Author
Akruti Acharya
Akruti is a data scientist and technical content writer with a M.Sc. in Machine Learning & Artificial Intelligence from the University of Birmingham. She enjoys exploring new things and applying her technical and analytical skills to solve challenging problems and sharing her knowledge and experience with her readers.

All blogs by Akruti Acharya
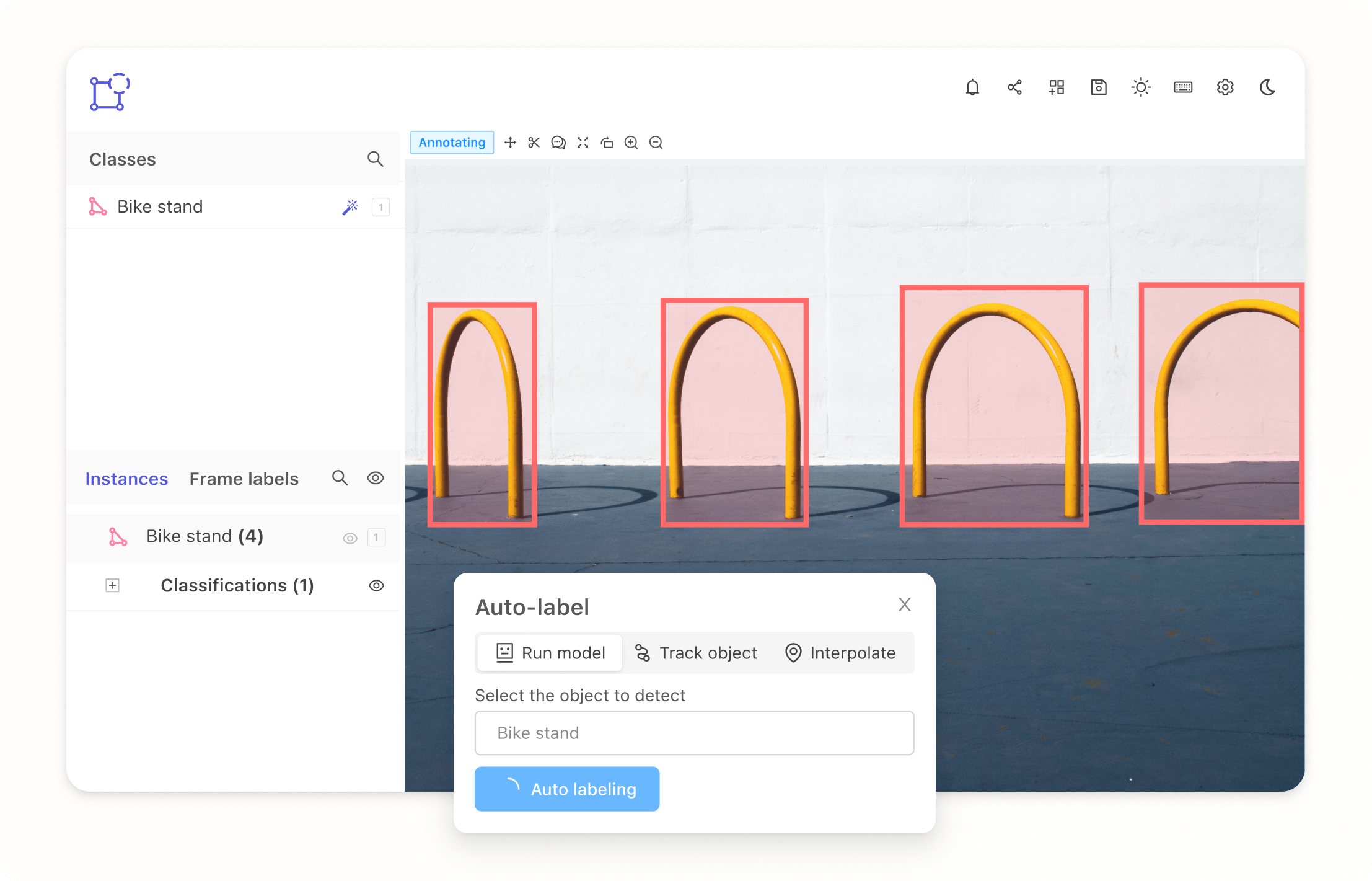
The Complete Guide to Image Annotation for Computer Vision
7 m

