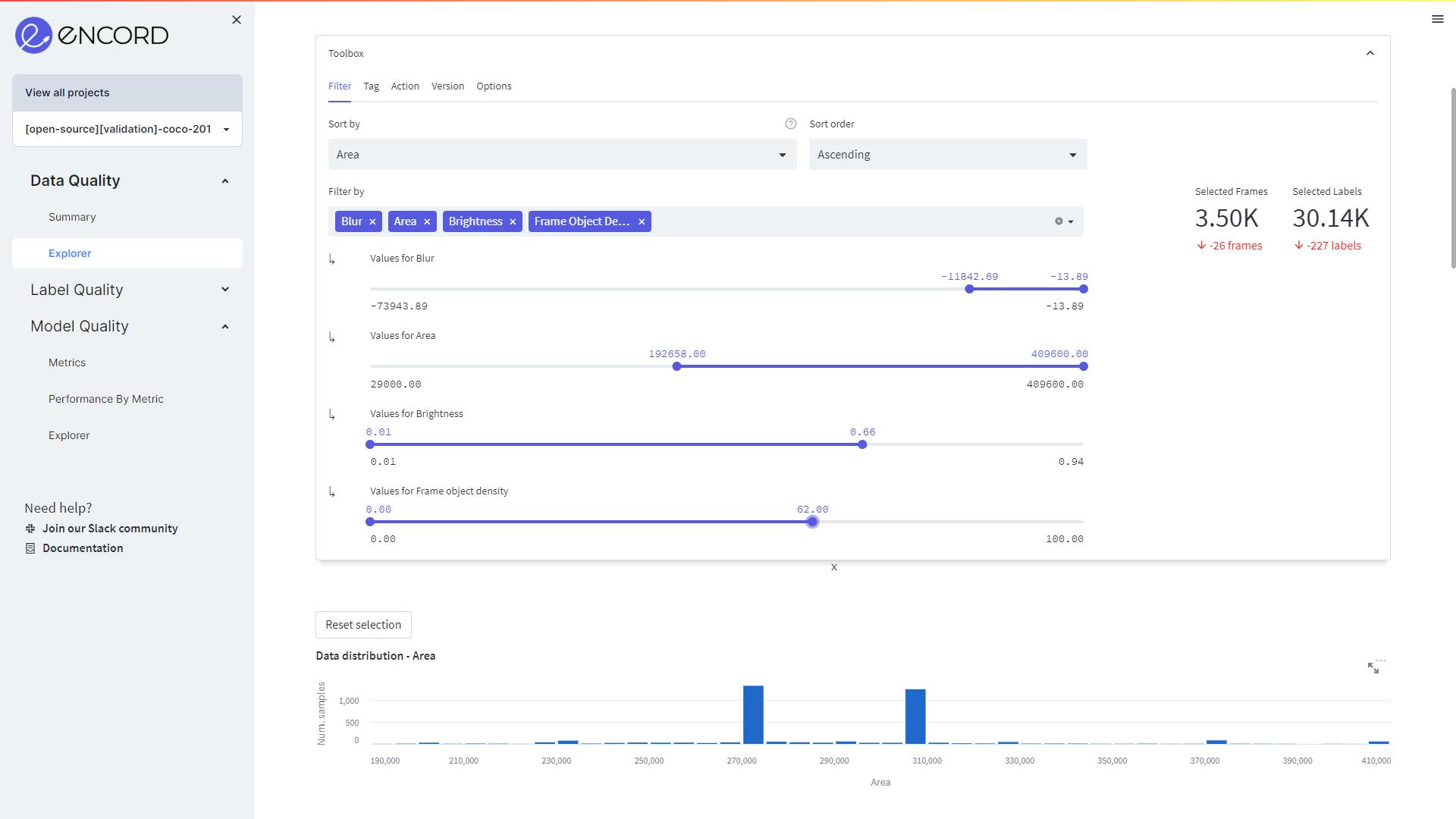
Filtering the dataset based on Blur, Area, Brightness, and Frame object density values for the training set
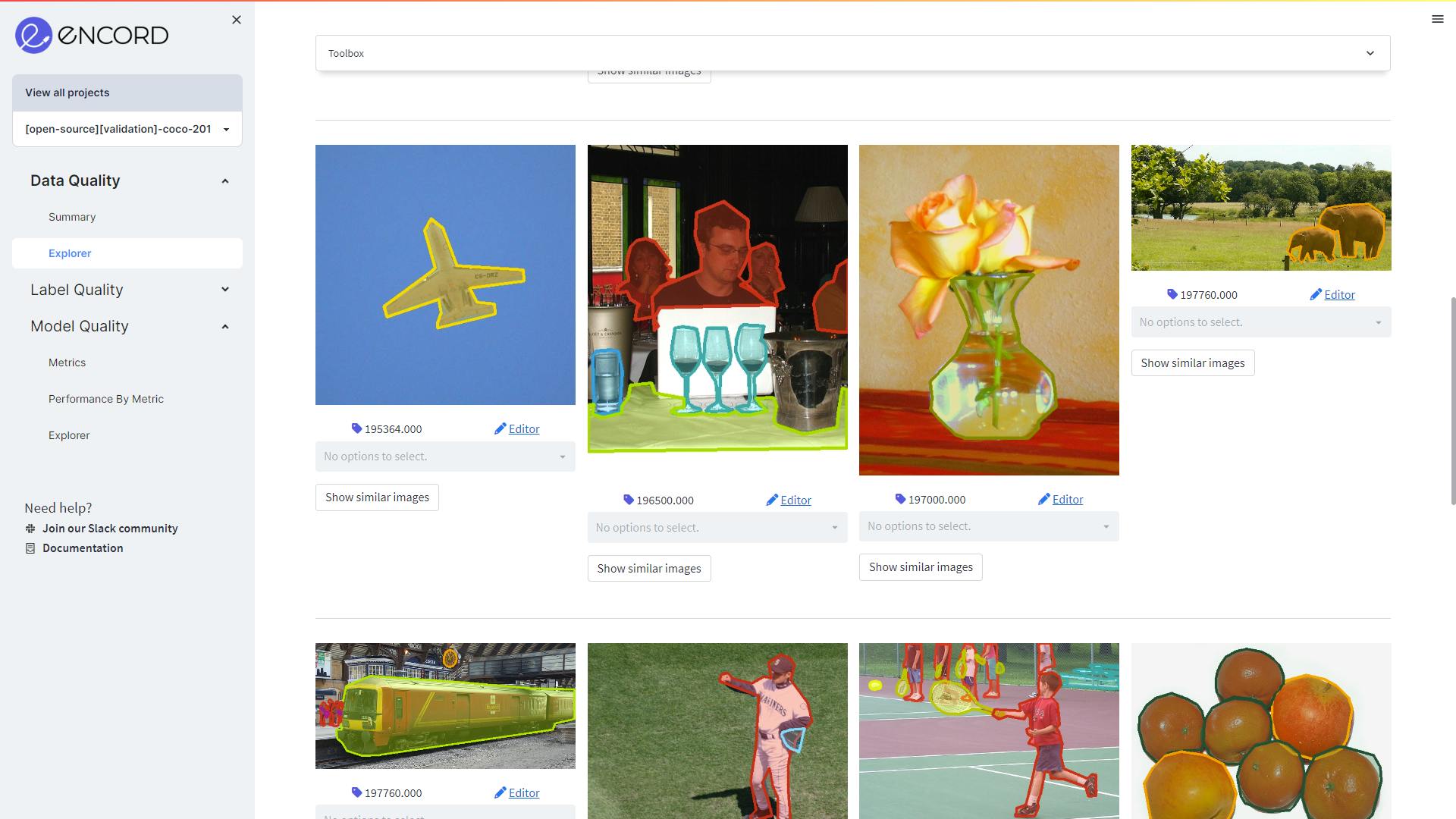
Example of images in the training set
Through the Action tab in the Toolbox, click on Create Subset to create a new training subset. You can either download the subset in CSV or COCO format, or use it in the Encord Platform to train and evaluate your machine learning model.
Similar to the training subset, create a validation set and test set. Remember to choose the same features but filter by different values to avoid data leakage.
Check out our curated lists of open-source datasets for various sectors, including Top 10 Free Healthcare Datasets for Computer Vision, Top 8 Free Datasets for Human Pose Estimation in Computer Vision, and Best Datasets for Computer Vision | Industry Breakdown. Training, Validation, and Test Set: Key Takeaways
Here are the key takeaways:
- In order to create a model that generalizes well to new data, it is important to split data into training, validation, and test sets to prevent evaluating the model on the same data used to train it.
- The training set data must be large enough to capture variability in the data but not so large that the model overfits the training data.
- The optimal split ratio depends on various factors. The rough standard for train-validation-test splits is 60-80% training data, 10-20% validation data, and 10-20% test data.
Recommended Articles
- How to Build Your First Machine Learning Model
- The Full Guide to Training Datasets for Machine Learning
- Active Learning in Machine Learning [Guide & Strategies]
- Self-Supervised Learning Explained
- DINOv2: Self-supervised Learning Model Explained
- 4 Questions to Ask When Evaluating Training Data Pipelines
- How to Automate the Assessment of Training Data Quality
- 5 Ways to Reduce Bias in Computer Vision Datasets
- 9 Ways to Balance Your Computer Vision Dataset
- How to Improve Datasets for Computer Vision
- How to Automate Data Labeling [Examples + Tutorial]
- The Complete Guide to Object Tracking [Tutorial]