6 Steps to Build Better Computer Vision Models
12 m

CVPR 2024: Top Artificial Intelligence and Computer Vision Papers Accepted

How to Choose the Right Data for Your Computer Vision Project
12 m

Visual Foundation Models vs. State-of-the-Art: Exploring Zero-Shot Object Segmentation with Grounding-DINO and SAM

Top 10 Open Source Datasets for Machine Learning

TAPIR: Tracking Any Point with per-frame Initialization and temporal Refinement | Explained
The Complete Guide to Object Tracking [Tutorial]
15 m

What is Vector Similarity Search?
5 m

Object Classification with Caltech 101
7 m

Meta AI's CoTracker: It is Better to Track Together for Video Motion Prediction

Dual-Stream Diffusion Net for Text-to-Video Generation

Slicing Aided Hyper Inference (SAHI) for Small Object Detection | Explained

Tracking Everything Everywhere All at Once | Explained

Meta-Transformer: Framework for Multimodal Learning

MEGABYTE, Meta AI’s New Revolutionary Model Architecture, Explained

How To Detect Data Drift on Datasets

How to Build Your First Machine Learning Model
14 m

Exploring the RarePlanes Dataset

NVLM 1.0: NVIDIA's Open-Source Multimodal AI Model
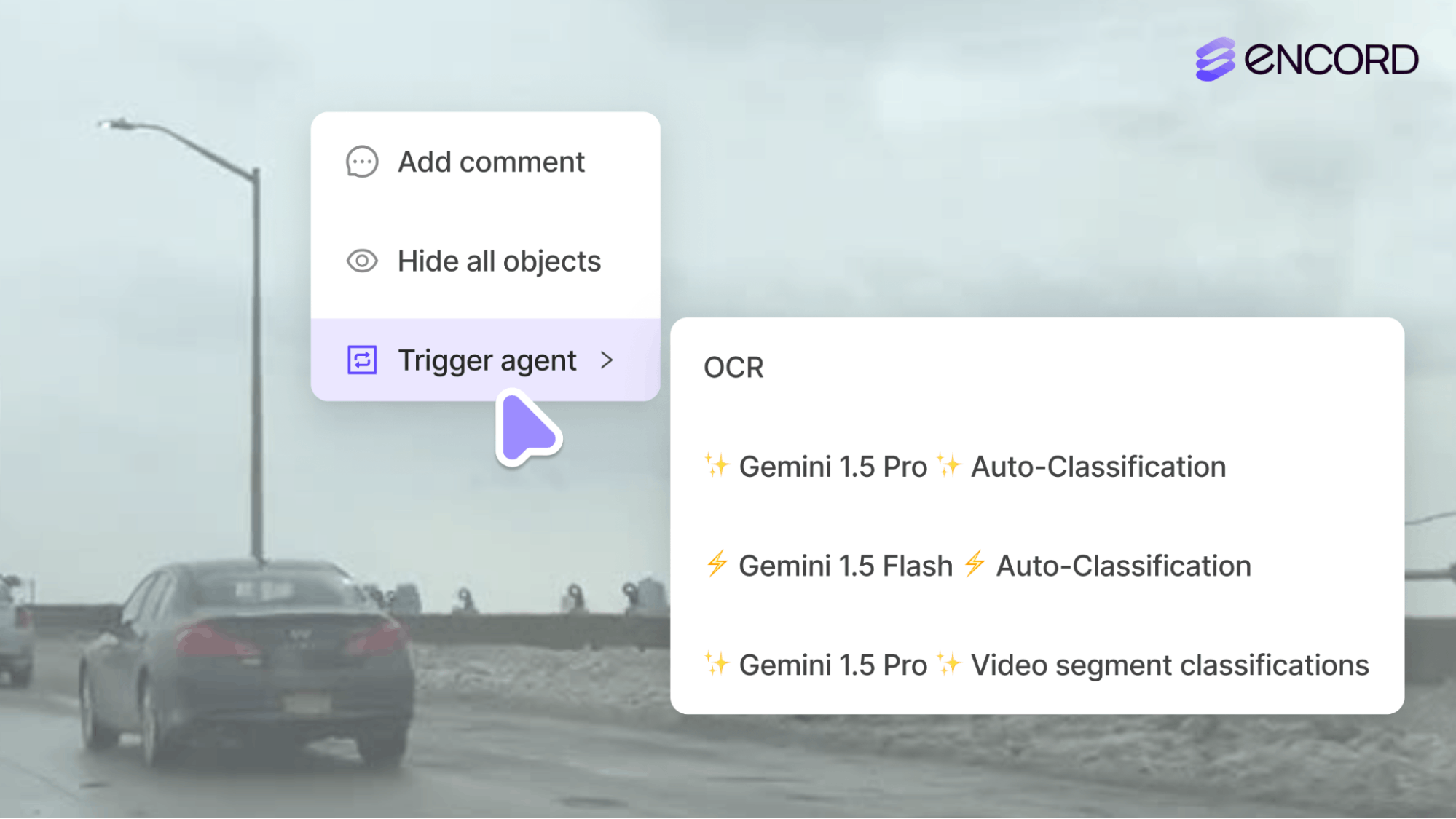
Automate Text Labeling for Your Image Dataset: A Step-by-Step Guide
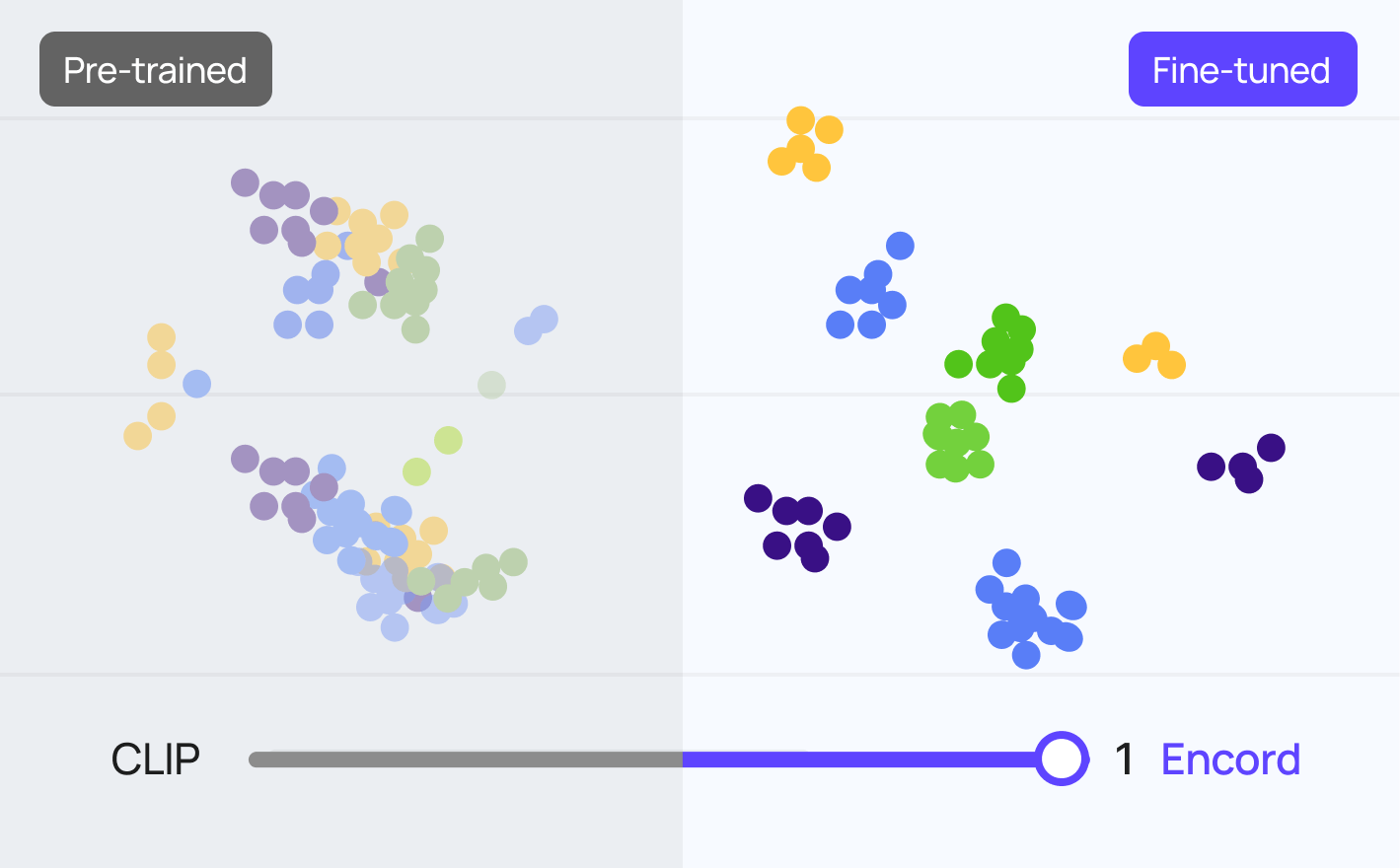
Fine-Tuning VLM: Enhancing Geo-Spatial Embeddings

How SAM 2 and Encord Transforms Video Annotation

FastViT: Hybrid Vision Transformer with Structural Reparameterization

Text2Cinemagraph: Synthesizing Artistic Cinemagraphs
Med-PaLM: Google Research’s Medical LLM | Explained

OpenAI o1: A New Era of AI Reasoning

Llama 2: Meta AI's Latest Open Source Large Language Model

Apple’s MM1.5 Explained

Vision Fine-Tuning with OpenAI's GPT-4: A Step-by-Step Guide
5 m
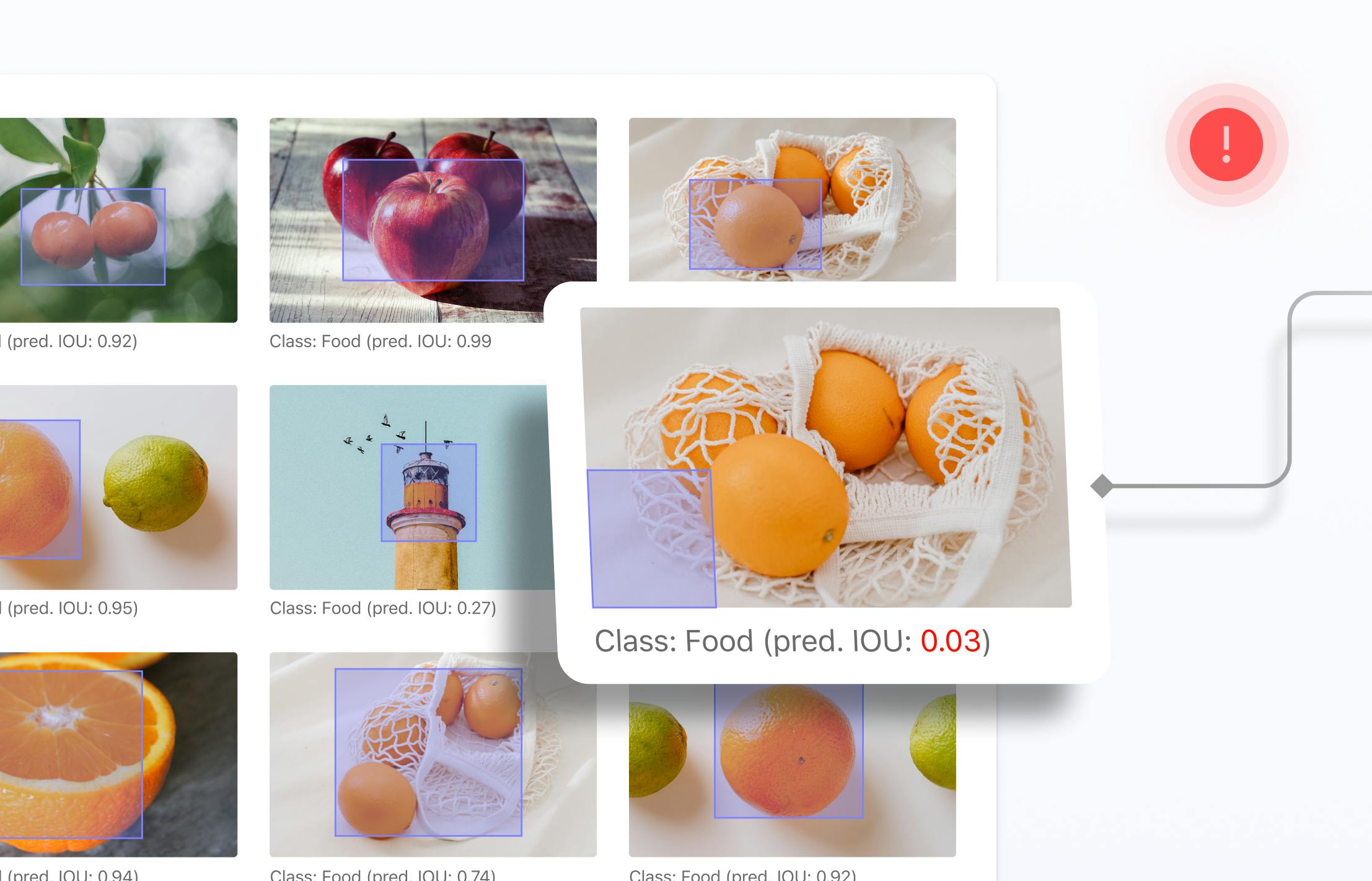
Improving Training Data with Outlier Detection
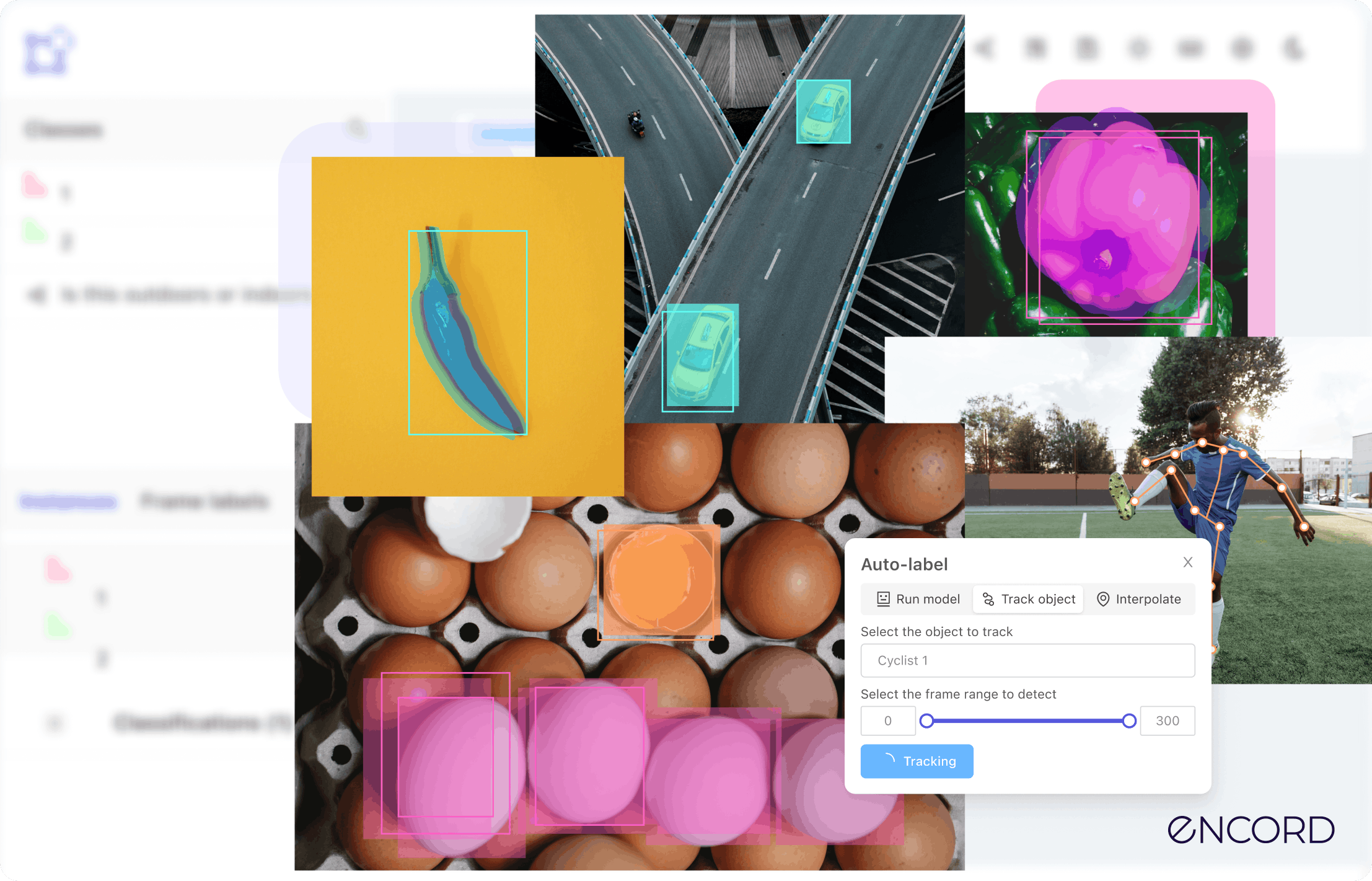
What is Data Labeling? The Ultimate Guide [2026]
8 m