Frequently asked questions
The train-test split is a technique in machine learning where a dataset is divided into two subsets: the training set and test set. The training set is used to train the model, while the test set is used to evaluate the final model’s performance and generalization capabilities.
The validation set provides an unbiased assessment of the model’s performance on unseen data before finalizing. It helps in fine-tuning the model’s hyperparameters, selecting the best model, and preventing overfitting.
It is important to split your data into a training set and test set to evaluate the model performance and generalizability ability of a machine learning algorithm. By using separate sets, you can simulate the model’s performance on unseen data, detect overfitting, optimize model parameters, and make informed decisions about its effectiveness before deployment.
Overfitting occurs when a machine learning model performs well on the training data but fails to generalize to new, unseen data. This occurs when the trained model learns noise or irrelevant patterns from the training set, leading to poor model performance on the test set or validation set.
Cross-validation is a technique used to evaluate the model performance and generalization capabilities of a machine learning algorithm. It involves dividing the dataset into multiple subsets or folds. The machine learning model is trained on a combination of these subsets while being tested on the remaining subset. This process is repeated, and performance metrics are averaged to assess model performance.
Evaluation metrics are quantitative measures used to assess the performance and quality of a machine learning model. They provide objective criteria to evaluate model performance on a given task. Common evaluation metrics include accuracy, precision, recall, F1 score, mean squared error, and area under the curve (AUC).
Encord includes provisions for creating train and test file splits, allowing users to manage their datasets effectively. This feature is useful for machine learning workflows, enabling users to prepare data for training and validation purposes.