How to use SAM to Automate Data Labeling in Encord
8 m
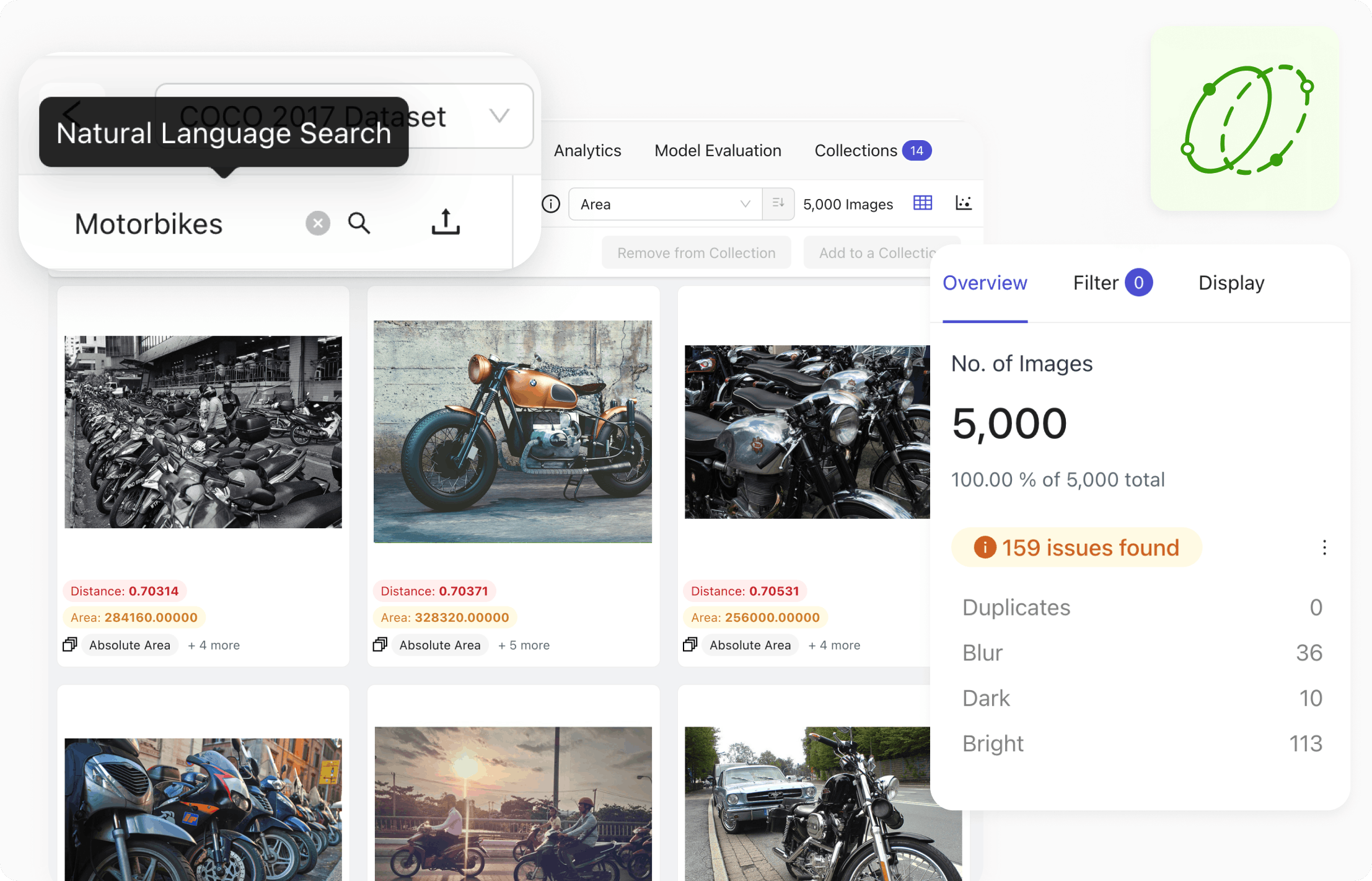
Improving Data Quality Using End-to-End Data Pre-Processing Techniques in Encord Active
10 m

How to Use GPT-4o for Model Development with Encord

Gemini Robotics: Advancing Physical AI with Vision-Language-Action Models

Ray-Ban Meta Smart Glasses are Getting an Upgrade with Multimodal AI
5 m

MiniGPT-v2 Explained

Segment Anything Model 2 (SAM 2) & SA-V Dataset from Meta AI

YOLOv9: SOTA Object Detection Model Explained
8 m

What to Expect From OpenAI’s GPT-Vision vs. Google’s Gemini
Florence-2: Microsoft's New Foundation Model Explained

How Poor Data is Killing Your Models and How to Fix It
Intralogistics: Optimizing Internal Supply Chains with Automation

Data Classification 101: Structuring the Building Blocks of Machine Learning

9 Ways to Balance Your Computer Vision Dataset
15 m

DINOv3 Explained: Scaling Self-Supervised Vision Transformers
Diffusion Transformer (DiT) Models: A Beginner’s Guide
8 m

Google Launches Gemini, Its New Multimodal AI Model

Comparative Analysis of YOLOv9 and YOLOv8 Using Custom Dataset on Encord Active
8 m

The Python Developer's Toolkit for PDF Processing
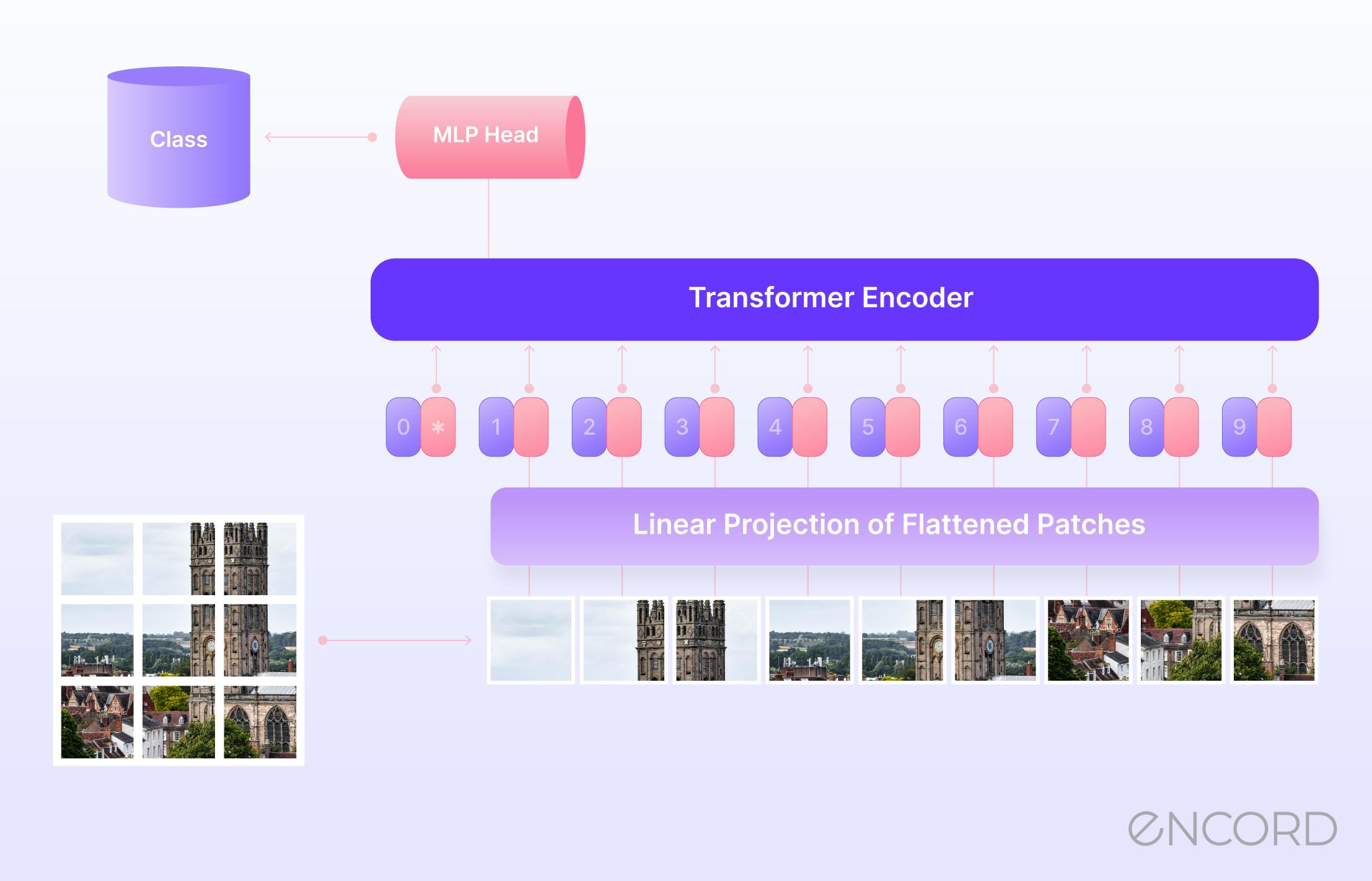
Introduction to Vision Transformers (ViT)

OpenAI Releases New Text-to-Video Model, Sora
3 m

Meta’s V-JEPA: Video Joint Embedding Predictive Architecture Explained
8 m

Meta AI’s I-JEPA, Image-based Joint-Embedding Predictive Architecture, Explained
10 m

Exploring GPT-4 Vision: First Impressions

Qwen-VL and Qwen-VL-Chat: Introduction to Alibaba’s AI Models
8 m

LLaVA, LLaVA-1.5, and LLaVA-NeXT(1.6) Explained

Meta’s Llama 3.1 Explained

GPT-4 Vision vs LLaVA

Instance Segmentation in Computer Vision: A Comprehensive Guide
7 m

Exploring Vision-based Robotic Arm Control with 6 Degrees of Freedom
8 m

Mistral Large Explained
5 m
Overfitting in Machine Learning: How to Detect and Avoid Overfitting in Computer Vision?
8 m

Phi-3: Microsoft’s Mini Language Model is Capable of Running on Your Phone
8 m

MM1: Apple’s Multimodal Large Language Models (MLLMs)
10 m

Stable Diffusion 3: Multimodal Diffusion Transformer Model Explained
10 m

YOLO World Zero-shot Object Detection Model Explained
10 m

Claude 3 | AI Model Suite: Introducing Opus, Sonnet, and Haiku
10 m

Apple Vision PRO - Extending Reality to Radiology
8 m
Mistral 7B: Mistral AI's Open Source Model